5 移动平均模型
5.1 移动平均模型的概念
移动平均模型是具有\(q\)步外不相关性质的平稳列的模型; 对于高阶的AR模型, 有些可以用低阶的MA模型更好地描述。 一般的AR模型也可以用高阶MA模型近似。
理论上,AR模型也可以是无穷阶的: \[ X_t = \phi_0 + \sum_{j=1}^\infty \phi_j X_{t-j} + \varepsilon_t . \] 其中\(\{ \phi_j \}\)应绝对可和。 一个特例为 \[ X_t = \phi_0 - \sum_{j=1}^\infty (-\theta_1)^j X_{t-j} + \varepsilon_t . \] 其中\(0 < |\theta| < 1\)。 将模型写成: \[ X_t + \sum_{j=1}^\infty (-\theta_1)^j X_{t-j} = \phi_0 + \varepsilon_t . \tag{*} \] 以\(t-1\)代入,并乘以\(-\theta_1\),有 \[ \sum_{j=1}^\infty (-\theta_1)^j X_{t-j} = -\phi_0 \theta_1 - \theta_1 \varepsilon_{t-1} . \] 代入到(*)式中得 \[ X_t = \phi_0(1+\theta_1) + \varepsilon_t + \theta_1 \varepsilon_{t-1} . \] 这样的模型称为MA(1)模型。
一般地,若\(\{ \varepsilon_t \}\)是零均值独立同分布白噪声, 方差为\(\sigma^2\),\(|\theta_1| < 1\), 令 \[ X_t = \theta_0 + \varepsilon_t + \theta_1 \varepsilon_{t-1} , \] 易见\(\{ X_t \}\)为线性时间序列形式的弱平稳列, 称为MA(1)序列。
类似地,MA(2)序列的模型为 \[ X_t = \theta_0 + \varepsilon_t + \theta_1 \varepsilon_{t-1} + \theta_2 \varepsilon_{t-2} . \]
MA(\(q\))序列的模型为 \[ X_t = \theta_0 + \varepsilon_t + \theta_1 \varepsilon_{t-1} + \dots + \theta_q \varepsilon_{t-q} . \] 此模型也有特征多项式 \[ 1 + \theta_1 z + \dots + \theta_q z^q . \] 特征方程的根称为特征根, 特征根都在单位圆外的条件称为MA模型的可逆条件。 平稳性并不需要特征根的条件。
上面从AR(\(\infty\))导出MA(1)的过程, 实际用了滞后算子的一些运算法则: 设\(P(z)=\sum_{j=0}^\infty \phi_j z^j\)和\(Q(z)=\sum_{j=0}^\infty \theta_j z^j\), \(\sum_{j=0}^\infty |\phi_j| < \infty\), \(\sum_{j=0}^\infty |\theta_j| < \infty\), 则 \[ P(z)Q(z) = R(z) = \sum_{j=0}^\infty r_j z^j , \] 其中 \[ r_j = \sum_{i=0}^j \phi_i \theta_{j-i}, \] 且对弱平稳列\(\{ \xi_t \}\)有 \[ P(B)Q(B) \xi_t = R(B) \xi_t . \]
详见(何书元 2003)§2.1,以及李东风“应用时间序列分析课堂演示”。
5.2 移动平均模型的性质
以MA(1)和MA(2)为例讨论MA序列的性质,一般MA(\(q\))序列类似讨论即可。
5.2.1 平稳性与自相关函数性质
以MA(1)为例。 \(X_t = \theta_0 + \varepsilon_t + \theta_1 \varepsilon_{t-1}\), 其中\(\{ \varepsilon_t \}\)是零均值独立同分布白噪声, \(\theta_0\), \(\theta_1\)是任意实数, 平稳性不需要特征根的条件。
易见 \[ E X_t = \theta_0, \ \forall t , \quad \text{Var}(X_t) = \sigma^2(1 + \theta_1^2) = \gamma_0 . \] 而 \[\begin{aligned} \gamma_1 =& E[(X_t - \theta_0)(X_{t-1}-\theta_0)] \\ =& E[(\varepsilon_t + \theta_1 \varepsilon_{t-1}) (\varepsilon_{t-1} + \theta_1 \varepsilon_{t-2})] \\ =& \theta_1 E \varepsilon_{t-1}^2 = \sigma^2 \theta_1 . \end{aligned}\] 对\(k > 1\)有 \[ \gamma_k = E[(\varepsilon_t + \theta_1 \varepsilon_{t-1}) (\varepsilon_{t-k} + \theta_1 \varepsilon_{t-k-1})] = 0 . \] 因为\(k>1\),所以\(t-k-1 < t-k < t-1 < t\), 求协方差时均不相关。
所以,对于MA(1)序列,有 \[ \gamma_k = \begin{cases} \sigma^2(1 + \theta_1^2), & k=0, \\ \sigma^2 \theta_1, & k=1, \\ 0, & k>1 . \end{cases} \] 相应地,MA(1)的自相关函数为 \[ \rho_k = \begin{cases} 1, & k=0, \\ \frac{\theta_1}{1 + \theta_1^2}, & k=1, \\ 0, & k>1 . \end{cases} \]
这就验证了MA(1)序列是弱平稳列。 MA(1)的自相关函数在\(k>1\)后为零的性质叫做MA序列的自相关函数截尾性。
对于MA(\(q\))序列 \[ X_t = \theta_0 + \varepsilon_t + \theta_1 \varepsilon_{t-1} + \dots + \theta_q \varepsilon_{t-q} , \] 易见 \[ EX_t = \theta_0, \quad \text{Var}(X_t) = \sigma^2(1 + \theta_1^2 + \dots + \theta_q^2) = \gamma_0 . \] 其自相关函数\(\rho_k\)也满足\(q\)后截尾性, 即\(\rho_{k}=0\), \(\forall k > q\)。 如果\(\theta_q \neq 0\), 则\(\rho_q \neq 0\)。 这样, MA(\(q\))序列的两个时间点的观测\(X_s\)和\(X_t\)当\(|s-t|>q\)时不相关, 代表了一种特殊的“有限记忆”的模型。 MA序列的自相关函数截尾性也是在模型识别和定阶时的重要依据。
5.2.2 可逆性
对MA(1)模型, 当\(|\theta_1|<1\)时, 根据本章开始的推导可得 \[ \varepsilon_t = -\phi_0 + X_t + \sum_{j=1}^\infty (-\theta_1)^j X_{t-j} . \] 其中的级数是可以在a.s.意义和均方意义下收敛的。 这表明新息\(\varepsilon_t\)可以用当前的观测\(X_t\)以及历史观测\(X_{t-j}, j=1,2,\dots\)的线性组合表示, 而且历史观测\(X_{t-j}\)所在时刻离\(t\)时刻越远, 其作用越小。 这种性质叫做模型的可逆性。 MA模型的平稳性不需要可逆性条件, 但是从理论讨论的角度, 可逆的线性时间序列更合理: \(\{ X_t, X_{t-1}, \dots \}\)与\(\{\varepsilon_t, \varepsilon_{t-1}, \dots \}\)可以互相线性表示, 对任意\(t \in \mathbb Z\)成立。
5.3 移动平均模型定阶
MA(\(q\))序列的理论自相关函数\(\rho_k\)在\(q\)后截尾, \(\rho_q\neq 0\), \(\rho_k=0\), \(k>q\)。
在\(\{ X_t \}\)为独立同分布白噪声列的条件下, \(k>0\)的\(\hat\rho_k\)渐近\(\text{N}(0, \frac{1}{T})\)分布, 所以查看ACF图, 最后一个显著不等于零的\(\hat\rho_k\)的位置可以暂定为MA模型的阶。
实际上,如\(\{ X_t \}\)是MA(\(q\))序列, 则对\(k>q\),\(\sqrt{T}\hat\rho_k\)渐近服从正态分布, 渐近均值为零,渐近方差为 \[ 1 + 2\rho_1^2 + \dots + 2\rho_q^2 . \]
也可以用AIC定阶:
\[ \text{AIC}(k) = \ln \hat\sigma_k^2 + \frac{2k}{T} . \] 其中\(\hat\sigma_k^2\)是用MA(\(k\))建模时新息方差的最大似然估计。
例5.1 考虑CRSP等权指数月度收益率,时间从1926-1到2008-12。
library(forecast)
d <- read_table(
"m-ibm3dx2608.txt",
col_types=cols(
.default=col_double(),
date=col_date(format="%Y%m%d")))
ibmind <- xts(as.matrix(d[,-1]), d$date)
rm(d)
tclass(ibmind) <- "yearmon"
ew <- ts(coredata(ibmind)[,"ewrtn"],
start=c(1926,1), frequency=12)
head(ibmind)## ibmrtn vwrtn ewrtn sprtn
## 1月 1926 -0.010381 0.000724 0.023174 0.022472
## 2月 1926 -0.024476 -0.033374 -0.053510 -0.043956
## 3月 1926 -0.115591 -0.064341 -0.096824 -0.059113
## 4月 1926 0.089783 0.038358 0.032946 0.022688
## 5月 1926 0.036932 0.012172 0.001035 0.007679
## 6月 1926 0.068493 0.056888 0.050487 0.043184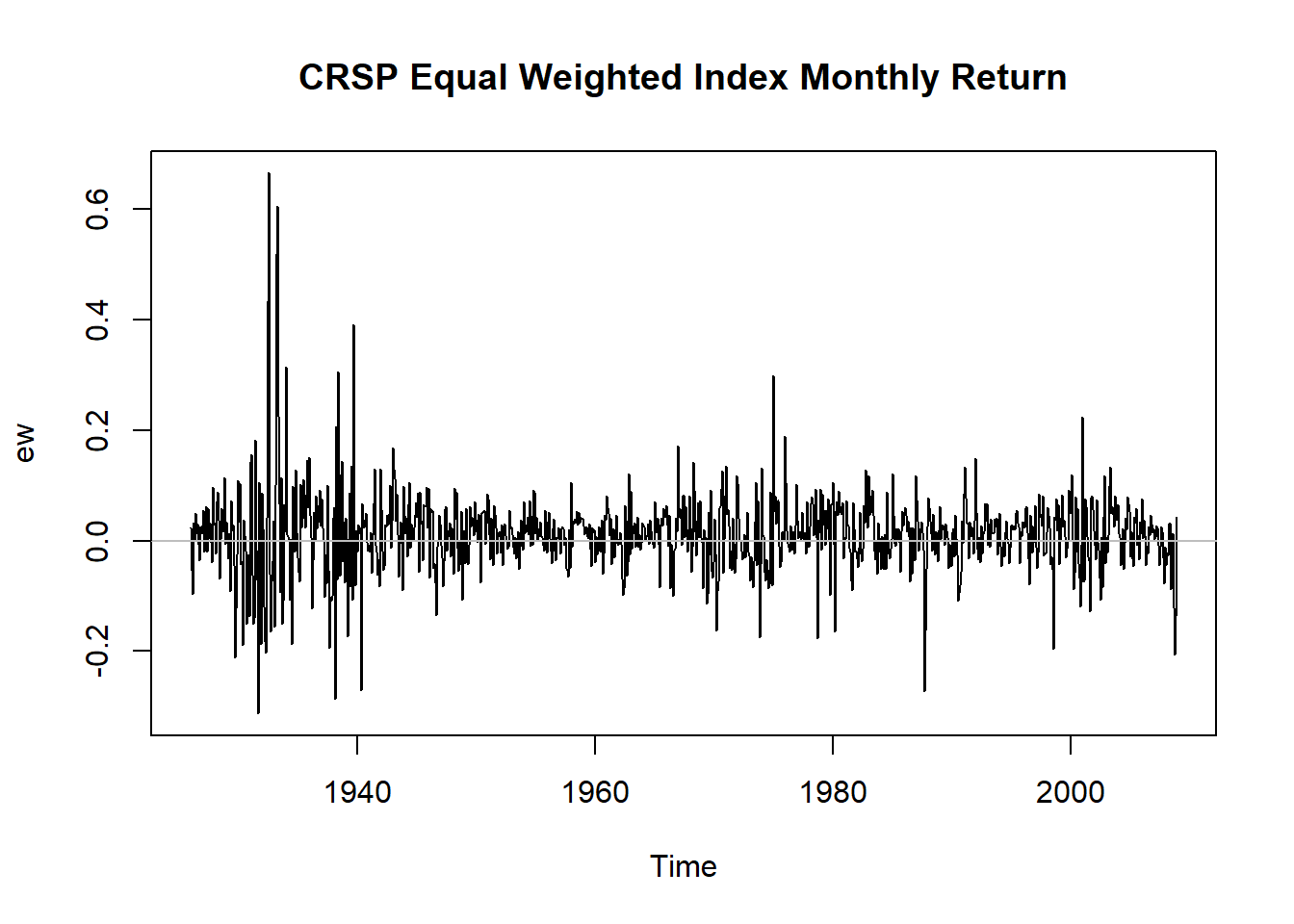
图5.1: CRSP等权指数月度收益率
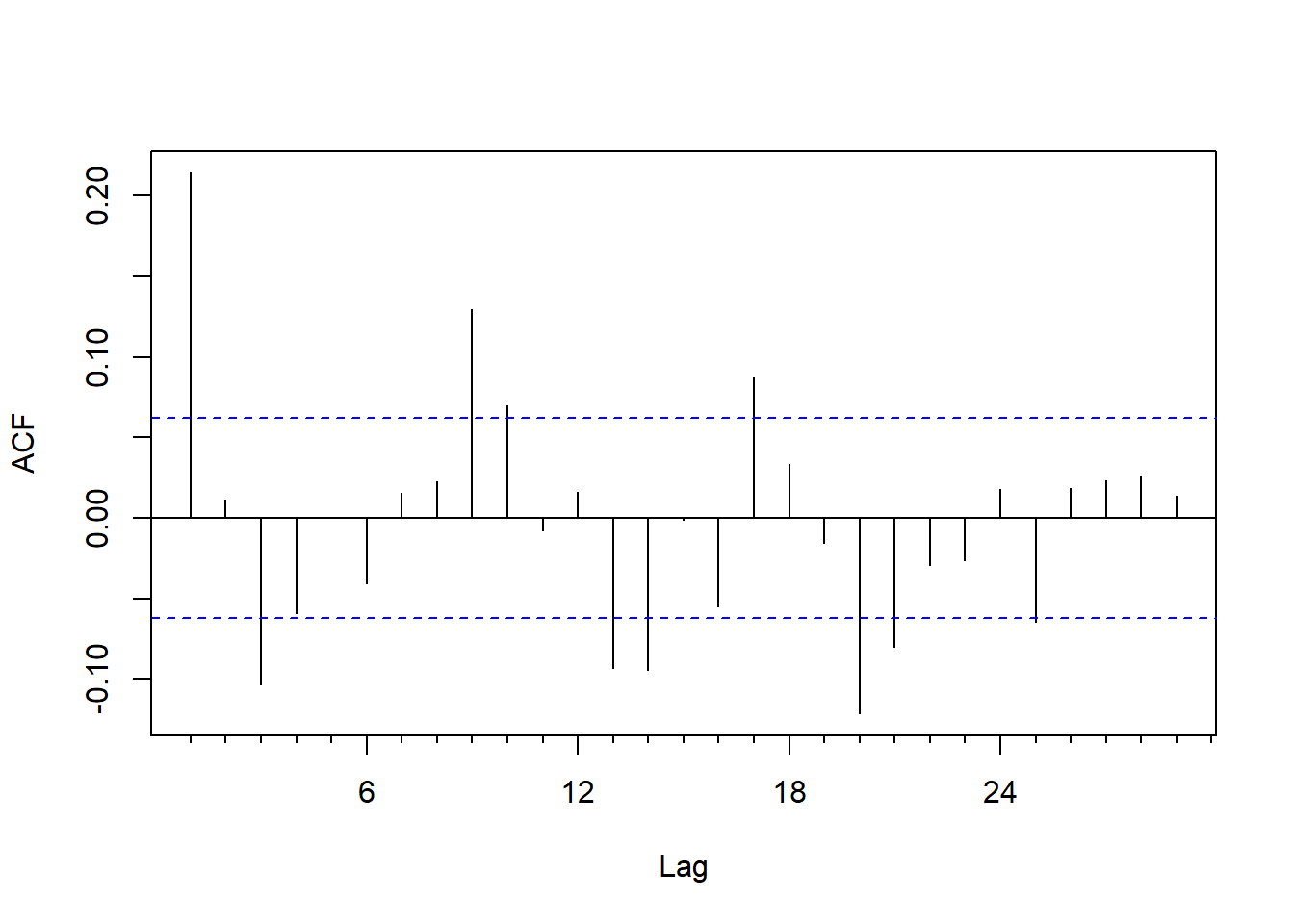
图5.2: CRSP等权指数月收益率的ACF
ACF在\(k=1\)很大,在\(k=3\)和\(k=9\)也比较明显。 可以考虑拟合MA(3)或MA(9)。
○○○○○
5.4 移动平均模型的估计
MA模型参数的估计方法有:
- 矩估计法, 利用\(\{\gamma_k \}\)与\(\{\theta_k\}\)、\(\sigma^2\)的关系求非线性方程组解;
- 逆相关函数法, 将MA模型转换为长阶自回归模型, 用估计自回归模型的方法估计,能保证可逆性;
- 新息估计法;
- 条件最大似然估计法;
- 精确最大似然估计法。
前面三种方法见(何书元 2003)§6.2。
条件最大似然估计法和完全最大似然估计法都假定\(\{\varepsilon_t \}\)为高斯白噪声, 计算似然函数。 在条件最大似然估计法中, 近似假定\(\varepsilon_t=0, t \leq 0\), 这样就可以得到\(\varepsilon_1 = x_1 - \theta_0\), \(\varepsilon_{2} = x_2 - \theta_0 - \theta_1 \varepsilon_1\)等递推表示, 将其代入\(\varepsilon_t, t=1,2,\dots,T\)的独立联合正态分布密度中就得到了条件似然函数, 求其关于\(\sigma^2\)和\(\theta_0, \theta_1, \dots, \theta_q\)的最大值点。
在精确最大似然估计中,将\(\varepsilon_t, t=1-q, 2-q, \dots, -1, 0\)也作为未知参数, 与其它模型参数一起估计。
条件最大似然估计更容易计算,在\(T\)充分大时两者的结果趋于相同。 在样本量较小时精确最大似然估计结果更为精确。 见(Tsay 2010)第8章。
例5.2 考虑例5.1中的CRSP等权指数月度收益率用MA建模, 时间从1926-1到2008-12。
例5.1提示建立MA(9)。
在R中用forecast::Arima()函数可以建立AR模型和MA模型。
## Series: ew
## ARIMA(0,0,9) with non-zero mean
##
## Coefficients:
## ma1 ma2 ma3 ma4 ma5 ma6 ma7 ma8
## 0.2144 0.0374 -0.1203 -0.0425 0.0232 -0.0302 0.0482 -0.0276
## s.e. 0.0316 0.0321 0.0328 0.0336 0.0319 0.0318 0.0364 0.0354
## ma9 mean
## 0.1350 0.0122
## s.e. 0.0323 0.0028
##
## sigma^2 = 0.005094: log likelihood = 1220.86
## AIC=-2419.72 AICc=-2419.45 BIC=-2365.78对残差作Ljung-Box白噪声检验:
##
## Box-Ljung test
##
## data: resm1$residuals
## X-squared = 6.0921, df = 3, p-value = 0.1072结果不显著,检验结果支持所建立的模型。
计算系数的近似\(95\%\)置信区间, 如果置信区间包含0则可以认为该系数在\(0.05\)水平下不显著:
## 2.5 % 97.5 %
## ma1 0.152452388 0.27624981
## ma2 -0.025466807 0.10021681
## ma3 -0.184685872 -0.05594758
## ma4 -0.108316849 0.02341346
## ma5 -0.039294518 0.08575711
## ma6 -0.092442966 0.03201789
## ma7 -0.023194495 0.11965293
## ma8 -0.096985207 0.04180082
## ma9 0.071716326 0.19830549
## intercept 0.006757561 0.01766734也可以直接检验各个系数是否显著:
##
## z test of coefficients:
##
## Estimate Std. Error z value Pr(>|z|)
## ma1 0.2143511 0.0315816 6.7872 1.143e-11 ***
## ma2 0.0373750 0.0320627 1.1657 0.2437424
## ma3 -0.1203167 0.0328420 -3.6635 0.0002488 ***
## ma4 -0.0424517 0.0336053 -1.2632 0.2065014
## ma5 0.0232313 0.0319015 0.7282 0.4664794
## ma6 -0.0302125 0.0317508 -0.9516 0.3413243
## ma7 0.0482292 0.0364413 1.3235 0.1856773
## ma8 -0.0275922 0.0354052 -0.7793 0.4357883
## ma9 0.1350109 0.0322937 4.1807 2.906e-05 ***
## intercept 0.0122124 0.0027832 4.3880 1.144e-05 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1可以看出\(\theta_k\)在\(k=2, 4, 5, 6, 7, 8\)处不显著。
所以,可以用Arima()函数的fixed=指定这些参数固定为0:
## Series: ew
## ARIMA(0,0,9) with non-zero mean
##
## Coefficients:
## ma1 ma2 ma3 ma4 ma5 ma6 ma7 ma8 ma9 mean
## 0.1909 0 -0.1199 0 0 0 0 0 0.1227 0.0122
## s.e. 0.0293 0 0.0338 0 0 0 0 0 0.0312 0.0027
##
## sigma^2 = 0.005118: log likelihood = 1215.61
## AIC=-2421.22 AICc=-2421.16 BIC=-2396.71没有限定之前,AIC为\(-2419.72\); 限定后,AIC为\(-2421.22\),限定后的AIC更优。
为了比较不同的模型, 可以逐个尝试不同的模型并比较AIC的值。
用AIC()可以提取模型的AIC值,
用BIC()可以提取模型的BIC值。
如:
matrix(cbind(c(AIC(resm1), AIC(resm1b)), c(BIC(resm1), BIC(resm1b))),
nrow=2, ncol=2,
dimnames=list(c("无限制", "有限制"), c("AIC", "BIC")))## AIC BIC
## 无限制 -2419.718 -2365.777
## 有限制 -2421.225 -2396.706○○○○○
注意,R的forecast::Arima()函数在估计ARMA(\(p,q\))模型时,
输出结果的对应模型格式为
\[
(1 - \phi_1 B - \dots - \phi_p B^p) (X_t - \mu)
= (1 + \theta_1 B + \dots + \theta_q B^q) \varepsilon_t .
\]
其中\(\mu\)对应于输出中的截距项(intercept)。
系数会输出为ar1, ……, arp, ma1, ……, maq, mean的次序,
ar\(k\)对应\(\phi_k\),ma\(k\)对应\(\theta_k\),
mean对应\(\mu\)。
5.5 移动平均模型的预测
因为MA(\(q\))序列在间隔超过\(q\)步以后就独立, 所以超前多步预测, 只能预测到\(q\)步, 从\(q+1\)步开始就只能用均值\(\mu\)预测了。
以MA(1)为例, \[ X_t = \theta_0 + \varepsilon_t + \theta_1 \varepsilon_{t-1} . \]
超前一步: \[ \hat x_h(1) = E(X_{h+1}|x_1, \dots, x_h) = \theta_0 + \theta_1 \varepsilon_{h} . \] 这里利用了\(E(\varepsilon_{h+1}|x_1, \dots, x_h)=0\)。 \(\varepsilon_h\)是第\(h\)个新息, 可以作为模型的残差计算, 或者通过将MA模型表达为AR模型来计算。 较精确的做法是“递推预报”, 参见(何书元 2003)§5.3。
超前两步: \[ \hat x_h(2) = E(\theta_0 + \varepsilon_{h+2} + \theta_1 \varepsilon_{h+1} | x_1, \dots, x_h) = \theta_0. \] 从两步开始的超前多步预报就变成\(EX_t=\theta_0\)了。
类似地,对于MA(2)序列, \[\begin{aligned} \hat x_h(1) =& \theta_0 + \theta_1 \varepsilon_h + \theta_2 \varepsilon_{h-1}, \\ \hat x_h(2) =& \theta_0 + \theta_2 \varepsilon_{h} . \end{aligned}\] 对\(k=3,4,\dots\)则有\(\hat x_h(k) = \theta_0 = EX_t\)。
在R软件中,
用forecast::Arima()函数建模后,
对建模结果用predict()函数计算预测值和对应的近似标准误差,
用forecast()函数计算预测值和预测区间。
例5.3 考虑例5.2中的CRSP等权指数月度收益率用稀疏系数的MA(9)建模, 但保留最后10个月的数据作为验证。 原始数据中时间从1926-1到2008-12。
## Series: ew[1:986]
## ARIMA(0,0,9) with non-zero mean
##
## Coefficients:
## ma1 ma2 ma3 ma4 ma5 ma6 ma7 ma8 ma9 mean
## 0.1844 0 -0.1206 0 0 0 0 0 0.1218 0.0128
## s.e. 0.0295 0 0.0338 0 0 0 0 0 0.0312 0.0027
##
## sigma^2 = 0.005086: log likelihood = 1206.44
## AIC=-2402.88 AICc=-2402.82 BIC=-2378.41pred1c <- predict(resm1c, n.ahead=10, se.fit=TRUE)
tmp.tab <- cbind(
Observed=round(c(ew[987:996]), 4),
Predicted=round(c(pred1c$pred), 4),
SE=round(c(pred1c$se), 4))
row.names(tmp.tab) <- sprintf("2008-%02d", 3:12)
tmp.tab## Observed Predicted SE
## 2008-03 -0.0260 0.0043 0.0713
## 2008-04 0.0312 0.0136 0.0725
## 2008-05 0.0322 0.0150 0.0725
## 2008-06 -0.0871 0.0145 0.0730
## 2008-07 -0.0010 0.0120 0.0730
## 2008-08 0.0141 0.0018 0.0730
## 2008-09 -0.1209 0.0122 0.0730
## 2008-10 -0.2060 0.0055 0.0730
## 2008-11 -0.1366 0.0085 0.0730
## 2008-12 0.0431 0.0128 0.0735因为次贷危机影响,实际收益率不如预测的那么好。 可以看出当\(k=10\)的时候(模型\(q=9\))预测等于序列均值。 超前多步预测的标准误差逐渐增加到等于序列的样本标准差:
## [1] 0.07368157也可以用forecast::forecast()输出点预测和预测区间:
## Point Forecast Lo 80 Hi 80 Lo 95 Hi 95
## 987 0.004282626 -0.08711683 0.09568208 -0.1355008 0.1440660
## 988 0.013558874 -0.07938205 0.10649980 -0.1285820 0.1556997
## 989 0.015024191 -0.07791673 0.10796511 -0.1271167 0.1571651
## 990 0.014453445 -0.07913832 0.10804521 -0.1286828 0.1575897
## 991 0.012046343 -0.08154542 0.10563811 -0.1310899 0.1551826
## 992 0.001805558 -0.09178621 0.09539733 -0.1413307 0.1449418
## 993 0.012211538 -0.08138023 0.10580331 -0.1309247 0.1553478
## 994 0.005514814 -0.08807695 0.09910658 -0.1376214 0.1486511
## 995 0.008513456 -0.08507831 0.10210522 -0.1346228 0.1516497
## 996 0.012791824 -0.08145987 0.10704352 -0.1313537 0.1569373○○○○○