1 金融数据分析中的R软件介绍
1.1 本课程的软件需求
课程采用Ruey S. Tsay的《金融数据分析导论:基于R语言》 (An Introduction to Analysis of Financial Data with R)作为主要教材之一。 课程讲述金融时间序列分析的各种模型, 以及如何用R软件进行建模计算。
作为基础, 学生需要重点掌握R软件如下功能:
- 基本数据类型,日期和日期时间类型,数据输入输出
- Rmd格式文件运用
- 时间序列类型zoo, xts, timeSeries类型
- quantmod包
关于R软件基本使用, 详见李东风的R软件教程, 第1、2章,第9章。
关于Quarto格式文件(扩展名使用.qmd的文件), 详见李东风的R软件教程, 第20–22章。
本章需要安装的R扩展包: quantmod, lubridate, tidyverse.
注意:本章的例子需要用library()命令将tidyverse,
lubridate, quantmod包调入才能运行。
方法为
library(tidyverse) # Wickham的数据整理的整套工具
library(lubridate) # 日期和日期时间数据处理
library(quantmod) # 金融数据的整理与作图功能R软件中的时间序列类型有基本R提供的ts类型, zoo包提供的zoo和zooreg类型, xts包提供的xts类型, tsibble包提供的tsibble类型, tseries包提供的irts类型, Rmetrics包提供的timeSeries类型, 等等。 本课程主要使用ts、xts和tsibble类型。
其它与金融时间序列有关的扩展包还有 fable, tabletools, feasts, fBasics, fGarch, fPortfolio, tsgarch, tsmgarch等等。
参考:
1.2 基本R使用
R是一个数据分析、统计建模和作图的软件, 其中包含一门计算机语言称为R语言, 此语言与通常的C、C++、Java等编程语言相比, 支持更多的数据类型, 如向量、矩阵, 并提供了多种统计和数学计算方法。
为了在金融时间序列计算中使用R语言, 这里简单介绍一些最基本的使用方法。
R软件是一个开源软件, 可以免费地从其网站http://www.r-project.org提供的镜像网站下载安装。 另外, RStudio是一个R软件的集成开发环境, 在该软件中可以更方便地使用R软件, 虽然RStudio是商业软件, 但非商业用户可以免费地使用。
R可以在命令行运行, 每次运行一条命令, 结果显示在命令下方。 也可以将多条R命令写成一个源程序文件, 然后运行整个文件。 在RStudio软件中也可以选中若干行程序, 运行选中的部分。
1.2.1 四则运算
R中用+ - * / ^分别表示加、减、乘、除、乘方。
数值可以写成如123, -123, 123.45,
1.23E-5这样的形式,
其中1.23E-5表示\(1.23 \times 10^{-5}\)。
1.2.3 向量
R中最基本的单位是向量,
单个数值是长度为1的向量。
简单的向量可以用c(...)定义,如
长度相同的两个向量之间可以做四则运算, 结果是对应的元素进行四则运算。 单个元素可以和一个向量进行四则运算, 结果是该元素与向量的每一个元素进行四则运算。 如
1.2.4 矩阵
R支持矩阵类型,
矩阵是有\(n\)行、\(p\)列的数值排列成的存储结果,
在第\(i\)行、第\(j\)列有一个数值元素。
矩阵A的第\((i,j)\)元素表示为A[i,j],
矩阵的第\(j\)列作为一个向量,
可以表示为A[,j,drop=TRUE]。
nrow(A)求A的行数,
ncol(A)求A的列数。
两个相同形状的矩阵可以进行加、减、乘、除四则运算, 结果是对应的元素进行四则运算。 单个元素可以与矩阵进行四则运算, 结果是该元素与矩阵的每个元素进行四则运算。
两个向量x1和x2,
可以用cbind(x1, x2)合并为两列的矩阵。
1.2.5 数据框
R数据框是和矩阵类似的存储结构, 但是允许不同列的数据类型不同, 比如, 一列是日期, 一列是评级(字符串), 一列是收益率(数值)。
数据框的每一列都有列名,
用names(d)或者colnames(d)访问。
将数据框d的某一列取出作为一个向量,
用d[["列名"]]的格式。
1.2.6 扩展包
R的许多功能由不同的扩展包(package)提供。
为了调用某个扩展包的功能,
需要先用library()命令载入该扩展包,
如
某些扩展包还允许用包名::函数名()的格式直接调用其中的函数。
1.2.7 日期和日期时间
R日期可以保存为Date类型, 一般用整数保存,数值为从1970-1-1经过的天数。
R中用一种叫做POSIXct和POSIXlt的特殊数据类型保存日期和时间, 可以仅包含日期部分, 也可以同时有日期和时间。 技术上,POSIXct把日期时间保存为从1970年1月1日零时到该日期时间的时间间隔秒数。 日期时间会涉及到所在时区、夏时制等问题, 比较复杂。
lubridate是一个提供了许多日期和日期时间功能的扩展包。
对于"2018-07-02"这样的字符型的日期,
可以用lubridate::ymd("2018-07-02")这样的方法转换成Date类型,
该函数也可以输入字符型向量,向量的每个元素是一个日期字符串,
结果为Date类型元素组成的向量。
如果year, mon, day分别是数值类型的年、月、日,
可以用lubridate::make_date(year, mon, day)转换成Date类型。
lubridate::ymd_hms()可以将"2018-07-02 13:15:59"这样的日期和时间字符串转换成POSIXct类型,
lubridate::make_datetime()可以将单独的整数表示的年、月、日、时、分、秒转换成POSIXct类型。
lubridate包的year(), month(), mday()可以从日期或日期时间中取出年、月、日,
hour()、minute()、second()可以从日期时间中取出时、分、秒。
更详细的用法见R软件教程。
1.2.8 读入时间序列数据
常见的数据形式是用文本格式保存, 数据之间用空行、空格或者逗号分隔。
1.2.8.1 单个向量读入
最简单的情况是仅有一个序列,
数据仅包含序列的数值而不包含时间标签,
这时数据可以保存为用空行和空格分隔的文本格式数据,
例如文件bp500-2691.txt是标准普尔500指数月超额收益率从1926年1月到1991年12月的数据,
内容为(节选):
0.0225 -0.044 -0.0591 0.0227 0.0077 0.0432 0.0455 0.0171 0.0229 -0.0313 0.0223 0.0166
-0.0208 0.0477 0.0065 0.0172 0.0522 -0.0094 0.065 0.0445 0.0432 -0.0531 0.0678 0.019
-0.0051 -0.0176 0.1083 0.0324 0.0127 -0.0405 0.0125 0.0741 0.024 0.0145 0.1199 0.0029
0.0571 -0.0058 -0.0023 0.0161 -0.0428 0.1124 0.0456 0.098 -0.0489 -0.1993 -0.1337 0.0253可以用如下程序读入成R向量:
1.2.8.2 带有时间标签的序列
有些序列带有时间标签,
同一行的数据之间用空格或者制表符分隔。
文件d-ibm-0110.txt为IBM股票从2001-1-2到2010-12-31的日简单收益率,
部分数据如下:
date return
20010102 -0.002206
20010103 0.115696
20010104 -0.015192
20010105 0.008719
20010108 -0.004654
20010109 -0.010688
20010110 0.009453可以用如下程序读入成一个R数据框:
library(tidyverse)
library(lubridate)
d <- read_table(
"d-ibm-0110.txt", col_types=cols(
.default=col_double(),
date=col_date(format="%Y%m%d")))有些序列的年月日是分开输入的,
比如,
文件m-unrate.txt为美国从1948年1月到2010年9月的经季节调整的月失业率百分数,
部分数据如:
Year mon dd rate
1948 01 01 3.4
1948 02 01 3.8
1948 03 01 4.0
1948 04 01 3.9
1948 05 01 3.5可以用如下程序读入为R数据框, 并生成日期列:
d <- read_table(
"m-unrate.txt", col_types=cols(
.default=col_double())) %>%
mutate(date = make_date(Year, mon, dd)) %>%
select(-Year, -mon, -dd) %>%
select(date, everything())同一个文件中有多个序列时, 也可以用如上方法读入为R数据框。 如m-ibmsp-2611.txt包含了IBM和标普500从1926-01到2011-09的月度简单收益率, 部分数据如下:
date ibm sp
19260130 -0.010381 0.022472
19260227 -0.024476 -0.043956
19260331 -0.115591 -0.059113
19260430 0.089783 0.022688读入为tibble数据框:
1.2.8.3 读入csv格式
CSV文件也是一种文本格式的数据文件, 相对而言更规范一些, 所以经常用于在不同的数据管理和数据分析软件之间传递数据。 数据如:
"date","ibm","sp"
"19260130",-0.010381,0.022472
"19260227",-0.024476,-0.043956
"19260331",-0.115591,-0.059113
"19260430",0.089783,0.022688
"19260528",0.036932,0.007679
"19260630",0.068493,0.043184
"19260731",0,0.045455可以用如下程序读入为R数据框:
1.3 生成时间序列数据
R软件中有些时间序列分析函数需要特定的时间序列类型数据作为输入。 常用的有ts类型、xts类型等。
1.3.1 生成ts类型
ts类型用于保存一元或者多元的等间隔时间序列, 如月度、季度、年度数据。 生成方法如
其中x是向量或者矩阵,
取矩阵值时矩阵的每一列是一个序列。
frequency对月度数据是12,
对季度数据是4,
对年度数据可以缺省(值为1)。
start=c(2001,1)表示序列开始时间是2001年1月。
如果是年度数据,
用如ts(x, start=2001)即可。
例如,
文件m-unrate.txt
为美国从1948年1月到2010年9月的经季节调整的月失业率百分数,
转换成ts类型并作时间序列曲线图的程序如下:
d <- read.table(
"m-unrate.txt", header=TRUE,
colClasses=rep("numeric", 4))
unrate <- ts(d[["rate"]], start=c(1948,1), frequency=12)
plot(unrate)
1.3.2 生成xts类型
xts也是一种时间序列数据类型, 既可以保存等间隔时间序列数据, 也可以保存不等间隔的时间序列数据, 并且xts类型的数据访问功能更为方便。 生成方法如
其中x是向量、矩阵或数据框,
date是日期或者日期时间。
x取矩阵或者数据框时每列是一个时间序列。
例如,
文件d-ibm-0110.txt为IBM股票从2001-1-2到2010-12-31的日简单收益率,
读入数据并转换为xts类型并作图的程序如下:
library(xts)
d <- read_table(
"d-ibm-0110.txt", col_types=cols(
.default=col_double(),
date=col_date(format="%Y%m%d")))
ibmrtn <- xts(d[["return"]], d[["date"]])
plot(ibmrtn,
main="IBM Log Return Daily",
major.ticks="years", minor.ticks=NULL,
grid.ticks.on="years",
format.labels="%Y",
col="red")有了xts类型的变量x后,
可以用coredata(x)返回x的不包含时间的纯数据;
用index(x)返回x的时间标签。
xts类型可以比较容易地取出子集,如:
x["2003"]取出2003年的子集;x["2003-12"]取出2003年12月的子集;- `x[“2003-07/2004-06”]取出2003年7月到2004年6月的子集,等等。
下面几节更详细地叙述各种时间序列对象的用法。
1.3.3 生成tsibble类型
详见1.7。
1.4 ts类型
ts是基本R软件的stats包中支持的规则时间序列类型,
具有start和frequency两个属性,
对于年度数据,frequency=1,
对于月度数据,frequency=12。
但是日数据最好不时间标签为具体日历时间的ts类型,
因为金融数据的日数据在周末和节假日一般无数据,
而ts类型要求时间是每一天都相连的,
不能周五直接跳到周一。
用函数ts把一个向量转换为时间序列。
如
yd <- ts(
c(4, 8, 7, 7, 3, 1, 8, 9, 8, 6, 3, 5,
5, 8, 2, 5, 9, 2, 5, 2, 3, 2, 2, 4),
frequency=1, start=2001); yd## Time Series:
## Start = 2001
## End = 2024
## Frequency = 1
## [1] 4 8 7 7 3 1 8 9 8 6 3 5 5 8 2 5 9 2 5 2 3 2 2 4ym <- ts(
c(9, 6, 3, 5, 4, 8, 2, 5, 8, 4, 6, 3,
2, 2, 6, 4, 1, 4, 2, 1, 8, 9, 4, 6),
frequency=12, start=c(2001,1)); ym## Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
## 2001 9 6 3 5 4 8 2 5 8 4 6 3
## 2002 2 2 6 4 1 4 2 1 8 9 4 6其中freqency指定采样频率,
如月数据是12。
start指定开始点,
如上面的yd是年数据,开始于2001年;
ym是月数据开始于2001年1月。
对于多元时间序列,可以用ts函数把一个矩阵转换为ts类型的多元时间序列对象。 用ts.intersect函数和ts.union函数可以把两个或多个时间序列合并为多元时间序列, 时间段取交集或者取并集。
为了使用序列数据进行计算、绘图等, 可以用as.vector把一元时间序列的数据转换成普通向量。 如:
## [1] 9 6 3 5 4 8 2 5 8 4 6 3 2 2 6 4 1 4 2 1 8 9 4 6对于多元时间序列x,
可以用x[,1]这样的格式取出其中分量时间序列,
可以用as.vector(x[,1])将其中的分量转换为普通向量,
可以借助于xts类型用coredata(as.xts(x))将多元时间序列的数据转换为普通矩阵。
在R中已安装的时间列示例数据有美国泛美航空公司1949-1960 的国际航班订票数的月度数据(单位:千人),12年144个月。 用
调入名字空间。类型和属性如下:
## $tsp
## [1] 1949.000 1960.917 12.000
##
## $class
## [1] "ts"这里时间以年为单位, 数据类属为ts, 两个数据值之间的时间间隔为\(1/12\)。
AirPassengers的具体数值:
## Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
## 1949 112 118 132 129 121 135 148 148 136 119 104 118
## 1950 115 126 141 135 125 149 170 170 158 133 114 140
## 1951 145 150 178 163 172 178 199 199 184 162 146 166
## 1952 171 180 193 181 183 218 230 242 209 191 172 194
## 1953 196 196 236 235 229 243 264 272 237 211 180 201
## 1954 204 188 235 227 234 264 302 293 259 229 203 229
## 1955 242 233 267 269 270 315 364 347 312 274 237 278
## 1956 284 277 317 313 318 374 413 405 355 306 271 306
## 1957 315 301 356 348 355 422 465 467 404 347 305 336
## 1958 340 318 362 348 363 435 491 505 404 359 310 337
## 1959 360 342 406 396 420 472 548 559 463 407 362 405
## 1960 417 391 419 461 472 535 622 606 508 461 390 432用start()求时间序列的开始点,
end()求时间序列的结束点,
frequency()求采样频率。
如
## [1] 1949 1## [1] 1960 12## [1] 12aggregate()函数可以把月度数据加总成年数据。
如
## Time Series:
## Start = 1949
## End = 1960
## Frequency = 1
## [1] 1520 1676 2042 2364 2700 2867 3408 3939 4421 4572 5140 5714如果加参数FUN=mean可以取均值。
time()函数对ts类型数据返回序列中的每个时间点的时间,
结果是一个和原来时间序列形状相同的时间序列。
cycle()函数对月度数据返回序列每个时间点所在的月份,
结果是和原序列时间点相同的一个时间序列。如
## Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
## 1949 1 2 3 4 5 6 7 8 9 10 11 12
## 1950 1 2 3 4 5 6 7 8 9 10 11 12
## 1951 1 2 3 4 5 6 7 8 9 10 11 12
## 1952 1 2 3 4 5 6 7 8 9 10 11 12
## 1953 1 2 3 4 5 6 7 8 9 10 11 12
## 1954 1 2 3 4 5 6 7 8 9 10 11 12
## 1955 1 2 3 4 5 6 7 8 9 10 11 12
## 1956 1 2 3 4 5 6 7 8 9 10 11 12
## 1957 1 2 3 4 5 6 7 8 9 10 11 12
## 1958 1 2 3 4 5 6 7 8 9 10 11 12
## 1959 1 2 3 4 5 6 7 8 9 10 11 12
## 1960 1 2 3 4 5 6 7 8 9 10 11 12window()函数取出时间序列的一段,
如果指定frequency=TRUE还可以仅取出某个月(季度)。
如
## Time Series:
## Start = 1949
## End = 1960
## Frequency = 1
## [1] 112 115 145 171 196 204 242 284 315 340 360 417stats::lag()可以计算滞后序列,
对ts类型输入,
lag()的作用是序列数值不变,
但是时间标签增加一个单位或者用k=指定的间隔。
所以,
为了得到通常理解的滞后1序列,应该使用stats::lag(x, k=-1),
如
## Time Series:
## Start = 2001
## End = 2005
## Frequency = 1
## [1] 1 2 3 4 5## Time Series:
## Start = 2002
## End = 2006
## Frequency = 1
## [1] 1 2 3 4 5## Time Series:
## Start = 2001
## End = 2006
## Frequency = 1
## x1 x2
## 2001 1 NA
## 2002 2 1
## 2003 3 2
## 2004 4 3
## 2005 5 4
## 2006 NA 5diff(x)计算一阶差分,
diff(x, lag, differences)计算滞后为lag的阶数位differences的差分。
ts.union可以形成多元时间序列。
filter函数可以计算递推的或卷积的滤波。
arima可以拟合ARIMA模型。
acf和pacf函数可以作自相关和偏自相关图。
1.5 zoo类型
R的zoo扩展包提供了比基本R中ts时间序列类型更灵活的时间序列类型, 其时间标签(time stamp)可以使用R中任何的日期和时间类型, 序列不需要是等时间间隔的,支持多元时间序列。 如果序列符合ts类型的要求, 则与ts类型兼容并可以互相转换。 zoo也尽可能提供与ts类相同或相似功能的函数。 zoo扩展包提供的时间序列数据类型叫做zoo类型。
xts类型以zoo类型为基础, 使用比zoo类型更简单, 在R的各种时间序列分析软件包中使用更普遍。
1.5.1 生成zoo类型的时间序列
生成zoo类型的时间序列,
只要提供两部分输入:
一个向量或者矩阵x作为观测值,
一个下标序列order.by作为排序变量以及时间标签。
zoo的设计特点是允许使用任何可排序的数据类型作为时间标签。
语法为
当x是矩阵时,
每行对应同一时间点,
不同列是不同的时间序列,
但同一行的各个数值对应相同的时间点。
例如
set.seed(1)
z.1 <- zoo(sample(3:6, size=12, replace=TRUE),
make_date(2018, 1, 1) + ddays(0:11)); z.1## 2018-01-01 2018-01-02 2018-01-03 2018-01-04 2018-01-05 2018-01-06 2018-01-07
## 3 6 5 3 4 3 5
## 2018-01-08 2018-01-09 2018-01-10 2018-01-11 2018-01-12
## 5 4 4 5 5set.seed(2)
z.2 <- zoo(cbind(x=sample(5:10, size=12, replace=TRUE),
y=sample(8:13, size=12, replace=TRUE)),
make_date(2018, 1, 1) + ddays(0:11)); z.2## x y
## 2018-01-01 9 10
## 2018-01-02 10 13
## 2018-01-03 10 9
## 2018-01-04 5 10
## 2018-01-05 9 8
## 2018-01-06 5 13
## 2018-01-07 8 8
## 2018-01-08 9 11
## 2018-01-09 5 10
## 2018-01-10 6 13
## 2018-01-11 7 8
## 2018-01-12 5 13时间不必是连续的,如
set.seed(1)
z.3 <- zoo(101:112,
make_date(2018, 1, 1) +
ddays(sample(0:30, 12, replace=FALSE))); z.3## 2018-01-01 2018-01-02 2018-01-04 2018-01-07 2018-01-10 2018-01-11 2018-01-14
## 104 105 102 103 112 107 108
## 2018-01-18 2018-01-19 2018-01-23 2018-01-25 2018-01-28
## 109 110 106 101 111注意输入的随机生成的日期次序是乱序的, 但生成zoo时间序列后一定会按照正常时间序列排好次序。
ts、irts(在tseries包中定义)、its等时间序列类型可以用as.zoo()转换为zoo类型,
如果zoo类型的时间下标符合转换要求,
也可以将zoo时间序列用as.xxx()类函数转换为其它时间序列类型。
文本文件中、字符串中、数据框中保存的时间序列数据可以用read.zoo()转换为zoo时间序列。
1.5.2 zoo类型的概括情况
设x为zoo类型的时间序列,
print(x)显示x,
对一元序列横向显示,
对多元序列纵向显示。
str(x)显示x的类型和结构信息,如
## 'zoo' series from 2018-01-01 to 2018-01-12
## Data: int [1:12, 1:2] 9 10 10 5 9 5 8 9 5 6 ...
## - attr(*, "dimnames")=List of 2
## ..$ : NULL
## ..$ : chr [1:2] "x" "y"
## Index: Date[1:12], format: "2018-01-01" "2018-01-02" "2018-01-03" "2018-01-04" "2018-01-05" ...head(x)和tail(x)可以取出序列开头的若干项与末尾的若干项,如:
## x y
## 2018-01-01 9 10
## 2018-01-02 10 13
## 2018-01-03 10 9
## 2018-01-04 5 10
## 2018-01-05 9 8
## 2018-01-06 5 13summary(x)对每个序列以及时间下标作简单概括统计,如
## Index x y
## Min. :2018-01-01 Min. : 5.000 Min. : 8.00
## 1st Qu.:2018-01-03 1st Qu.: 5.000 1st Qu.: 8.75
## Median :2018-01-06 Median : 7.500 Median :10.00
## Mean :2018-01-06 Mean : 7.333 Mean :10.50
## 3rd Qu.:2018-01-09 3rd Qu.: 9.000 3rd Qu.:13.00
## Max. :2018-01-12 Max. :10.000 Max. :13.001.5.3 zoo类型的子集
对zoo类型的时间序列, 不管它保存的是一元序列还是多元序列, 都可以向对向量那样用一维的下标取子集,如
## x y
## 2018-01-01 9 10## x y
## 2018-01-10 6 13
## 2018-01-11 7 8
## 2018-01-12 5 13对多元序列,也可以象矩阵那样取子集,如
## x y
## 2018-01-01 9 10
## 2018-01-02 10 13
## 2018-01-03 10 9## 2018-01-01 2018-01-02 2018-01-03
## 10 13 9序列也可以直接用时间作为下标,比如
## x y
## 2018-01-01 9 10
## 2018-01-12 5 13如果时间下标本身也是数值,
而且不等于序号,
可以在用作下标时包裹在I()函数中以免被认作序号下标。
1.5.4 zooreg类型
为了与规则时间序列的ts类型相对应, zoo扩展包提供了zoo的派生类型zooreg, 代表规则间隔的时间序列, 它具有与ts相同的时间间隔信息, 待允许内部某些时间点不存在。
用zoo()函数加frequency选项或者
zooreg()函数生成zooreg类型的时间序列:
例如:
## 2001 Q1 2001 Q2 2001 Q3 2001 Q4 2002 Q1 2002 Q2 2002 Q3 2002 Q4
## 1 3 5 7 9 11 13 17zooreg类型比ts优点是即使删去中间若干点, 其类型仍保持为zooreg类型:
## 2001 Q1 2001 Q3 2002 Q1 2002 Q3
## 1 5 9 13## [1] "zooreg" "zoo"## [1] 4这样比ts必须以NA保存缺失数值的时间点要容易处理。
zooreg也可以以日、时、分、秒等作为时间间隔,如
## 2018-01-01 2018-01-02 2018-01-03 2018-01-04 2018-01-05 2018-01-06 2018-01-07
## 1 3 5 7 9 11 13
## 2018-01-08
## 17可以用is.regular(x)判断一个zoo类型数据是否规则,
用is.regular(x, strict=TRUE)判断一个zoo类型数据是否满足和ts一样条件的规则序列。
用as.ts(x)将一个规则的zooreg或者zoo类型数据转换为ts类型的时间序列。如果x内部有缺失的时间点,
转换为ts类型时将补上这些时间点,观测值填以NA。
当zoo类型的下标是数值型、月度、季度时可以与ts无损地互相转换。
用as.zoo(x)将ts类型的时间序列转换为zoo类型。
如果x可以转换为ts类型,
则对ts可以应用的acf(), arima(), stl()等函数也可以对x应用。
1.5.5 对zoo类型作图
用plot()函数对zoo类型数据做图。
一元时如
序列不规则时:
对多元序列,plot()缺省每个序列单独画在一个窗格,如
也可以用
plot.type="single"要求画在同一坐标系中:
plot()中仍可以用col指定颜色,
用lty指定线型,
用lwd指定线粗细,
用pch指定散点类型,
用cex指定散点大小。
当时间跨度为若干年时,
经常用format.labels="%Y"选项使得时间轴刻度标签仅包含年份。
对多元序列,
可以为每条曲线指定不同的图形属性。
指定图形属性时,
可以用一个列表指定,
列表元素名对应于序列中某属性的名字,如
并且可以仅指定部分属性的图形参数, 其它用默认值。
autoplot()可以基于ggplot2包对时间序列绘图。
1.5.6 序列合并
两个保存了不同时间段的时间序列x, y可以用c(x,y)或者
rbind(x,y)合并,如
## 2018-01-01 2018-01-02 2018-01-03 2018-01-04 2018-01-09 2018-01-10 2018-01-11
## 3 6 5 3 4 4 5
## 2018-01-12
## 5## x y
## 2018-01-01 9 10
## 2018-01-02 10 13
## 2018-01-03 10 9
## 2018-01-04 5 10
## 2018-01-09 5 10
## 2018-01-10 6 13
## 2018-01-11 7 8
## 2018-01-12 5 13两个不同属性的时间序列, 可以合并为一个多元时间序列, 时间取并集, 不存在的值取缺失值。 两个序列不需要等长。 如
## x y z.3[1:4]
## 2018-01-01 NA NA 104
## 2018-01-02 NA NA 105
## 2018-01-03 10 9 NA
## 2018-01-04 5 10 102
## 2018-01-05 9 8 NA
## 2018-01-06 5 13 NA
## 2018-01-07 8 8 103用names(x)给多元时间序列的各个分量赋值,如
## x y z3
## 2018-01-01 NA NA 104
## 2018-01-02 NA NA 105
## 2018-01-03 10 9 NA
## 2018-01-04 5 10 102
## 2018-01-05 9 8 NA
## 2018-01-06 5 13 NA
## 2018-01-07 8 8 103为了在合并时仅保留共同的时间点,可以用如
## x y z.3[1:4]
## 2018-01-04 5 10 102
## 2018-01-07 8 8 103merge()也可以同时横向合并多个序列,
如merge(x, y, z)。
除了第一个自变量,允许被合并的其它成分不是时间序列,
这时沿用第一个自变量的时间信息。
如
## z.1 1:12
## 2018-01-01 3 1
## 2018-01-02 6 2
## 2018-01-03 5 3
## 2018-01-04 3 4
## 2018-01-05 4 5
## 2018-01-06 3 6
## 2018-01-07 5 7
## 2018-01-08 5 8
## 2018-01-09 4 9
## 2018-01-10 4 10
## 2018-01-11 5 11
## 2018-01-12 5 121.5.7 降频与升频
类似于ts时间序列,
对zoo时间序列,
也可以用aggregate()对数据进行降频,
比如,从日数据转换成月数据。
例:
## 1949 1950 1951 1952 1953 1954 1955 1956 1957 1958 1959 1960
## 1520 1676 2042 2364 2700 2867 3408 3939 4421 4572 5140 5714aggregate()的一般用法是
其中by可以是与序列等长的一个分组值向量,
也可以是一个函数,此函数接受index(x)为自变量生成分组值,
如上例。
FUN是对每组作的操作。
在每组中取最后一个值的例子:
## 1949 1950 1951 1952 1953 1954 1955 1956 1957 1958 1959 1960
## 118 140 166 194 201 229 278 306 336 337 405 432有时需要对序列提高时间频率,
比如,将年度数据转换成月度数据。
办法是与一个高频的仅用时间下标而无实际数据的序列横向合并。
例如,基本R软件中有个Nile对象是尼罗河1871-1970的年流量
(单位:亿立方米),将其升频到季度数据:
## 1871 1872 1873 1874 1875 1876
## 1120 1160 963 1210 1160 1160## 1871(1) 1871(2) 1871(3) 1871(4) 1872(1) 1872(2)
## 1120 NA NA NA 1160 NA在升频时年度值变成了第一季度的值, 其它三个季度变成了缺失值。 这是因为原始的年度数据相当于是1月1日的数据, 可以和第一季度的代表日期对准。
用na.locf()可以填补缺失值,
填前面最近的一个非缺失值:
## 1871(1) 1871(2) 1871(3) 1871(4) 1872(1) 1872(2)
## 1120 1120 1120 1120 1160 1160用na.approx()可以对缺失值填充为线性插值,如
## 1871(1) 1871(2) 1871(3) 1871(4) 1872(1) 1872(2)
## 1120.00 1130.00 1140.00 1150.00 1160.00 1110.751.5.8 zoo时间序列的数学计算
两个序列之间可以进行加减乘除四则运算和逻辑比较运算, 结果是对应时间点的相应运算。 缺失值被删除。 如
## x y
## 2018-01-04 107 112
## 2018-01-07 111 111cumsum(), cumprod(),
cummin(), cummax()等函数仍可作用到zoo时间序列的每个序列上。
如果序列是价格,用如下方法计算简单收益率与对数收益率:
## 2018-01-03 2018-01-04 2018-01-05 2018-01-06 2018-01-07 2018-01-08 2018-01-09
## -0.1666667 -0.4000000 0.3333333 -0.2500000 0.6666667 0.0000000 -0.2000000
## 2018-01-10 2018-01-11 2018-01-12
## 0.0000000 0.2500000 0.0000000## 2018-01-02 2018-01-03 2018-01-04 2018-01-05 2018-01-06 2018-01-07 2018-01-08
## 0.6931472 -0.1823216 -0.5108256 0.2876821 -0.2876821 0.5108256 0.0000000
## 2018-01-09 2018-01-10 2018-01-11 2018-01-12
## -0.2231436 0.0000000 0.2231436 0.0000000这样的简单版本删去了第一个时间点, 因为这个时间点的盈利缺失。 为了包括此点,做法如
simple.return <- function(x){
d <- merge(stats::lag(x, k=-1), x, all=TRUE)
(d[,2] - d[,1])/d[,1]
}
simple.return(z.1)## 2018-01-01 2018-01-02 2018-01-03 2018-01-04 2018-01-05 2018-01-06 2018-01-07
## NA 1.0000000 -0.1666667 -0.4000000 0.3333333 -0.2500000 0.6666667
## 2018-01-08 2018-01-09 2018-01-10 2018-01-11 2018-01-12
## 0.0000000 -0.2000000 0.0000000 0.2500000 0.0000000以上两个simple.return()函数定义都依赖于stats::lag()函数或者日期对齐,
对zoo和xts类型可用,但是对其它时间序列类型有可能出错。
simple.return()的如下定义不需要输入的时间序列特性:
simple.return <- function(x){
x <- as.vector(x)
c(NA, diff(x) / x[1:(length(x)-1)])
}
simple.return(z.1)## [1] NA 1.0000000 -0.1666667 -0.4000000 0.3333333 -0.2500000
## [7] 0.6666667 0.0000000 -0.2000000 0.0000000 0.2500000 0.00000001.5.9 zoo属性访问
zoo时间序列类型的实际数据可以用coredata()读取或修改。
读取时对一元序列结果是数值型向量,
对多元序列结果是矩阵。
如
## x y
## [1,] 9 10
## [2,] 10 13
## [3,] 10 9
## [4,] 5 10
## [5,] 9 8
## [6,] 5 13
## [7,] 8 8
## [8,] 9 11
## [9,] 5 10
## [10,] 6 13
## [11,] 7 8
## [12,] 5 13## x y
## 2018-01-01 109 110
## 2018-01-02 110 113
## 2018-01-03 110 109
## 2018-01-04 105 110
## 2018-01-05 109 108
## 2018-01-06 105 113
## 2018-01-07 108 108
## 2018-01-08 109 111
## 2018-01-09 105 110
## 2018-01-10 106 113
## 2018-01-11 107 108
## 2018-01-12 105 113用as.data.frame()将zoo对象转换成数据框,
时间下标变成数据框的行名,如
## x y
## 2018-01-01 9 10
## 2018-01-02 10 13
## 2018-01-03 10 9
## 2018-01-04 5 10
## 2018-01-05 9 8
## 2018-01-06 5 13
## 2018-01-07 8 8
## 2018-01-08 9 11
## 2018-01-09 5 10
## 2018-01-10 6 13
## 2018-01-11 7 8
## 2018-01-12 5 13zoo时间序列的时间下标可以用index()函数读取或修改,如
## [1] "2018-01-01" "2018-01-02" "2018-01-03" "2018-01-04" "2018-01-05"
## [6] "2018-01-06" "2018-01-07" "2018-01-08" "2018-01-09" "2018-01-10"
## [11] "2018-01-11" "2018-01-12"## 2001-07-01 2001-07-02 2001-07-03 2001-07-04 2001-07-05 2001-07-06 2001-07-07
## 3 6 5 3 4 3 5
## 2001-07-08 2001-07-09 2001-07-10 2001-07-11 2001-07-12
## 5 4 4 5 5时间下标的开始和结尾时间用start()和end()访问:
## [1] "2018-01-01"## [1] "2018-01-12"用
可以读取序列中的一段, 或进行修改。 如
## 2018-01-09 2018-01-10 2018-01-11 2018-01-12
## 4 4 5 5## 2018-01-01 2018-01-02 2018-01-03
## 3 6 5zoo序列也支持lag()函数和diff()函数。
为了生成z.1序列的滞后一期序列,做法如
## z.1 stats::lag(z.1, k = -1)
## 2018-01-01 3 NA
## 2018-01-02 6 3
## 2018-01-03 5 6
## 2018-01-04 3 5
## 2018-01-05 4 3
## 2018-01-06 3 4
## 2018-01-07 5 3
## 2018-01-08 5 5
## 2018-01-09 4 5
## 2018-01-10 4 4
## 2018-01-11 5 4
## 2018-01-12 5 51.5.10 zoo序列的缺失值处理
缺失值对实际统计工作造成很大的麻烦,
金融时间序列中也包含许多缺失值。
对zoo时间序列,
可以用na.omit(),
na.contiguous(),
na.approx(),
na.spline(),
na.locf()等函数处理。
na.omit()可以删去含有缺失值的时间点。
na.contiguous()则从整个序列中抽取处连续无缺失的最长的一段。
na.locf()将缺失值用时间更早的一个最近非缺失值插补,
函数名是last observation carried forward的缩写。
na.approx()作线性插值,
na.spline()作样条插值。
这三个函数都会删去序列最开始处的缺失观测。
插值函数的横坐标默认使用日期时间的数值,
也可以利用选项改为默认两个观测之间等间隔。
1.5.11 zoo序列的滚动计算
对时间序列经常计算像七日均线这样的滑动平均。
对于一般的向量,
基本R的函数filter()可以进行各种加权滑动平均和自回归迭代计算。
zoo包对zoo时间序列和ts时间序列提供了rollapply()函数,
可以计算包括滑动平均在内的多种滚动计算。
格式为
其中data是输入序列,
width指定滚动窗口的时间点数,
FUN指定对滚动窗口的每一个位置的子集计算的函数。
结果的时间点对准窗口的中点,
可以选项align="right"指定结果的时间点对准窗口的最后一个时间点。
例如,每5个时间点计算标准差, 每次向前滚动一个时间点, 标准差的时间点对准5个点的中间一个的时间:
## 2018-01-01 2018-01-02 2018-01-03 2018-01-04 2018-01-05 2018-01-06 2018-01-07
## 3 6 5 3 4 3 5
## 2018-01-08 2018-01-09 2018-01-10 2018-01-11 2018-01-12
## 5 4 4 5 5## 2018-01-03 2018-01-04 2018-01-05 2018-01-06 2018-01-07 2018-01-08 2018-01-09
## 1.3038405 1.3038405 1.0000000 1.0000000 0.8366600 0.8366600 0.5477226
## 2018-01-10
## 0.5477226加fill=NA选项使得没有结果的时间点也出现在结果中:
## 2018-01-01 2018-01-02 2018-01-03 2018-01-04 2018-01-05 2018-01-06 2018-01-07
## NA NA 1.3038405 1.3038405 1.0000000 1.0000000 0.8366600
## 2018-01-08 2018-01-09 2018-01-10 2018-01-11 2018-01-12
## 0.8366600 0.5477226 0.5477226 NA NA对一些常用的滚动计算zoo包含提供了单独的函数,
如
rollmean(), rollmedian(), rollmax(), rollsum(),
这几个是结果时间点对应滚动窗口中心的。
而rollmeanr(), rollmedianr(), rollmaxr(), rollsumr()
则是结果时间点对准滚动窗口末尾时间点的。
1.6 xts类型
1.6.1 xts类型的设计目标
xts包的设计目标是使得以xts为输入的函数可以兼容其它时间序列类型的输入, 并可以很方便地增加属性。
xts包提供了xts时间序列类型, 这本质上是zoo包的zoo类型, 所以针对zoo类型的做法也适用于xts类型。
xts类型与zoo类型的差别如下:
xts类型必须使用正式的时间类型作为时间下标, zoo类型的时间下标更普遍。 xts目前仅允许使用Date, POSIXct, chron, yearmon, yearqtr, timeDate作为时间下标。
xts包含一些独有的内部属性, 包括
.CLASS,.ROWNAMES等。 这是为了能够无损地与其他时间序列类型互相转换而保存的其它时间序列类型的部分额外信息。xts具有用户添加属性。 这使得xts类型是用户可定制的数据类型, 用户可以随意添加或者删除自定义属性, 不会影响到数据的显示和计算。 与其他时间序列类型互相转换所需的部分额外信息也保存为用户添加属性。
1.6.2 xts类型数据的构建
可以用xts()生成新的xts时间序列类型的数据对象,
用法类似用zoo::zoo()。
如
library(xts, quietly = TRUE)
xts.1 <- xts(
c(5, 5, 4, 6, 4, 3, 3, 3, 4, 5, 5, 4),
make_date(2018, 1, 1) + ddays(0:11)); xts.1## [,1]
## 2018-01-01 5
## 2018-01-02 5
## 2018-01-03 4
## 2018-01-04 6
## 2018-01-05 4
## 2018-01-06 3
## 2018-01-07 3
## 2018-01-08 3
## 2018-01-09 4
## 2018-01-10 5
## 2018-01-11 5
## 2018-01-12 4## An 'xts' object on 2018-01-01/2018-01-12 containing:
## Data: num [1:12, 1] 5 5 4 6 4 3 3 3 4 5 ...
## Indexed by objects of class: [Date] TZ: UTC
## xts Attributes:
## NULL其它时间序列类型可以用as.xts()转换成xts类型,如
## [,1]
## 2018-01-01 3
## 2018-01-02 6
## 2018-01-03 5
## 2018-01-04 3
## 2018-01-05 4
## 2018-01-06 3
## 2018-01-07 5
## 2018-01-08 5
## 2018-01-09 4
## 2018-01-10 4
## 2018-01-11 5
## 2018-01-12 51.6.3 xts类型数据的子集
首先, xts类型支持zoo类型的用法。
若x是xts类型,
则x[i]可以取出行子集,
x[i,j]可以取出行、列子集,
其中i可以是整数下标,
还可以是包含日期时间的字符串向量,
日期时间类型的向量等。
日期时间字符串的格式为CCYY-MM-DD HH:MM:SS,
而且可以省略后面的一部分,
其含义是取出前面部分能匹配的所有时间点,
这种设计使得取出某年、某月的数据变得十分方便。
如
## [,1]
## 1月 1949 112
## 2月 1949 118
## 3月 1949 132
## 4月 1949 129
## 5月 1949 121
## 6月 1949 135
## 7月 1949 148
## 8月 1949 148
## 9月 1949 136
## 10月 1949 119
## 11月 1949 104
## 12月 1949 118又比如,设x是某个股票的每分钟的数据,
则x["2018-01-18 08"]取出2018-1-18 8:00-9:00之间的所有数据。
也可以用"from/to"的格式指定一个日期时间范围,
而且也不需要开始点和结束点恰好有数据,
from和to的时间精度也不需要与数据的实际采样频率相同。
省略from则从头开始,
省略to则直到末尾。
如
## [,1]
## 2018-01-10 5
## 2018-01-11 5
## 2018-01-12 4first(x, n)和last(x, n)类似于head(x, n)和last(x, n),
但是对xts对象x,n除了可以取正整数值以外,
还允许用字符串指定时间长度,
允许的单位包括
secs, seconds, mins, minutes, hours, days, weeks, months, quarters, years。
比如,取出开头的三个月:
## [,1]
## 1月 1949 112
## 2月 1949 118
## 3月 1949 132字符串中取负值时表示扣除,如扣除开始的三个月:
## [1] "4月 1949"取出的单位可以是比实际采样频率更大的时间单位,
比如,
分钟数据可以用last(x, "1 day")取出最后一天的的所有数据。
但是,取出的单位不能比实际采样频率更小,
比如,日数据不能用小时单位取出。
如果x是从其它类型转换得到的,
即使取了x的子集或者进行了一些其他的操作,
也可以尝试用reclass()函数恢复原来的类型。
1.6.4 支持的时间标签类型
xts的时间下标也可以是一个日期或者日期时间类型的向量。
支持的类型包括
Date, POSIXct, chron, yearmon, yearqtr, timeDate。
可以沿用zoo的index()函数来读取或者修改xts类型的时间下标。
比如, 对季度数据, 如果原来的时间标签是Date或POSIXct, 可以用如下的方法修改时间标签的数据类型:
as.yearmon()可以转换为月度格式。
1.6.5 xts类型数据的图形
若x是xts时间序列,
plot(x)会自动选择适当的x轴刻度作图,
这个函数是仿照quantmod::chartSeries()制作的。
如
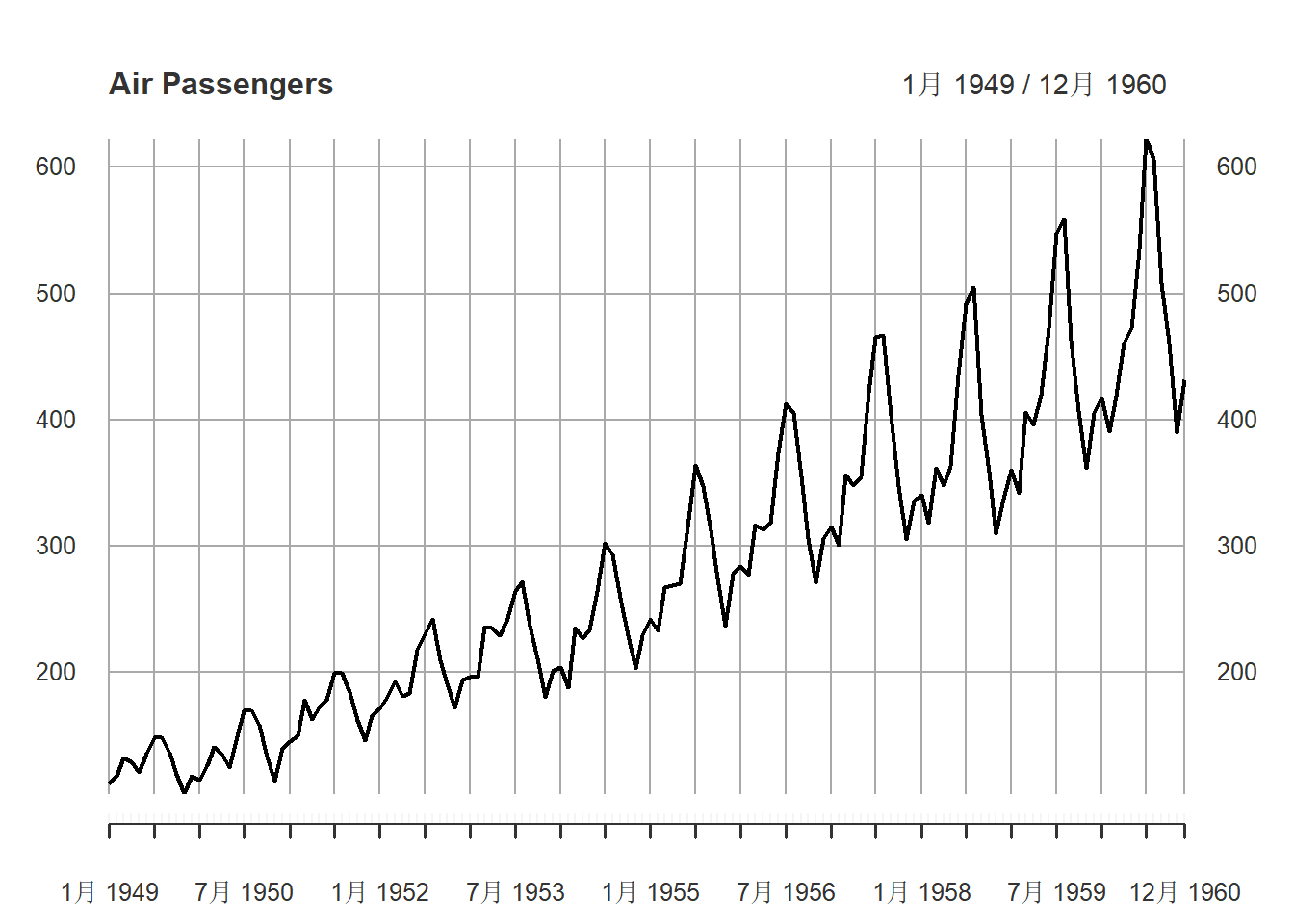
可以用major.ticks和minor.ticks为x轴指定适当的粗刻度(有数值标注的)和细刻度,
用grid.ticks.on指定x轴的格子线的频率,
用format.labels="%Y"使得x轴刻度仅包含年份。
如
plot(xts.ap, main="Air Passengers",
major.ticks="years", minor.ticks=NULL,
grid.ticks.on="years", format.labels="%Y",
col="red")
对xts对象的plot()函数还可以用subset选项指定一个子集范围,
用multi.panel=TRUE要求多元时间序列的每个分量在单独的坐标系中作图,
等等。
1.6.6 xts的一些方便函数
1.6.6.2 求某种采样频率的分界点
endpoints(x, on)给出按某种频率的分界点,
频率包括"us"(微秒), "microseconds",
"ms"(毫秒), "milliseconds",
"secs", "seconds",
"mins", "minutes",
"hours", "days",
"weeks", "months", "years"。
如
## [1] 0 12 24 36 48 60 72 84 96 108 120 132 144结果是分组用的坐标, 对输出\(t_0, t_1, \dots, t_n\), \((t_{i-1}, t_i], i=1,2,\dots,n\)是结果分出的区间。
1.6.6.3 降频函数
对于OHLC形式的金融时间序列,
即开盘价(open)、最高价(high)、最低价(low)、收盘价(close)四个成分的时间序列,
并且成分变量名也采用Open, High, Low, Close,
可以用to.period(x, period)将其降频成period指定的采样频率。
比如,对分钟数据x,
可以用to.period(x, period="days")降频成日数据。
降频后时间点一般采用每个周期内最后一个时间点,
可以用indexAt选项指定其他的时间点选择。
如果x是分钟数据,
to.minutes3(x),
to.minutes5(x),
to.minutes10(x),
to.minutes15(x),
to.minutes30(x),
to.hourly(x)
将x降频为3分钟到60分钟的数据。
to.daily(x)将x降频为每天的数据,
并在时间下标中删去时间部分。
to.weekly(x)将x降频为每周的数据,
并在时间下标中删去时间部分,
日期采用每周最后一天(周六)的日期。
to.monthly(x)将x降频到月度数据并将时间下标改为yearmon类型,
toquarterly(x)将x降频到季度数据并将时间下标改为yearqtr类型。
toyearly(x)将x降频到年度数据,日期采用每年有数据的最后一天的日期。
如果数据中原来有成交量, 这些降频函数也会计算合并的成交量。
如果x是一元时间序列,
to.period(x, period)可以将其降频并得到OHLC四个序列,
比如,从收盘价日数据可以降频得到周数据的开盘、最高、最低、收盘,
但是并不是严格意义上的开盘、最高、最低。
1.6.6.4 周期操作函数
用period.apply(x, INDEX, FUN)可以用INDEX对时间序列x分组,
对每组用FUN函数计算一个函数值。
INDEX常取为endpoints(x, on="..."),
给出某种分组周期。
比如,
计算每年航空旅客人数的月平均值:
## [,1]
## 12月 1949 126.6667
## 12月 1950 139.6667
## 12月 1951 170.1667
## 12月 1952 197.0000
## 12月 1953 225.0000
## 12月 1954 238.9167
## 12月 1955 284.0000
## 12月 1956 328.2500
## 12月 1957 368.4167
## 12月 1958 381.0000
## 12月 1959 428.3333
## 12月 1960 476.1667常用操作如求和等有专门的函数,
如period.sum(), period.min(),
period.max(), period.prod()。
专用函数运行效率更高。
常用的周期也有专门的函数,
如apply.daily(), apply.weekly(),
apply.monthly(), apply.quarterly(),
apply.yearly()。
这些函数实际是调用period.apply()。
1.7 tsibble类型
tsibble包提供了tsibble类型, 这是遵从tidyverse理念的一种时间序列类型, 基于tibble类型(tibble是R中数据框的基本类型)。 tsibble将时间标签作为tibble数据框的一列保存, 称为索引(index), 还可以有一个或多个键(key)变量, 用来代表不同的时间序列分量, 表示时间的索引与键变量共同唯一区分不同观测(行)。 其他列可以是时间序列数据也可以包含一般信息, 还允许为列表类型。
如果有多个序列(比如多只股票的价格), 可以将这些序列保存在不同变量中, 也可以保存在同一变量中, 并使用键变量值来区分。
tsibble包提供了时间序列数据管理功能, 并可以充分利用tidyverse的各种工具进行方便地处理计算。
1.7.1 从文本文件读入
以m-ibmsp-2611.txt为例,先读入为tibble数据框,
再用as_tsibble()函数转换,
用index=指定那一列是日期:
library(tsibble)
d <- read_table(
"m-ibmsp-2611.txt",
col_types=cols(
.default=col_double(),
date=col_date(format="%Y%m%d")))
d |>
mutate(date = yearmonth(date)) |>
as_tsibble(index="date") -> ibm_tsib
head(ibm_tsib)## # A tsibble: 6 x 3 [1M]
## date ibm sp
## <mth> <dbl> <dbl>
## 1 1926 1月 -0.0104 0.0225
## 2 1926 2月 -0.0245 -0.0440
## 3 1926 3月 -0.116 -0.0591
## 4 1926 4月 0.0898 0.0227
## 5 1926 5月 0.0369 0.00768
## 6 1926 6月 0.0685 0.0432上述结果中\(t \times 3\)表示数据有6行、3列, 时间单位是一个月。 这个tsibble中有两个时间序列, 分别存在两列中, 没有使用键变量。
tsibble类型允许在同一列中保存时间序列的不同分量, 比如,将上面的ibm和sp保存在同一列中, 这需要用键变量指定区分不同分量,如:
d1 <- d |>
pivot_longer(
cols = c("ibm", "sp"),
names_to="series",
values_to="value")
ibm_tsib2 <- as_tsibble(
d1, index="date", key="series")
ibm_tsib2 |>
group_by(series) |>
slice_head(n=2) |>
knitr::kable()| date | series | value |
|---|---|---|
| 1926-01-30 | ibm | -0.010381 |
| 1926-02-27 | ibm | -0.024476 |
| 1926-01-30 | sp | 0.022472 |
| 1926-02-27 | sp | -0.043956 |
1.7.2 时间标签类型
tsibble包单独提供了yearmon,
yearquarter,
yearweek等函数用于生成月度、季度、周频时间。
这些函数可以输入Date类型然后返回tsibble定义的月频等类型。
tsibble保存的基本上都是规则时间间隔的时间序列。
在生成tsibble时,
如果数据是月度或季度数据,
应将index转换为yearmon或yearquarter类型,
见1.7.1的程序。
不同的时间标签类型代表了数据的周期性(或称季节性)的不同, 后续用ETS、ARIMA等函数建模时需要这些周期性新息。
对于金融中常见的日数据, 因为受周末和节假日影响, 所以时间不是连续的, 而与tsibble类型配合的fable, feasts, fabletools等扩展包建模时一般要求时间间隔为等间隔。 为此, 对日数据, 可以将具体日期保留, 但新生成一个行号列, 以行号列为tsibble的index列。
例如,
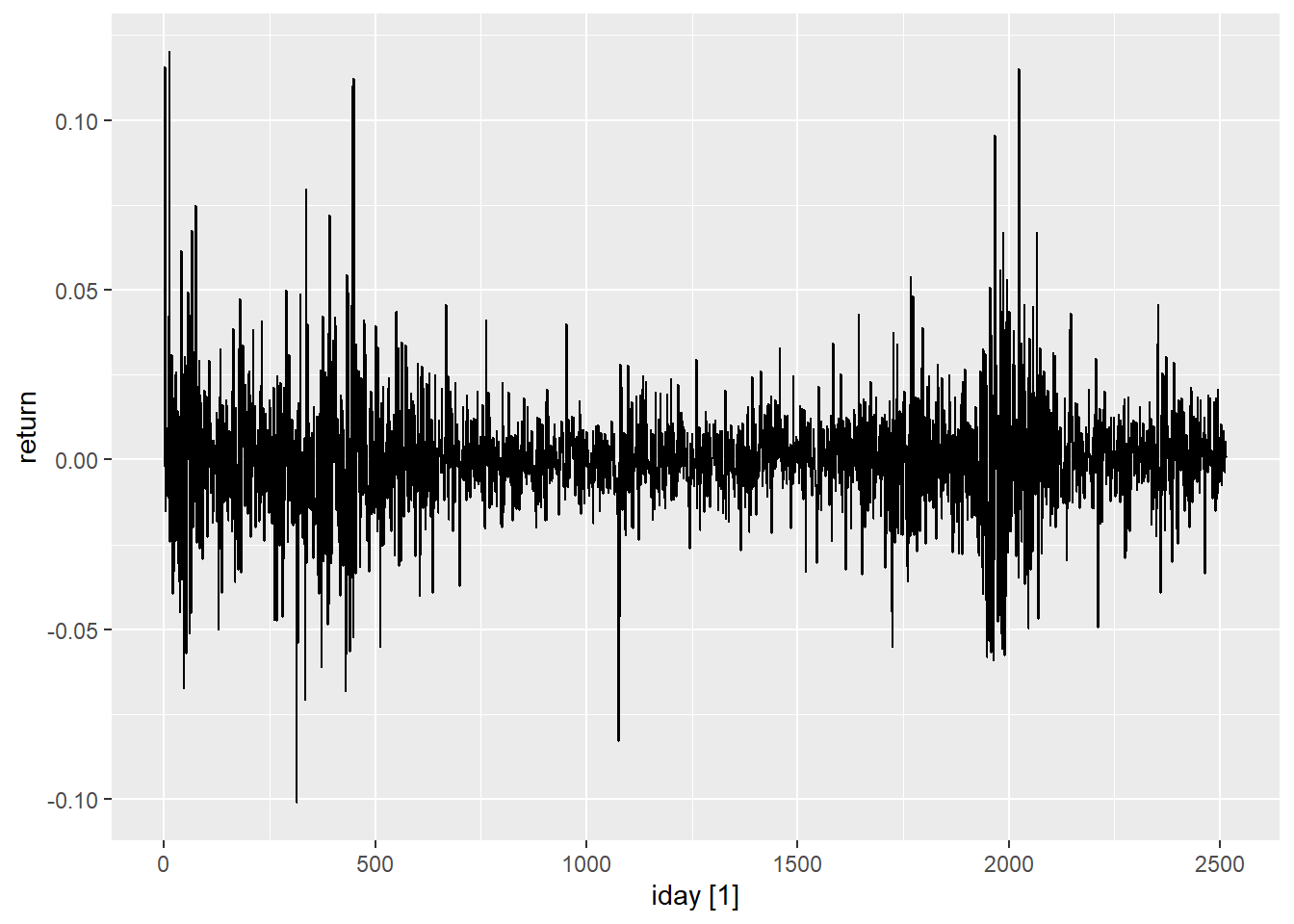
文件d-ibm-0110.txt中保存了IBM股票从2001-1-2到2010-12-31的日简单收益率。
读入为tsibble并设置以序号为index:
tb_ibm_day <- read_table("d-ibm-0110.txt",
col_types = cols(
.default = col_double(),
date = col_date("%Y%m%d") )) |>
mutate(iday = row_number()) |>
as_tsibble(index=iday)
knitr::kable(head(tb_ibm_day))| date | return | iday |
|---|---|---|
| 2001-01-02 | -0.002206 | 1 |
| 2001-01-03 | 0.115696 | 2 |
| 2001-01-04 | -0.015192 | 3 |
| 2001-01-05 | 0.008719 | 4 |
| 2001-01-08 | -0.004654 | 5 |
| 2001-01-09 | -0.010688 | 6 |
对已经保存为tsibble的数据,
如果要修改其索引变量,
可以用update_tsibble()函数,
用index参数指定新的索引变量,
可以用regular=TRUE表示这样得到的时间序列是等间隔的。
1.7.3 管道和分组处理
tsibble支持tidyverse的管道运算,
支持group_by,
这时一般按key变量分组,
见1.7.1中的程序。
还可以用aggregate_key()函数按照指定的键变量分组汇总。
还支持index_by,
可以按将多个时间汇总分组。
例1.1 tsibble包的tourism变量是一个tsibble, 其中包含了1998年到2016年澳大利亚境内旅游人次(Trips)的详细季度数据, 共76个季度。 用键变量State区分州, 用键变量Region区分地区(州下面一级行政区划), 用键变量Purpose区分旅行目的。 进行汇总演示。
解答: 获得全国的每季度总旅行人次数:
## # A tsibble: 80 x 2 [1Q]
## Quarter Trips
## <qtr> <dbl>
## 1 1998 Q1 23182.
## 2 1998 Q2 20323.
## 3 1998 Q3 19827.
## 4 1998 Q4 20830.
## 5 1999 Q1 22087.
## 6 1999 Q2 21458.
## 7 1999 Q3 19914.
## 8 1999 Q4 20028.
## 9 2000 Q1 22339.
## 10 2000 Q2 19941.
## # ℹ 70 more rows注意汇总是自动按不同时间索引值(季度)分组的。
下面用index_by()指定按年汇总:
## # A tsibble: 20 x 2 [1Y]
## Year Trips
## <dbl> <dbl>
## 1 1998 84162.
## 2 1999 83488.
## 3 2000 83951.
## 4 2001 84252.
## 5 2002 86387.
## 6 2003 85042.
## 7 2004 85608.
## 8 2005 79215.
## 9 2006 82866.
## 10 2007 83563.
## 11 2008 80709.
## 12 2009 76447.
## 13 2010 78332.
## 14 2011 81212.
## 15 2012 83402.
## 16 2013 84692.
## 17 2014 94230.
## 18 2015 97449.
## 19 2016 101485.
## 20 2017 107710.程序中~ year(.)是表示将键变量值按年分组,
其中的.表示键变量值。
为了将所有时间汇总在一起, 需要将tsibble转换为tibble再汇总,如
## # A tibble: 8 × 2
## State Trips
## <chr> <dbl>
## 1 ACT 41007.
## 2 New South Wales 557367.
## 3 Northern Territory 28614.
## 4 Queensland 386643.
## 5 South Australia 118151.
## 6 Tasmania 54137.
## 7 Victoria 390463.
## 8 Western Australia 147820.用group_by()按州和时间索引分组,
获得每个州每季度的总旅游人次数:
## # A tsibble: 640 x 3 [1Q]
## # Key: State [8]
## State Quarter Trips
## <chr> <qtr> <dbl>
## 1 ACT 1998 Q1 551.
## 2 ACT 1998 Q2 416.
## 3 ACT 1998 Q3 436.
## 4 ACT 1998 Q4 450.
## 5 ACT 1999 Q1 379.
## 6 ACT 1999 Q2 558.
## 7 ACT 1999 Q3 449.
## 8 ACT 1999 Q4 595.
## 9 ACT 2000 Q1 600.
## 10 ACT 2000 Q2 557.
## # ℹ 630 more rowsfabletools包提供了一个aggregate_key()函数,
这个函数可以指定键变量嵌套分组以及交叉组合,
按这些分组进行汇总,
如果有嵌套或者交叉,
也进行嵌套的外层汇总和交叉的每一个分组变量的汇总。
如:
## # A tsibble: 6,800 x 4 [1Q]
## # Key: State, Region [85]
## Quarter State Region Trips
## <qtr> <chr*> <chr*> <dbl>
## 1 1998 Q1 <aggregated> <aggregated> 23182.
## 2 1998 Q2 <aggregated> <aggregated> 20323.
## 3 1998 Q3 <aggregated> <aggregated> 19827.
## 4 1998 Q4 <aggregated> <aggregated> 20830.
## 5 1999 Q1 <aggregated> <aggregated> 22087.
## 6 1999 Q2 <aggregated> <aggregated> 21458.
## 7 1999 Q3 <aggregated> <aggregated> 19914.
## 8 1999 Q4 <aggregated> <aggregated> 20028.
## 9 2000 Q1 <aggregated> <aggregated> 22339.
## 10 2000 Q2 <aggregated> <aggregated> 19941.
## # ℹ 6,790 more rows其中的State / Region的写法表示Region是嵌套在State内部的。
因为tourism有State, Region, Purpose三个键变量,
所以针对每个State和Region组合值,
将不同Purpose进行了汇总,
结果中不再含有Purpose键变量;
另外,
每个州有汇总值,
全国有汇总值。
程序的结果产生了许多新的键值,
在aggregate_key()中用*表示两个分组变量交叉分组,
如aggregate_key(~ State * Purpose, Trips = sum(Trips))。
在使用这样多层汇总过的复杂数据时,
可以在dylyr::filter()中用is_aggregated(Region)选取不分区域(即每个州以及全国)的汇总数据,
用is_aggregated(State)选取全国的汇总数据。
1.7.4 作图
1.7.4.1 时间序列图
将AirPassengers转换为tsibble:
两个变量为index和value。
作图:
library(tsibble)
#library(feasts)
#library(ggplot2)
#library(fable)
#library(fabletools)
print(search())## [1] ".GlobalEnv" "package:fable" "package:feasts"
## [4] "package:fabletools" "package:quantmod" "package:TTR"
## [7] "package:xts" "package:zoo" "package:tsibble"
## [10] "package:lubridate" "package:forcats" "package:stringr"
## [13] "package:dplyr" "package:purrr" "package:readr"
## [16] "package:tidyr" "package:tibble" "package:ggplot2"
## [19] "package:tidyverse" "package:stats" "package:graphics"
## [22] "package:grDevices" "package:utils" "package:datasets"
## [25] "package:methods" "Autoloads" "package:base"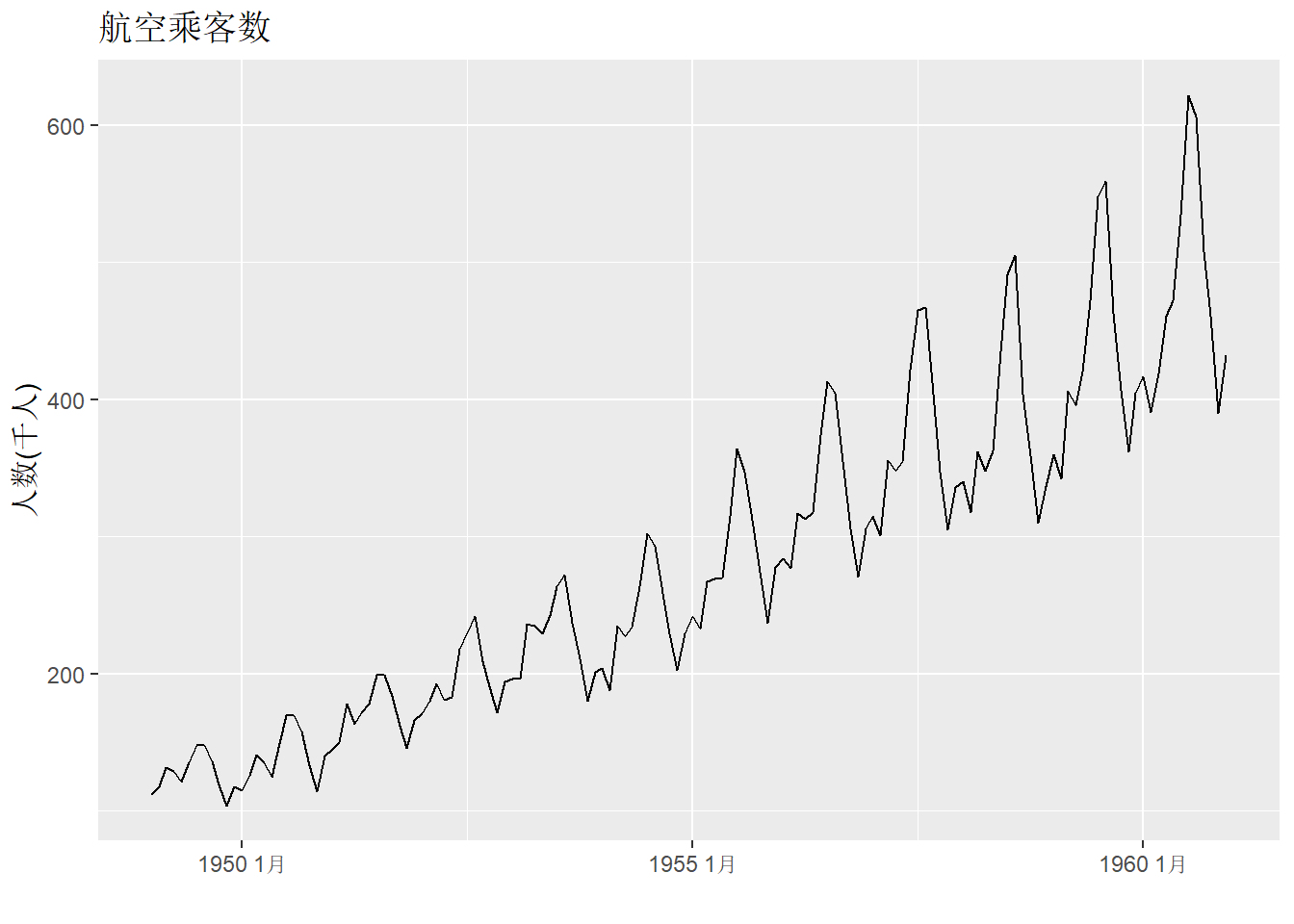
图形是基于ggplot2包的, 所以可以用ggplot2的函数进行修改。
1.7.4.2 逐年折线图
对于月度、季度等含有固定季节的数据, 可以每年作一条折线图。 如:
library(feasts)
apt |>
gg_season(value, labels="both") +
labs(y = "人数(千人)",
x = "",
title = "航空乘客数逐年图形")
这样可以更清楚地看出数据如何随季节变化, 以及不同年份的差别。
对于比较高频的数据,
比如每小时的数据,
其周期可能有多个,
比如每天、每周、每年。
这时在gg_season()中可以用period = "week"这样的方法指定要绘图的季节性。
例如,
tsibbledata包的vic_elec是澳大利亚用电量时间序列数据,
时间间隔为每半小时,
其中变量Demand是以兆瓦时为单位的用电量,
Temperature为墨尔本气温,
Holiday是是否公共节假日的指示变量。
以每天为周期绘制逐天折线图:
data(vic_elec, package="tsibbledata")
vic_elec |>
gg_season(Demand, period="day", alpha=0.2) +
theme(legend.position = "none") +
labs(y="MWh", title="Electricity demand: Victoria")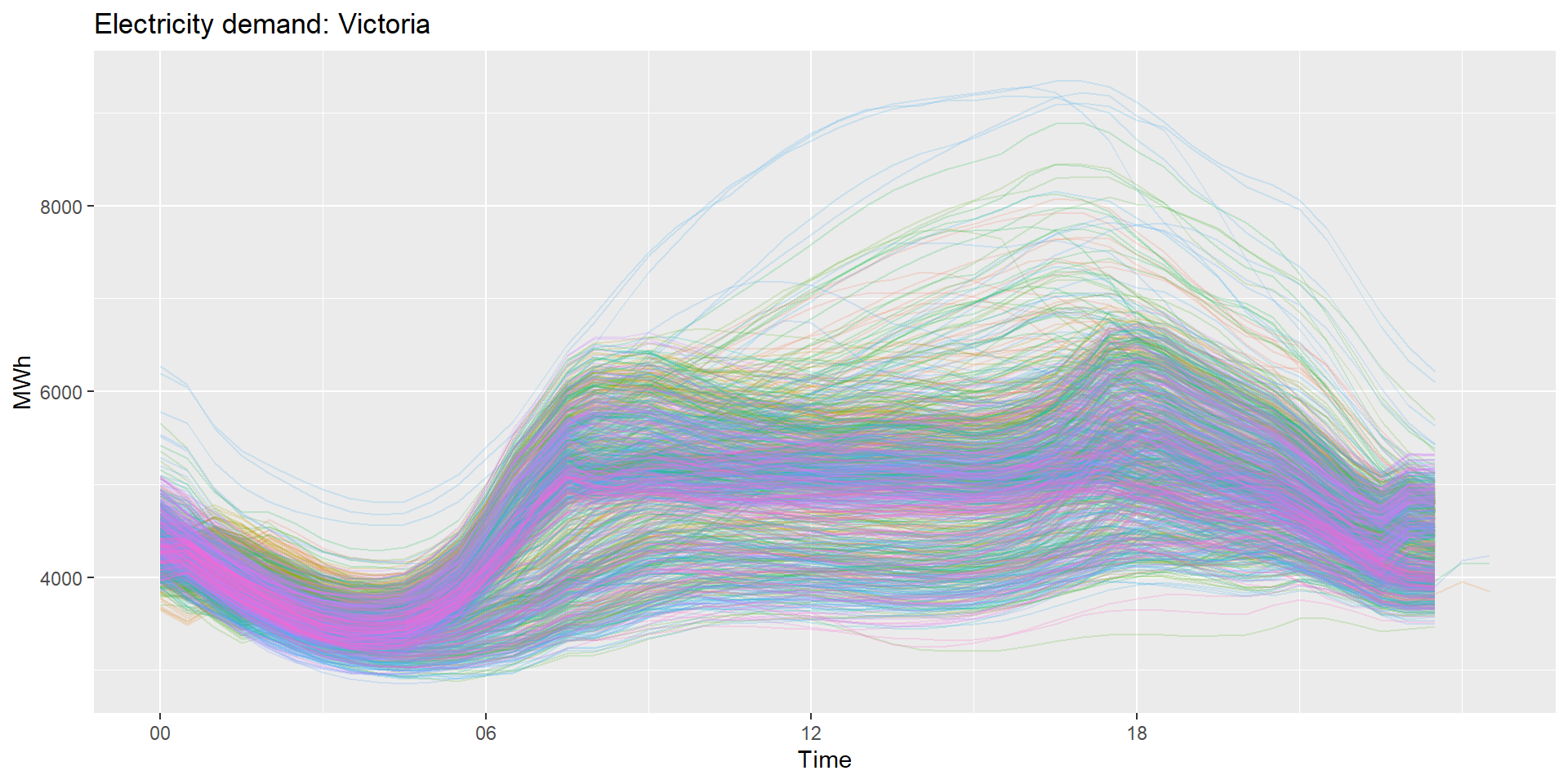
以周为周期作逐周的折线图:
vic_elec |>
gg_season(Demand, period="week", alpha=0.3) +
theme(legend.position = "none") +
labs(y="MWh", title="Electricity demand: Victoria")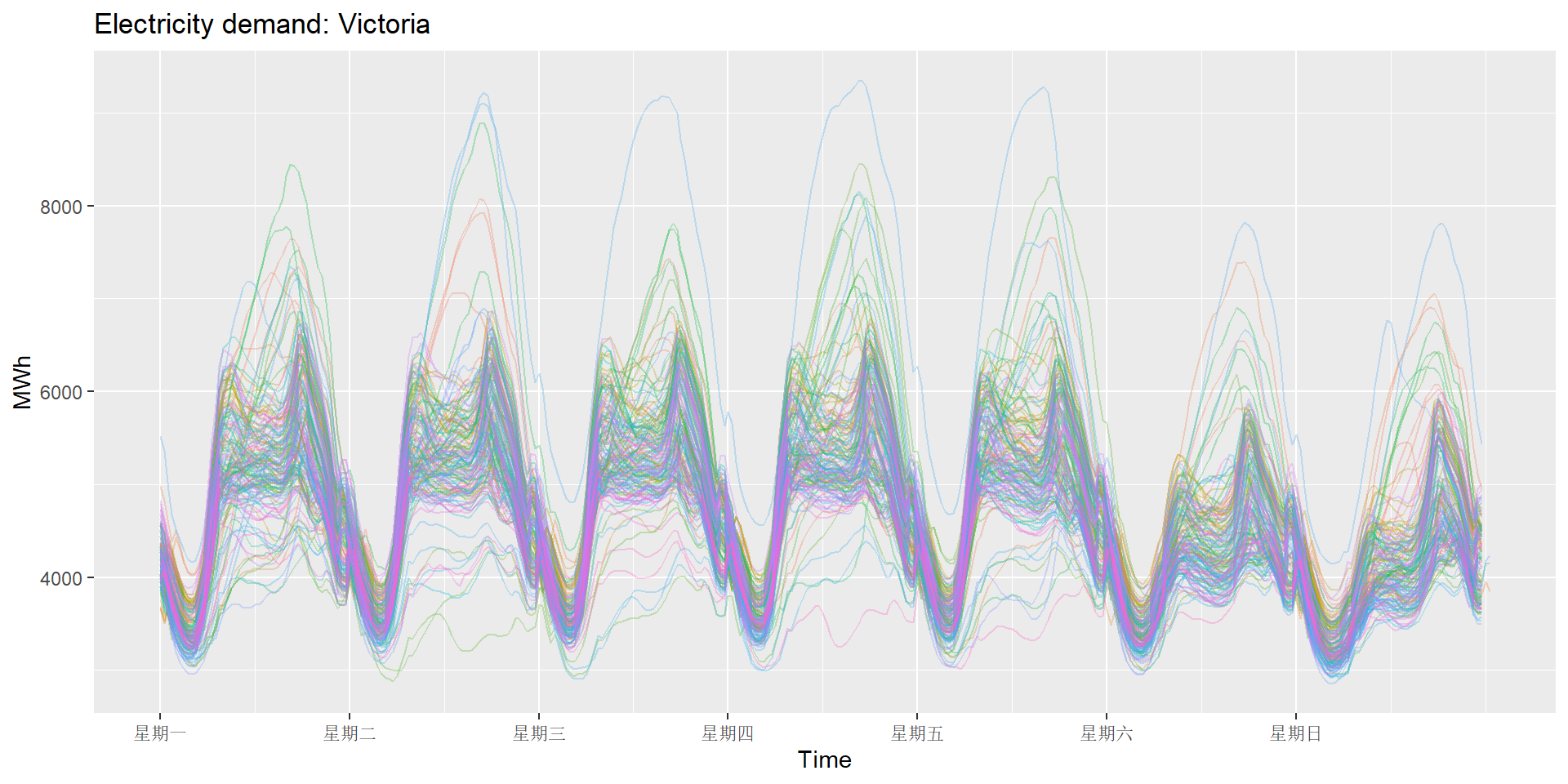
如果以年为周期作逐年的折线图, 每年观测点数太多, 折线会互相遮挡, 所以汇总成每天的用电量:
vic_elec |>
index_by(Date) |>
summarise(Demand = sum(Demand)/1000) |>
gg_season(Demand, period="year", alpha=0.5) +
labs(y="kMWh", title="Electricity demand: Victoria")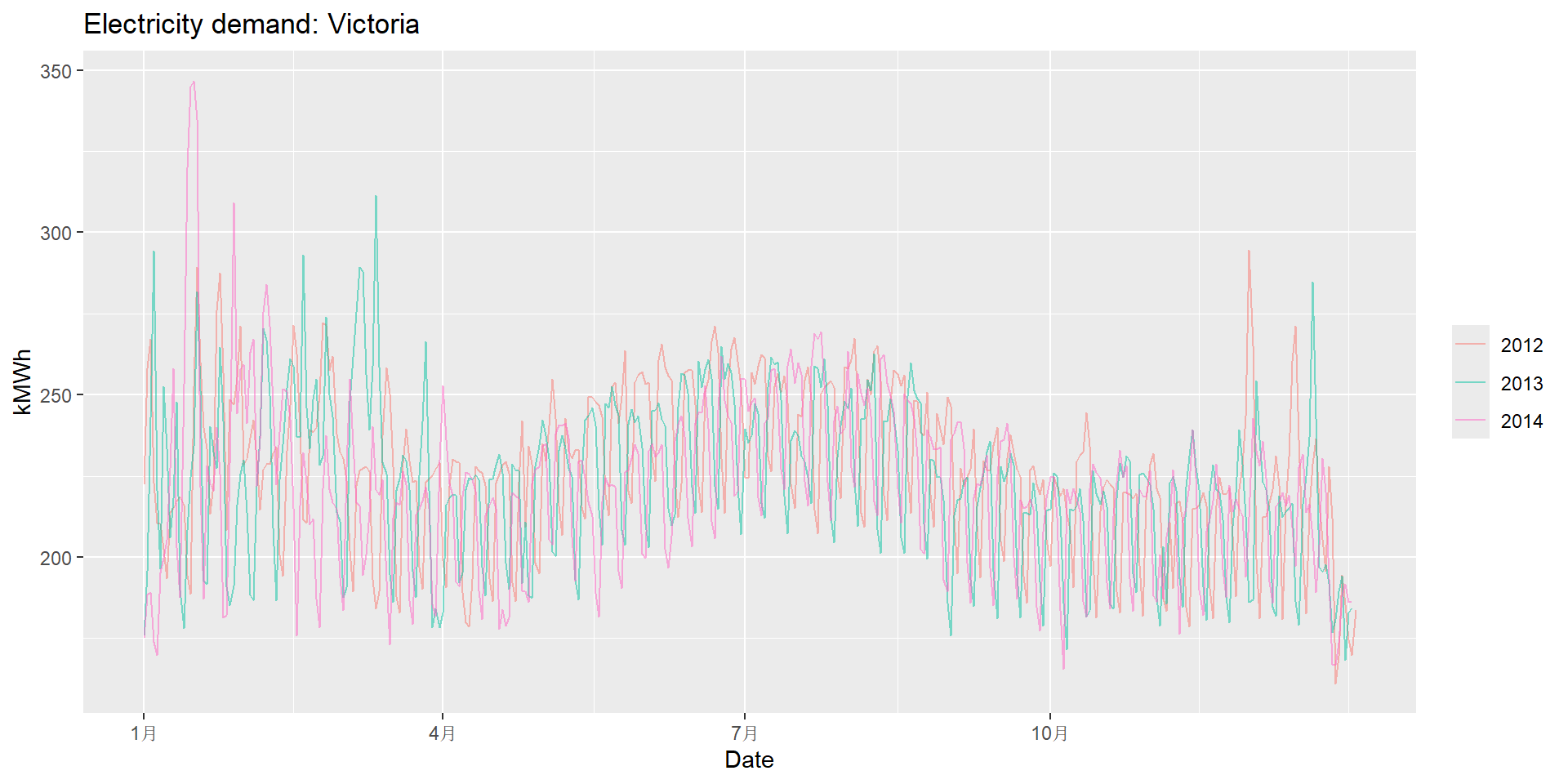

1.7.4.4 散点图
两个子序列之间可以作散点图。
比如,
vic_elec中有用电量和温度,作用电量对温度的散点图:
vic_elec |>
filter(year(Time) == 2014) |>
ggplot(aes(x = Temperature, y = Demand)) +
geom_point(size=0.2, alpha=0.2) +
labs(title="Electricity demand versus Temperature",
x = "Temperature (degrees Celsius)",
y = "Electricity demand (GWh)")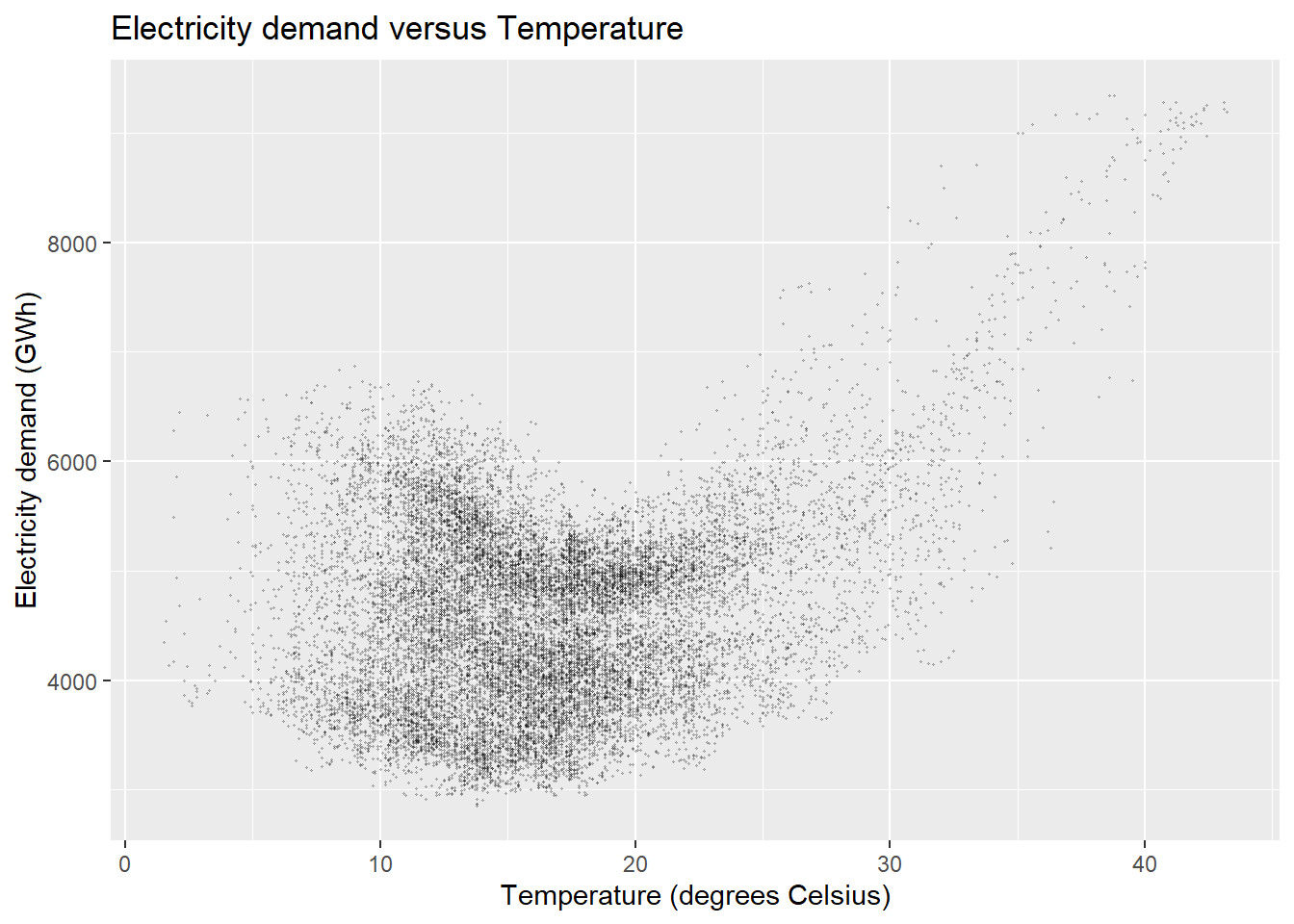
在有多个时间序列并且放在不同列时,
可以用GGally::ggpairs()作散点图矩阵。
如果将不同序列合并放在了同一列并用key变量区分,
可以先用tidyr::pivot_wider转换为每个序列占据不同列,
然后再作散点图矩阵。
1.7.4.5 滞后图
时间序列\(\{X_t \}\)的不同时间之间存在相关性, 可以用\((X_{t-l}, X_t)\)为坐标画散点图, 称为滞后图, 用来考察\(X_t\)与滞后值\(X_{t-l}\)之间的关系。
以可口可乐1983-2009盈利季度数据为例。
readr::read_table(
"q-ko-earns8309.txt",
col_types = cols(
.default = col_double(),
pends = col_date(format="%Y%m%d"),
anntime = col_date(format="%Y%m%d"),
value = col_double()
)) |>
select(-anntime) |>
mutate(pends = yearquarter(pends)) |>
as_tsibble(index = pends) -> kot
autoplot(kot, value) +
labs(x = "", y = "Earnings",
title = "Coca Cola Quarterly Earnings")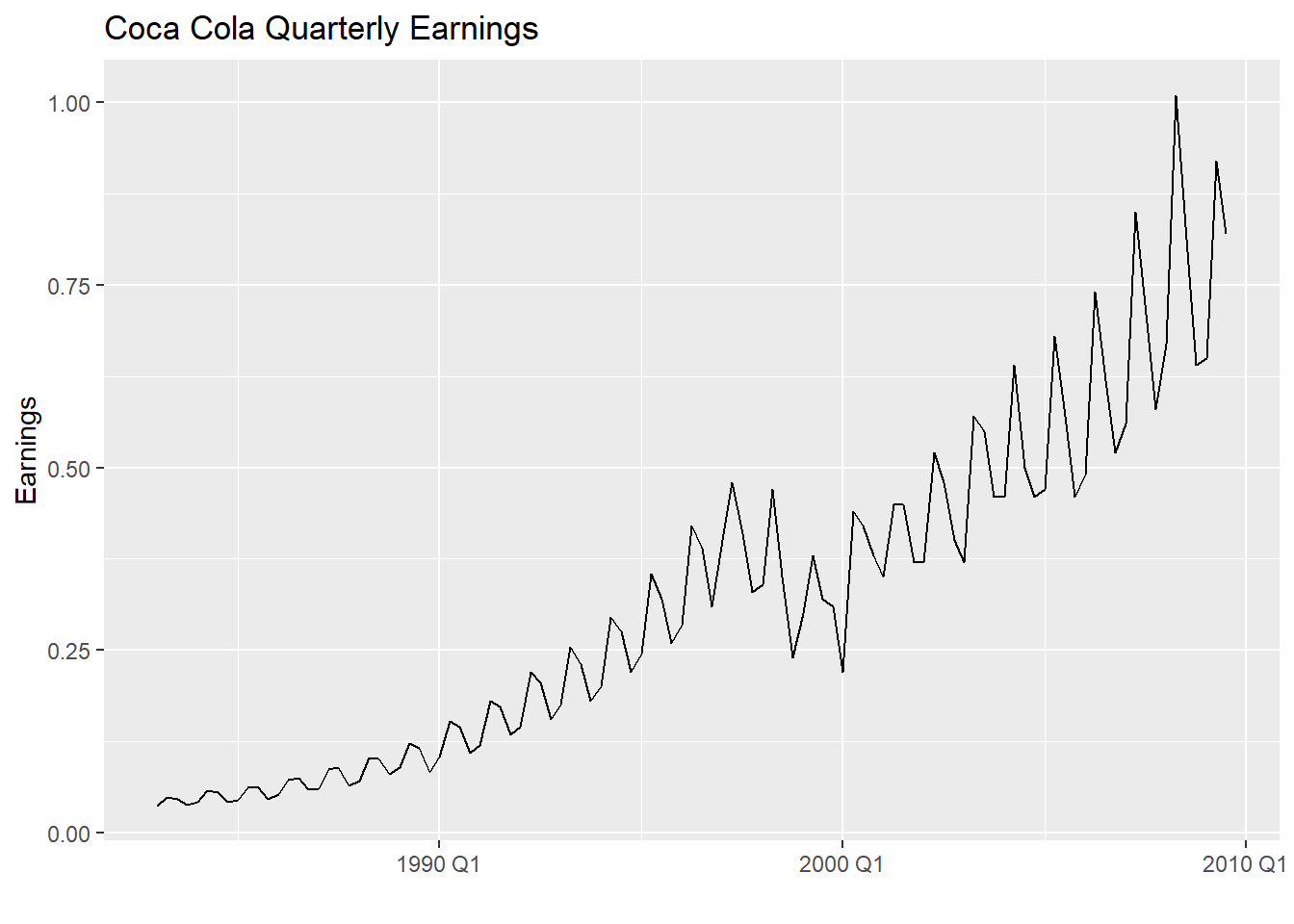
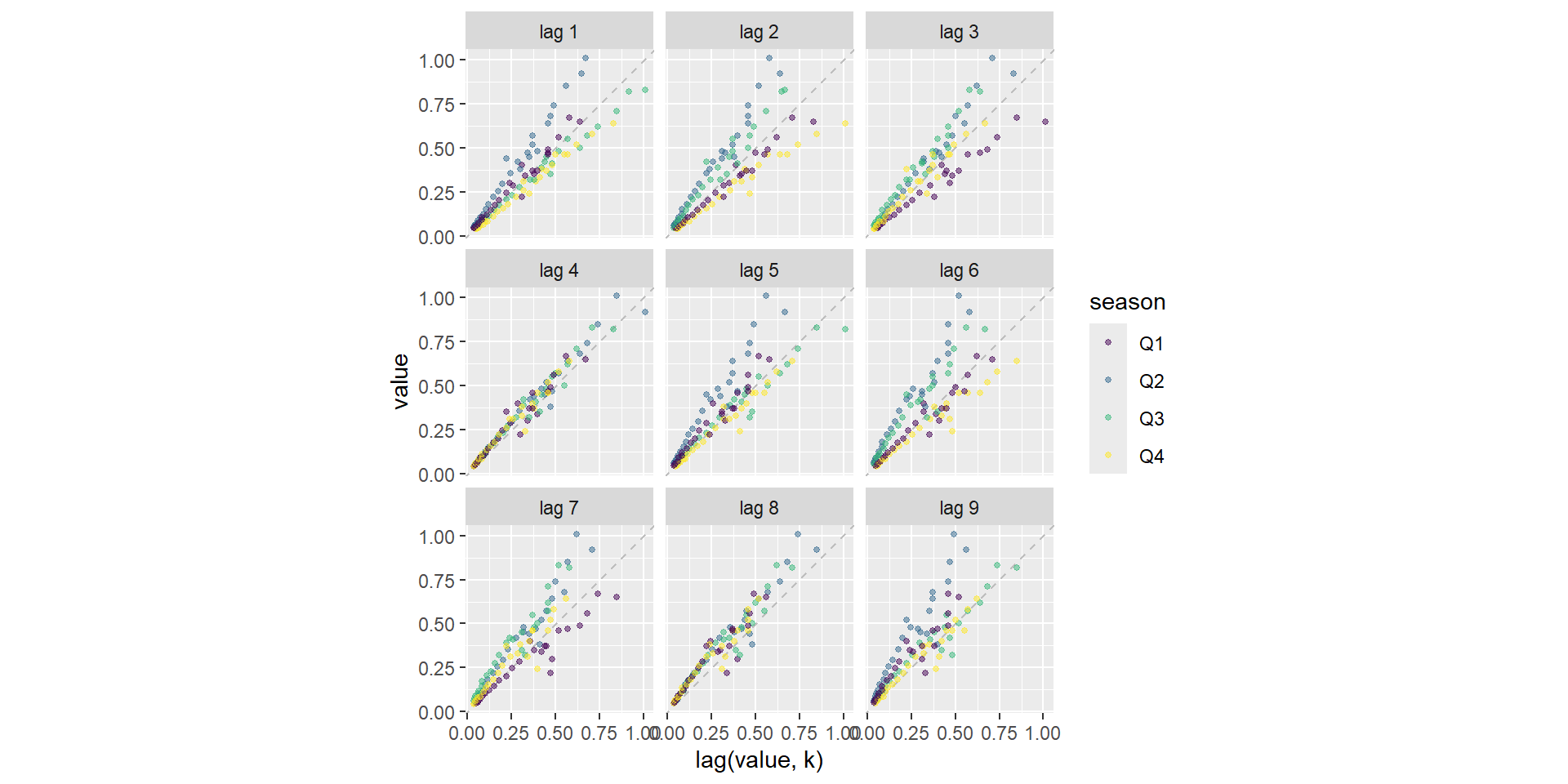
不同季度使用了不同颜色。 纵坐标是\(X_t\)的值, 横坐标是\(X_{t-k}\)的值, \(k\)取了1到9。 可以看出相关性与季度有关, 而且在滞后4和滞后8的时候相关性更强。
注意“滞后”这个词, 英文是“lag”。 对于\(X_t\)而言, \(X_{t-1}\)往往称为\(X_t\)的滞后1期的值, 但实际上\(X_{t-1}\)比\(X_t\)提前1期被观测到。 在后面讨论多元时间序列各分量之间的领先、滞后关系时, 这个问题尤其要注意。
1.8 quantmod包的功能
quantmod包的目的是为量化投资者提供方便的原型开发测试工具, 而不是提供新的统计方法。 quantmod包提供了金融时间序列数据的一些方便功能, 比如从公开数据源载入数据, 作股票行情图、时间序列图。
1.8.1 quantmod包的数据下载功能
quantmod包提供了一个getSymbols()函数,
可以从多个公开数据源下载金融和经济数据并转换为R格式(主要是xts格式),
数据源包括(有些在国内可能无法访问):
- 雅虎金融(OHLC数据)
- 圣路易斯联邦储备银行的联邦储备经济数据库(Federal Reserve Bank of St. Louis FRED®) (有11000个经济时间序列)
- Google Finance (OHLC 数据,国内连接困难)
- Oanda, The Currency Site (FX and Metals,国内连接困难)
- 本地的MySQL数据库
- R二进制格式文件(.RData 和 .rda文件)
- 逗号分隔文件 (.csv文件)
- 待开发的数据源如RODBC, Rbloomberg等
例如,从雅虎金融下载微软公司的日数据, 股票代码MSFT:
## MSFT.Open MSFT.High MSFT.Low MSFT.Close MSFT.Volume MSFT.Adjusted
## 2007-01-03 29.91 30.25 29.40 29.86 76935100 22.96563
## 2007-01-04 29.70 29.97 29.44 29.81 45774500 22.92717
## 2007-01-05 29.63 29.75 29.45 29.64 44607200 22.79642
## 2007-01-08 29.65 30.10 29.53 29.93 50220200 23.01947
## 2007-01-09 30.00 30.18 29.73 29.96 44636600 23.04254
## 2007-01-10 29.80 29.89 29.43 29.66 55017400 22.81180## An 'xts' object on 2007-01-03/2018-01-23 containing:
## Data: num [1:2784, 1:6] 29.9 29.7 29.6 29.6 30 ...
## - attr(*, "dimnames")=List of 2
## ..$ : NULL
## ..$ : chr [1:6] "MSFT.Open" "MSFT.High" "MSFT.Low" "MSFT.Close" ...
## Indexed by objects of class: [Date] TZ: UTC
## xts Attributes:
## List of 2
## $ src : chr "yahoo"
## $ updated: POSIXct[1:1], format: "2018-01-24 23:02:15"从雅虎金融获取美国10年债日数据:
## TNX.Open TNX.High TNX.Low TNX.Close TNX.Volume TNX.Adjusted
## 2007-01-03 4.658 4.692 4.636 4.664 0 4.664
## 2007-01-04 4.656 4.662 4.602 4.618 0 4.618
## 2007-01-05 4.587 4.700 4.583 4.646 0 4.646
## 2007-01-08 4.668 4.678 4.654 4.660 0 4.660
## 2007-01-09 4.660 4.670 4.644 4.656 0 4.656
## 2007-01-10 4.666 4.700 4.660 4.682 0 4.682## An 'xts' object on 2007-01-03/2018-01-24 containing:
## Data: num [1:2785, 1:6] 4.66 4.66 4.59 4.67 4.66 ...
## - attr(*, "dimnames")=List of 2
## ..$ : NULL
## ..$ : chr [1:6] "TNX.Open" "TNX.High" "TNX.Low" "TNX.Close" ...
## Indexed by objects of class: [Date] TZ: UTC
## xts Attributes:
## List of 2
## $ src : chr "yahoo"
## $ updated: POSIXct[1:1], format: "2018-01-25 12:37:47"从FRED下载日元对美元汇率日数据:
## DEXJPUS
## 2018-01-12 111.23
## 2018-01-15 NA
## 2018-01-16 110.74
## 2018-01-17 110.81
## 2018-01-18 110.88
## 2018-01-19 110.56从联邦经济数据库下载美国失业率月度数据:
从Oanda下载铂金数据:
可以用选项from和to指定仅下载一段时间的数据。
雅虎金融还可以下载国内股市的数据, 如下载深圳股票交易所上市的格力电器:
这个数据中2011-05-06和2011-09-16的数据缺失, 另外有些日期的交易量为0, 其股价是沿用前一天收盘价。
下载兴业银行:
下载国内股票数据要注意, 结果有些不够可靠, 比如下载上证综指(“000001.SS”)时, 2020-02-26下载数据中交易量为0, 实际为469000(单位:千手)。 下载的个股的交易量单位是一股, 指数交易量单位是千手, 报价是人民币。
另外,证券数据的日数据都是本地的日期, 中国的2号等于美国的1号, 在需要利用全球多个市场建立多变量模型时需要将日期统一到同一个时区。
tseries包的get.hist.quote()也提供了从网上数据源下载金融时间序列数据的功能。
1.8.2 quantmod包的图形功能
chartSeries()可以做K线图和曲线图等。
例:微软股票的2017-12的日数据K线图和成交量

在K线图中,
条形两端纵坐标为开盘价和收盘价,
低开高收时为阳线,
高开低收时为阴线;
用单色显示时,
阳线显示成空心条形,
阴线显示成实心条形;
用红色和绿色显示时,
国内的习惯是红色阳线,绿色阴线,
而西方的习惯是绿色阳线,红色阴线。
如果最低、最高价不等于开盘价和收盘价,
则向下画短线或者向上画短线。
这样,每个K线单元都表示了OHLC四个值。
用subset=选项指定一个序列子集。
用name=指定出现在图形左上角的数据名称标注。
用type="line"指定画曲线图,对OHLC用收盘价数据,
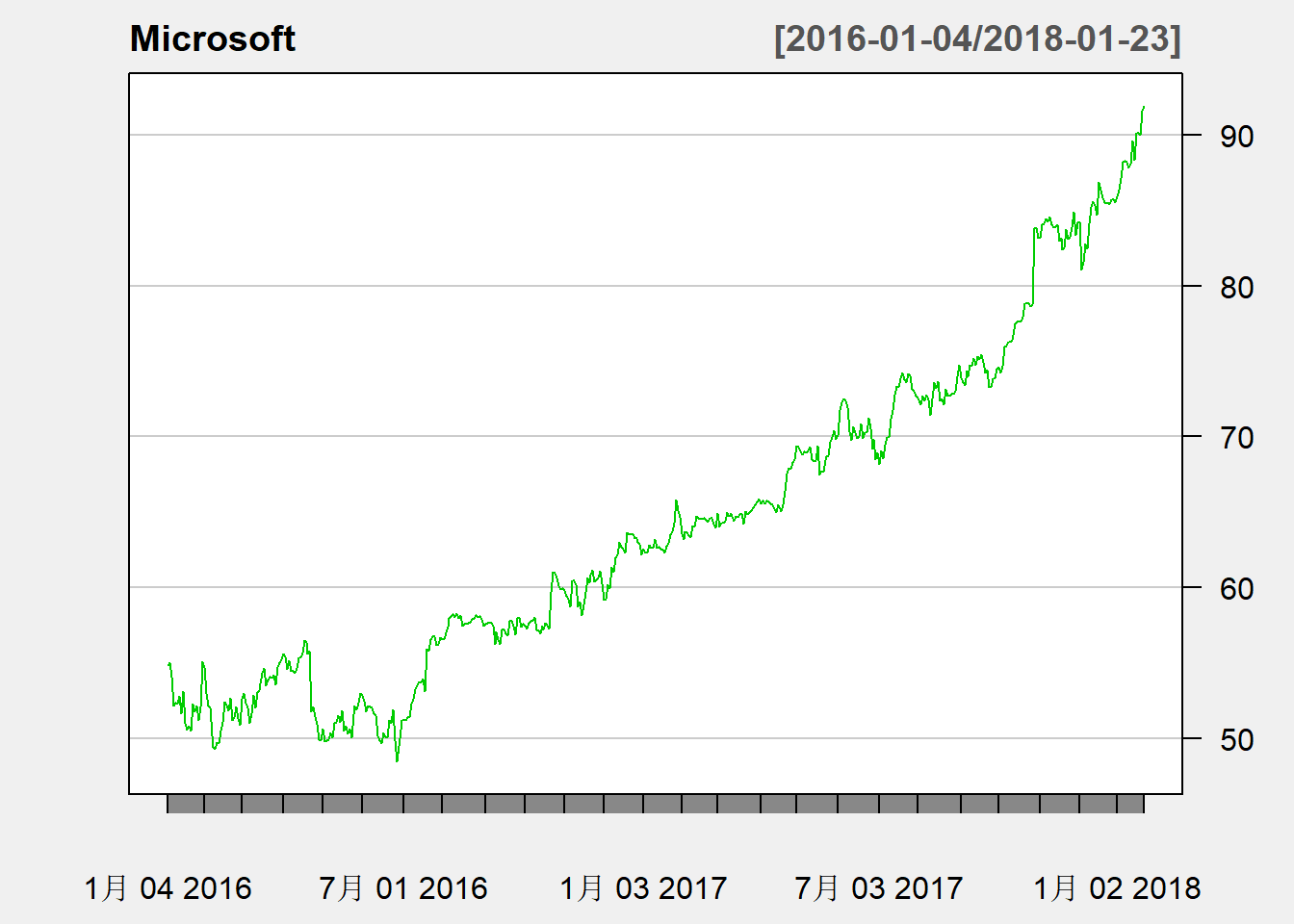
如微软股票最近三年的日数据的曲线图:

用TA=NULL选项去掉成交量图,如
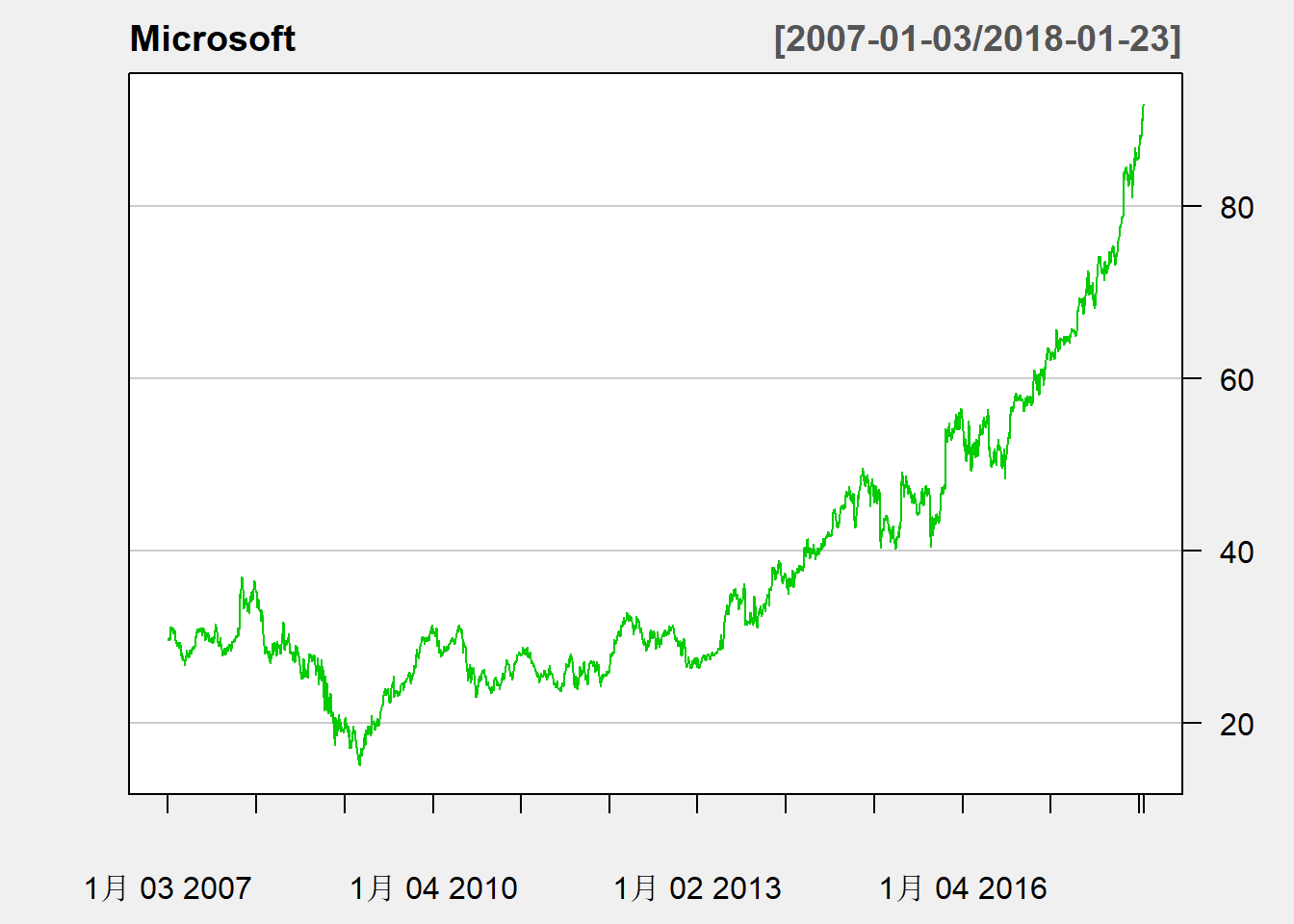
用major.ticks指定横轴的粗刻度的频率,
用minor.ticks指定细刻度的有无,
如
chartSeries(
MSFT, type="line", TA=NULL,
major.ticks="years", minor.ticks=FALSE,
theme="white", name="Microsoft"
)
用reChart()可以修改前一幅图,如
chartSeries(
MSFT, type="line", TA=NULL,
major.ticks="years", minor.ticks=FALSE,
theme="white", name="Microsoft"
)

type="bars"是另外一种K线图做法。
K线图可以用type=指定"candles", "matches", "bars"做出,
图形略有不同。
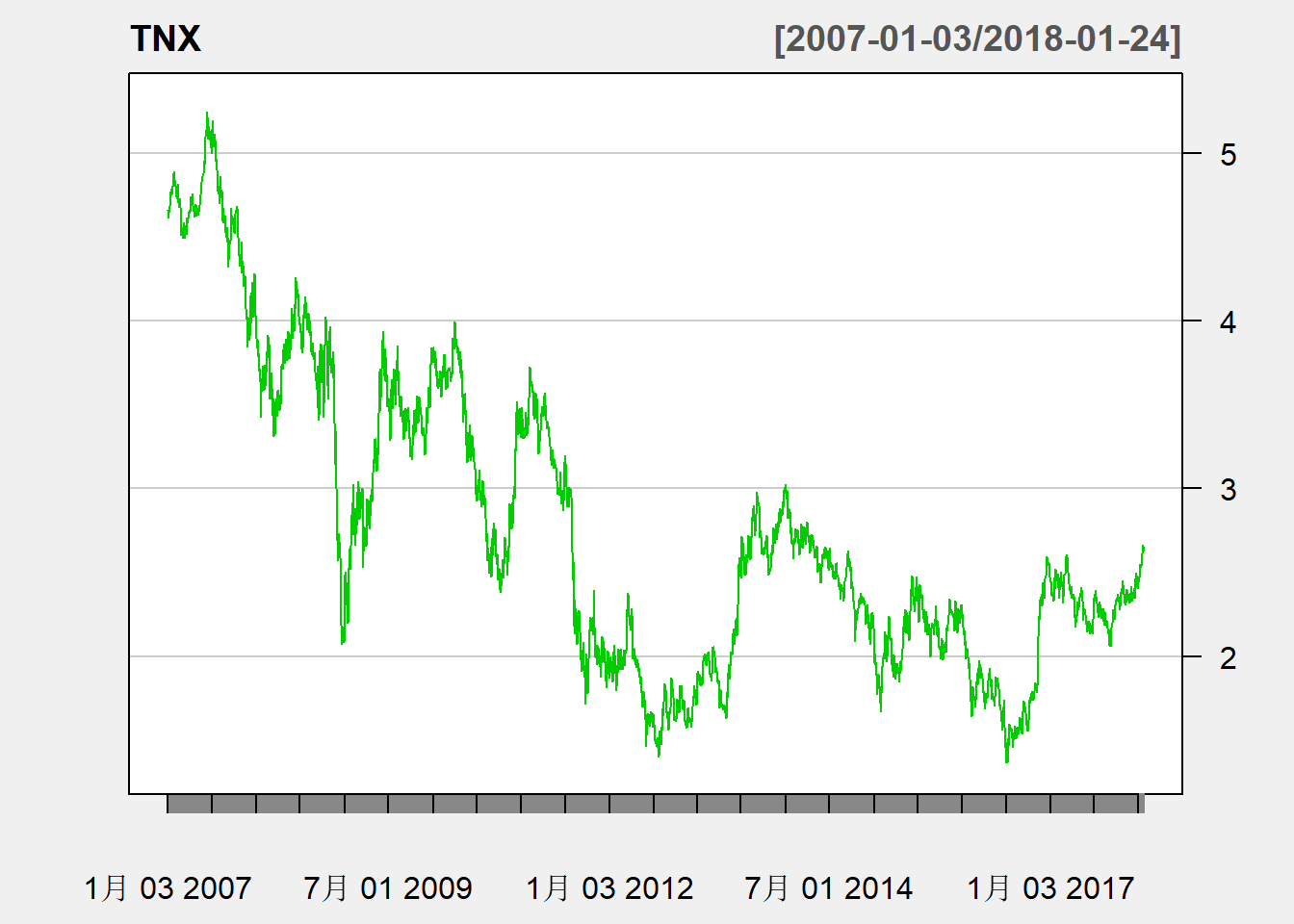
例: 美国10年国债价格日数据(CBOE Interest Rate 10 Year T No)的收盘价曲线图:
美国失业率月度数据的曲线图:

quantmod::chartSeries()可以用TA=选项字符串指定叠加许多种技术分析指标曲线,
见quantmod::addTA()的帮助。
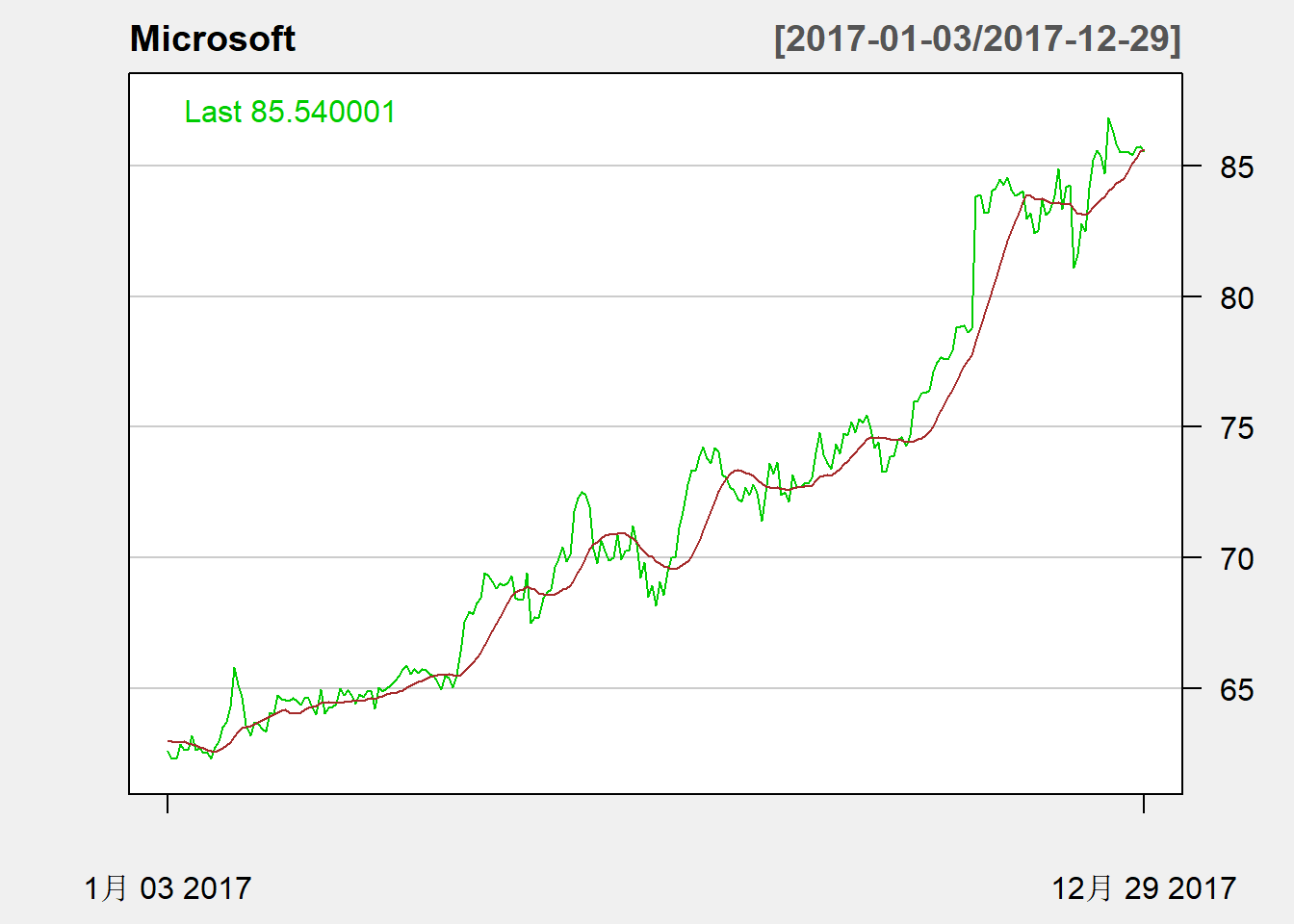
比如,TA="addSMA(14)"可以添加14日均线:
chartSeries(
MSFT, type="line", TA="addSMA(14)",
subset="2017",
major.ticks="years", minor.ticks=FALSE,
theme="white", name="Microsoft"
)
quantmod::addTA(y)可以添加任何一个xts时间序列曲线到已有的chartSeries()图形下方的并列窗格中,
用on=1选项叠加到原图中。
1.8.3 quantmod包的计算功能
最常见的金融数据都是有时间、开盘价、最高、最低、收盘价、成交量等, 这样的数据称为OHLC数据。 有的没有成交量, 有的仅有时间和价格。 有的数据中包含Adjusted或者Adjusted Closing Price, 这是调整的收盘价, 是针对拆分股、分红等对收盘价进行相应的调整。
quantmod中提供了多个管理OHLC数据的方便函数。
设x是一个OHLC数据:
Op(x),Hi(x),Lo(x),Cl(x),Vo(x),Ad(x)分别提取出开盘价、最高、最低、收盘、成交量、调整收盘价。is.OHLC(x)判断是否OHLC数据,has.OHLC(x)判断是否包含OHLC数据,has.xxx(x)判断是否有各个成分 (xxx分别取Op,Hi,Lo,Cl,Vo,Ad)。seriesHi(x)求每个分量的最大值,seriesLo(x)求每个分量的最小值。对每个时间点:
OpCl(x)计算开盘价到收盘价的变化率;HiCl(x)计算最高价到收盘价的变化率;LoCl(x)计算最低价到收盘价的变化率;LoHi(x)计算最低价到最高价的变化率;OpHi(x)计算开盘价到最高价的变化率;OpLo(x)计算开盘价到最低价的变化率。
OpOp(x)计算前后两个时间点的开盘价的变化率,ClCl(x)计算前后两个时间点的收盘价的变化率。 也是简单收益率。
例:
## MSFT.Open MSFT.High MSFT.Low MSFT.Close MSFT.Volume MSFT.Adjusted
## 2018-01-17 89.08 90.28 88.75 90.14 25621200 90.14
## 2018-01-18 89.80 90.67 89.66 90.10 24159700 90.10
## 2018-01-19 90.14 90.61 89.66 90.00 36875000 90.00
## 2018-01-22 90.00 91.62 89.74 91.61 23601600 91.61
## 2018-01-23 91.90 92.30 91.54 91.90 22459400 91.90## OpCl.last(MSFT, "5 days")
## 2018-01-17 0.011899382
## 2018-01-18 0.003340701
## 2018-01-19 -0.001553128
## 2018-01-22 0.017888900
## 2018-01-23 0.000000000## ClCl.last(MSFT, "5 days")
## 2018-01-17 NA
## 2018-01-18 -0.0004437653
## 2018-01-19 -0.0011098557
## 2018-01-22 0.0178889000
## 2018-01-23 0.0031656042Lag(x)求序列滞后一期的结果,如
## Lag.1
## 2018-01-17 NA
## 2018-01-18 90.14
## 2018-01-19 90.10
## 2018-01-22 90.00
## 2018-01-23 91.61Next(x)求序列超前一期的结果,如
## Next
## 2018-01-17 90.10
## 2018-01-18 90.00
## 2018-01-19 91.61
## 2018-01-22 91.90
## 2018-01-23 NADelt(x)计算某个序列的简单收益率,如
## Delt.1.arithmetic
## 2018-01-17 NA
## 2018-01-18 -0.0004437653
## 2018-01-19 -0.0011098557
## 2018-01-22 0.0178889000
## 2018-01-23 0.0031656042Delta(x, k)可以指定不同的时期k计算多期简单收益率。
periodReturn(x, period)可以降频计算给定周期的收益率。
默认计算简单收益率,
用type="log"选项要求计算对数收益率。
特别地,
dailyReturn(x),
weeklyReturn(x),
monthlyReturn(x),
quartlyReturn(x),
annualReturn(x)或者yearlyReturn(x)计算某个周期的收益率。
allReturns(x)计算日、周、月、季、年收益率。
1.9 用BatchGetSymbols包下载金融数据
quantmod的getSymbols函数每次下载一个资产的价格序列,
但是数据集中的变量名都带有资产名字,
而且有时会有缺失值或交易量为0的日期。
BatchGetSymbols函数可以指定若干个资产的一个时间段同时从雅虎财经下载,
并保存为数据框形式,
不同资产的价格数据存放在相同的列中,
用一个ticker变量区分资产,
可以将交易量为零的价格设为缺失值或前一时期的值。
可以缓存已经下载过的值,
仅下载没有本地副本的值。
例如,下载最近60天:
library(BatchGetSymbols)
first.date <- Sys.Date() - 60
last.date <- Sys.Date()
freq.data <- "daily"
# set tickers
tickers <- c(
"S&P500" = c,
"Facebook" = "FB",
"上证综指" = "000001.SS",
"兴业银行" = "601166.SS",
"中兴通讯" = "000063.SZ"
)
l.out <- BatchGetSymbols(
tickers = tickers,
first.date = first.date,
last.date = last.date,
freq.data = freq.data,
cache.folder = file.path(
tempdir(), 'BGS_Cache') ) # cache in tempdir()
## Running BatchGetSymbols for:
## tickers =.Primitive("c"), FB, 000001.SS, 601166.SS, 000063.SZ
## Downloading data for benchmark ticker
## ^GSPC | yahoo (1|1) | Found cache file
## .Primitive("c") | yahoo (1|5) | Not Cached - Error in download..
## FB | yahoo (2|5) | Found cache file - Got 100% of valid prices | OK!
## 000001.SS | yahoo (3|5) | Found cache file - Got 86% of valid prices | Good stuff!
## 601166.SS | yahoo (4|5) | Found cache file - Got 86% of valid prices | Got it!
## 000063.SZ | yahoo (5|5) | Not Cached | Saving cache - Got 86% of valid prices | You got it!结果是包含df.control和df.tickers的列表,
df.control是下载基本信息:
## # A tibble: 4 × 6
## ticker src download.status total.obs perc.benchmark.dates threshold.decision
## <chr> <chr> <chr> <int> <dbl> <chr>
## 1 FB yahoo OK 42 1 KEEP
## 2 00000… yahoo OK 38 0.857 KEEP
## 3 60116… yahoo OK 38 0.857 KEEP
## 4 00006… yahoo OK 38 0.857 KEEP数据内容的变量:
## [1] "price.open" "price.high" "price.low"
## [4] "price.close" "volume" "price.adjusted"
## [7] "ref.date" "ticker" "ret.adjusted.prices"
## [10] "ret.closing.prices"为了将代码转换成名称, 写一个将元素值与元素名调换的函数:
绘图:
library(ggplot2, quietly = TRUE)
mapn <- nameMapInv(tickers)
ggplot(data=l.out$df.tickers, mapping=aes(
x = ref.date, y = price.close)) +
geom_line() +
facet_wrap(~ mapn[ticker], scales = 'free_y') 
1.11 附录:R软件的其它时间序列类型和功能
tseries包中的get.hist.quote()函数可以从网上获取各主要股票的日交易数据。
fracdiff库的fracdiff可以拟合分数ARIMA模型。
tseries包中的garch可以拟合GARCH和ARCH模型。
经常用GARCH(1,1)拟合收益数据。
rugarch包有更强大的GARCH功能,比如使用t分布残差。
fSeries包中的garchFit可以拟合较复杂的包含GARCH的模型。
car包中的durbin.watson函数可以对lm对象进行Durbin-Watson自相关检验。
ts包中的Box.test可以进行Box-Pierce或Ljung-Box白噪声检验。
tseries包中的adf.test可以进行Dickey-Fuller单位根检验。