19 MCMC
19.1 马氏链和MCMC介绍
实际工作中经常遇到分布复杂的高维随机向量抽样问题。 12的重要抽样法可以应付维数不太高的情况, 但是对于维数很高而且分布很复杂(比如,分布密度多峰而且位置不易确定的情况)则难以处理。 另外,随机向量\(\boldsymbol X\)的概率质量函数或者密度函数\(f(\boldsymbol x)\)常常只能确定到 \[ f(x) = C \tilde f(x), \] 但其中的常数\(C\)未知且计算难度很大。 需要在这样的情况下生成\(\boldsymbol X\)的随机样本。
MCMC(马氏链蒙特卡洛)是一种对高维随机向量抽样的方法, 此方法模拟一个马氏链, 使马氏链的平稳分布为目标分布, 由此产生大量的近似服从目标分布的样本, 但样本不是相互独立的。 MCMC的目标分布密度函数或概率函数可以只计算到差一个常数倍的值。 MCMC方法适用范围广, 近年来获得了广泛的应用。
先介绍马氏链的概念(参考 钱敏平 et al. (2011) )。
设\(\{X_t, t=0, 1, \dots \}\)为随机变量序列, 称为一个随机过程。 称\(X_t\)为“系统在时刻\(t\)的状态”。 为讨论简单起见, 设所有\(X_t\)均取值于有限集合\(S = \{ 1,2,\dots, m\}\), 称\(S\)为状态空间。 如果\(\{ X_t \}\)满足 \[\begin{align} & P(X_{t+1} = j | X_0=k_0, \dots X_{t-1}=k_{t-1}, X_t=i) \nonumber\\ =& P(X_{t+1} = j | X_t=i) = p_{ij}, \ t=0,1,\dots, \ k_0, \dots, k_{t-1}, i, j \in S, \tag{19.1} \end{align}\] 则称\(\{ X_t \}\)为马氏链, \(p_{ij}\)为转移概率, 矩阵\(P = (p_{ij})_{m\times m}\)为转移概率矩阵。 显然\(\sum_{j=1}^m p_{ij}=1, \ i=1,2,\dots,m\)。 对马氏链, \(P(X_{t+k}=j | X_t = i) = p_{ij}^{(k)}\)也不依赖于\(t\), 称为\(k\)步转移概率。 如果对任意\(i, j \in S\), \(i\neq j\)都存在\(k \geq 1\)使得 \(p_{ij}^{(k)} > 0\)则称\(\{X_t \}\)为不可约马氏链。 不可约马氏链的所有状态是互相连通的, 即总能经过若干步后互相转移。 对马氏链\(\{ X_t \}\)的某个状态\(i\), 如果存在\(k \geq 0\)使得 \(p_{ii}^{(k)} > 0\)并且\(p_{ii}^{(k+1)}>0\), 则称\(i\)是非周期的。 如果一个马氏链所有状态都是非周期的,则该马氏链称为非周期的。 不可约马氏链只要有一个状态是非周期的则所有状态是非周期的。 对只有有限个状态的非周期不可约马氏链有 \[ \begin{aligned} \lim_{n\to\infty} P(X_n = j | X_0=i) = \pi_j, \ i, j=1,2,\dots, m, \end{aligned} \] 其中\(\{\pi_j, j=1,2,\dots,m \}\)为正常数, 满足\(\sum_{j=1}^m \pi_j=1\), 称为\(\{ X_t \}\)的极限分布。 \(\{ \pi_j \}\)满足方程组 \[\begin{align} \begin{cases} \sum_{i=1}^m \pi_i p_{ij} = \pi_j, \ j=1,2,\dots,m \\ \sum_{j=1}^m \pi_j = 1, \end{cases} \tag{19.2} \end{align}\] 称满足(19.2)的分布\(\{ \pi_j \}\)为平稳分布或不变分布。 对只有有限个状态的非周期不可约马氏链, 极限分布和平稳分布存在且为同一分布。
如果允许状态空间\(S\)为可列个元素, 比如\(S = \{ 0, 1, 2, \ldots \}\), 极限分布的条件需要更多的讨论。 对状态\(i\), 如从状态\(i\)出发总能再返回状态\(i\), 则称状态\(i\)是常返的(recurrent)。 状态\(i\)常返可等价地定义为\(P(X_n=i, \text{i.o.} | X_0=i)=1\), 其中i.o.表示事件发生无穷多次,\(A_n \text{ i.o.}\)即 \(\cap_{k=1}^\infty \cup_{n=k}^\infty A_n\)。
对常返状态\(i\), 如果从\(i\)出发首次返回\(i\)的时间的期望有限, 称\(i\)是正常返的。 对于不可约马氏链,只要存在正常返状态则所有状态都是正常返, 这时存在唯一的平稳分布\(\pi\)。 非周期、正常返的不可约马氏链存在极限分布, 极限分布就是平稳分布: \[ \lim_{n\to\infty} p_{ij}^{(n)} = \pi_j, \ \forall i, j \in S . \]
设正常返的不可约马氏链的平稳分布为\(\pi\), 设\(h(\cdot)\)是状态空间\(S\)上的有界函数, 则 \[\begin{align} P\left( \lim_{n\to\infty} \frac{1}{n} \sum_{k=0}^n h(X_k) = \sum_{x \in S} \pi_x h(x) \right) = 1 . \tag{19.3} \end{align}\] 这类似于独立同分布随机变量平均值的强大数律。 当\(Y\)服从平稳分布\(\pi\)时,上式中的极限就等于\(E [h(Y)]\)。 如果能设计转移概率矩阵满足不可约、非周期、正常返性质的马氏链且其平稳分布为\(\pi(\cdot)\), 则从某个初始分布出发按照转移概率模拟一列马氏链, 由(19.3)可以估计关于\(Y \sim \pi(\cdot)\)的随机变量的函数的期望\(E[h(Y)]\)。
如何得到有平稳分布的转移概率矩阵? 一个充分条件是转移概率满足细致平衡条件。 如果存在\(\{ \pi_j, j \in S \}\), \(\pi_j \geq 0\), \(\sum_{j \in S} \pi_j = 1\), 使得 \[\begin{aligned} \pi_i p_{ij} = \pi_j p_{ji}, \ \forall i \neq j, \end{aligned} \] 称这样的马氏链为细致平衡的(detailed balanced), 这时\(\{ \pi_j \}\)是\(\{ X_t \}\)的平稳分布。 事实上,若\(P(X_t = i) = \pi_i, i \in S\), 则 \[\begin{aligned} P(X_{t+1} = j) = \sum_i \pi_i p_{ij} = \sum_i \pi_j p_{ji} = \pi_j \sum_i p_{ji} = \pi_j, \ \forall j \in S. \end{aligned} \] 只要再验证转移概率矩阵\((p_{ij})\)满足不可约性和正常返性就可以利用(19.3)估计服从平稳分布的随机变量\(Y\)的函数的期望\(E[h(Y)]\)了。
马氏链的概念可以推广到\(X_t\)的取值集合\(\mathcal{X}\)为\(\mathbb R^d\)的区域的情形。 如果各\(\{ X_t \}\)的有限维分布是连续型的, 则(19.1)可以改用条件密度表示, 这时的\(\{ X_t \}\)按照随机过程论中的习惯应该称作马氏过程, 但这里还是叫做马氏链。
如果非周期、正常返的不可约马氏链\(\{ X_t \}\)的平稳分布为\(\pi(x), x \in \mathcal{X}\), 则从任意初值出发模拟产生序列\(\{ X_t \}\), 当\(t\)很大时,\(X_t\)的分布就近似服从\(\pi\), 抛弃开始的一段后的\(X_t\)序列可以作为分布\(\pi\)的相关的样本, 抛弃的一段序列叫做老化期。 如果只是为了估计\(Y \sim \pi(\cdot)\)的函数的期望, 可以仅要求马氏链为正常返不可约马氏链。 设\(Y \sim \pi(\cdot)\), \(h(y), y \in \mathcal{X}\)是有界函数, 为估计\(\theta = E [h(Y)]\), 用\(X_t, t=k+1, \dots, n\)作为\(\pi\)的样本, 用估计量\(\hat\theta = \frac{1}{n-k} \sum_{t=k+1}^n h(X_t)\)来估计\(\theta\), 则\(\hat\theta\)是\(\theta\)的强相合估计。 老化期长度\(k\)可以从\(\hat\theta\)的变化图形经验地选取。
这样的估计量\(\hat\theta\)是相关样本的平均值, 无法用原来独立样本的公式估计\(\text{Var}(\hat\theta)\)从而得到\(\hat\theta\)的标准误差。 为了估计\(\text{Var}(\hat\theta)\), 可以采用如下的分段平均法。 把样本\(X_{k+1}, \dots, X_n\)分为\(s\)段, 每段\(r\)个(设\(n-k = sr\))。 设第\(j\)段的\(r\)个\(h(X_t)\)的平均值为\(Z_j, j=1,2,\dots,s\), 设\(\{ Z_j, j=1,2,\dots,s \}\)的样本方差为 \(\hat\sigma^2=\frac{1}{s-1} \sum_{j=1}^s (Z_j - \bar Z)^2\), 因为\(\hat\theta\)等于\(\{Z_j, j=1,2,\dots,s \}\)的样本均值\(\bar Z\), 当\(r\)足够大时, 可以认为各\(Z_j\)相关性已经很弱, 这时\(\hat\theta\)的方差可以用\(\hat\sigma^2 / s\)估计。 \(r\)的大小依赖于不同时刻的\(X_t\)的相关性强弱, 相关性越强,需要的\(r\)越大。
以上的方法就是MCMC方法(马氏链蒙特卡洛)。 一般地, 对高维或取值空间\(\mathcal{X}\)结构复杂的随机向量\(X\), MCMC方法构造取值于\(\mathcal{X}\)的马氏链, 使其平稳分布为\(X\)的目标分布。 模拟此马氏链, 抛弃开始的部分抽样值, 把剩余部分作为\(X\)的非独立抽样。 非独立抽样的估计效率比独立抽样低。
MCMC方法的关键在于如何从第\(t\)时刻转移到第\(t+1\)时刻。 好的转移算法应该使得马氏链比较快地收敛到平稳分布, 并且不会长时间地停留在取值空间\(\mathcal{X}\)的局部区域内 (在目标分布是多峰分布且峰高度差异较大时容易出现这种问题)。
Metropolis-Hasting方法(MH方法)是一个基本的MCMC算法, 此算法在每一步试探地进行转移(如随机游动), 如果转移后能提高状态\(x_t\)在目标分布\(\pi\)中的密度值则接受转移结果, 否则以一定的概率决定是转移还是停留不动。
Gibbs抽样是另外一种常用的MCMC方法,此方法轮流沿各个坐标轴方向转移, 且转移概率由当前状态下用其它坐标预测转移方向坐标的条件分布给出。 因为利用了目标分布的条件分布, 所以Gibbs抽样方法的效率比MH方法效率更高。
19.2 Metropolis-Hasting抽样
设随机变量\(X\)分布为\(\pi(x), x \in \mathcal{X}\)。 为论述简单起见仍假设\(\mathcal{X}\)是离散集合。 算法需要一个试转移概率函数\(T(y|x), x, y \in \mathcal{X}\),满足 \(0 \leq T(y|x) \leq 1\), \(\sum_y T(y|x) = 1\), 并且 \[\begin{aligned} T(y|x)>0 \Leftrightarrow T(x|y)>0 . \end{aligned}\]
算法首先从\(\mathcal{X}\)中任意取初值\(X^{(0)}\)。 设经过\(t\)步后算法的当前状态为\(X^{(t)}\), 则下一步由试转移分布\(T(y|X^{(t)})\)抽取\(Y\), 并生成\(U \sim\)U(0,1), 然后按如下规则转移: \[\begin{aligned} X^{(t+1)} = \begin{cases} Y & \text{如果 } U \leq r(X^{(t)}, Y) \\ X^{(t)} & \text{其它.} \end{cases} \end{aligned}\] 其中 \[\begin{align} r(x, y) = \min \left\{ 1, \frac{\pi(y)T(x|y)}{\pi(x)T(y|x)} \right\}. \tag{19.4} \end{align}\]
在MH算法中如果取\(T(y|x) = T(x|y)\), 则\(r(x,y) = \min\left(1, \frac{\pi(y)}{\pi(x) } \right)\), 相应的算法称为Metropolis抽样法。
如果取\(T(y|x) = g(y)\)(不依赖于\(x\)), 则\(r(x,y) = \min\left(1, \frac{\pi(y)/g(y)}{\pi(x)/ g(x)} \right)\), 相应的算法称为Metropolis独立抽样法, 和重要抽样有相似之处, 试抽样分布\(g(\cdot)\)经常取为相对重尾的分布。
在MH算法中, 目标分布\(\pi(x)\)可以用差一个常数倍的\(\tilde \pi(x) = C \pi(x)\)代替, 这样关于目标分布仅知道差一个常数倍的\(\tilde \pi(x)\)的情形, 也可以使用此算法。
下面说明MH抽样方法的合理性。
我们来验证MH抽样的转移概率\(A(x,y) = P(X^{(t+1)} = y | X^{(t)} = x)\)满足细致平衡条件。
易见
\[\begin{aligned}
A(x, y) = \begin{cases}
T(y | x) r(x,y), & y \neq x, \\
T(x | x) + \sum_{z \neq x} T(z | x) [1 - r(x,z)], & y = x,
\end{cases}
\end{aligned}\]
于是当\(x \neq y\)时
\[\begin{aligned}
\pi(x) A(x,y)
=& \pi(x) T(y | x)
\min \left\{ 1, \frac{\pi(y)T(x | y)}{\pi(x)T(y | x)} \right\}
= \min \left\{ \pi(x)T(y | x), \pi(y)T(x | y) \right\} ,
\end{aligned}\]
等式右侧关于\(x, y\)是对称的,
所以等式左侧把\(x, y\)交换后仍相等。
所以,MH构造的马氏链以\(\{ \pi(x) \}\)为平稳分布。
多数情况下MH构造的马氏链也以\(\{ \pi(x) \}\)为极限分布。
(19.4)中的\(r(x,y)\)还可以推广为如下的形式 \[\begin{aligned} \tilde r(x, y) = \frac{\alpha(x, y)}{\pi(x) T(y | x)}, \end{aligned}\] 其中\(\alpha(x,y)\)是任意的满足\(\alpha(x,y)=\alpha(y,x)\) 且使得\(\tilde r(x,y) \leq 1\)的函数。 易见这样的\(\tilde r(x,y)\)仍使得生成的马氏链满足细致平衡条件。
例19.1 \(X\)的取值集合\(\mathcal{X}\)可能是很大的,以至于无法穷举, 目标分布\(\pi(x)\)可能是只能确定到差一个常数倍。
例如,设 \[\begin{aligned} \mathcal{X} =& \{\boldsymbol x = (x_1, x_2, \dots, x_n) \,:\, \\ & \; (x_1, x_2, \dots, x_n) \text{是} (1,2,\dots,n) \text{的排列,使得}\sum_{j=1}^n j x_j > a \}, \end{aligned}\] 其中\(a\)是一个给定的常数。 用\(|\mathcal{X}|\)表示\(\mathcal{X}\)的元素个数, 当\(n\)较大时\(\mathcal{X}\)是\((1,2,\dots,n)\)的所有\(n!\)个排列的一个子集, \(|\mathcal{X}|\)很大, 很难穷举\(\mathcal{X}\)的元素, 从而\(|\mathcal{X}|\)未知。
设\(X\)服从\(\mathcal{X}\)上的均匀分布, 即\(\pi(\boldsymbol x) = C, \ x \in \mathcal{X}\), \(C = 1/|\mathcal{X}|\)但\(C\)未知。 要用MH方法产生\(X\)的抽样序列。
试抽样\(T(\boldsymbol y | \boldsymbol x)\)如果允许转移到所有的\(\boldsymbol y\)是很难执行的, 因为\(\boldsymbol y\)的个数太多了。 我们定义一个\(\boldsymbol x\)的近邻的概念, 仅考虑转移到\(\boldsymbol x\)的近邻。 一种定义是, 如果把\(\boldsymbol x\)的\(n\)个元素中的某两个交换位置后可以得到\(\boldsymbol y \in \mathcal{X}\), 则\(\boldsymbol y\)称为\(\boldsymbol x\)的一个近邻, 记\(N(\boldsymbol x)\)为\(\boldsymbol x\)的所有近邻的集合, 记\(| N(\boldsymbol x) |\)为\(\boldsymbol x\)的近邻的个数。 当\(n\)很大时,求\(N(\boldsymbol x)\)也需要从\(C_n^2=\frac12 n(n-1)\)个可能的元素中用穷举法选择。 取试转移概率函数为 \[\begin{aligned} T(\boldsymbol y | \boldsymbol x) = \frac{1}{|N(\boldsymbol x)|}, \ \boldsymbol x, \boldsymbol y \in \mathcal{X}, \end{aligned}\] 即从\(\boldsymbol x\)出发,等可能地试转移到\(\boldsymbol x\)的任何一个近邻上。
因为目标分布\(\pi(\boldsymbol x)\)是常数, 所以这时 \[\begin{aligned} r(\boldsymbol x, \boldsymbol y) = \min\left(1, \frac{|N(\boldsymbol x)|}{|N(\boldsymbol y)|} \right), \end{aligned}\] 即从\(\boldsymbol x\)试转移到\(\boldsymbol y\)后, 如果\(\boldsymbol y\)的近邻数不超过\(\boldsymbol x\)的近邻数则确定转移到\(\boldsymbol y\), 否则,仅按概率\(|N(\boldsymbol x)| / |N(\boldsymbol y)|\)转移到\(\boldsymbol y\)。 这就构成了对\(X\)抽样的MH算法。
Julia实现:
# x: 初始排列
# nout: 需要输出的抽样次数
# n: 排列的元素个数
# bound: 即$\sum_j j x_j \geq a$的界限$a$。
using LinearAlgebra, Random
function demo_permsub(x, nout::Int=100, n::Int=10, bound::Int=100)
DEBUG = false
sum1 = dot(1:n, x) # 要判断的条件的当前值
## 计算合法近邻数的函数
## 注意:内嵌函数内的局部变量与其所在函数的同名变量是同一变量
function nneighb(x)
nn = 1
sum0 = dot(1:n, x)
for i=1:(n-1)
for j=(i+1):n
sum0b = sum0 - i*x[i] - j*x[j] + i*x[j] + j*x[i]
if sum0b >= bound
nn += 1
end
end
end
nn
end
## 输出为nout行n列矩阵
resmat = zeros(Int, nout, n)
nsucc = 0 # 已经成功找到的元素个数
nfail = 0 # 上一次成功后的累计失败次数
ntry = 0 # 总试投次数
nn1 = nneighb(x) # 当前合法近邻数
while nsucc < nout
ntry += 1
DEBUG && println("ntry: ", ntry)
nfail += 1
if nfail > 1000
println("尝试失败超过1000次: nsucc=", nsucc, " ntry=", ntry)
println(x)
break
end
# 进行一次尝试,随机选取两个元素下标,交换对应元素的位置
# 看是否合法元素。注意,原本算法应该在合法近邻中抽取,这样是等价的
I1::Int = ceil(rng()*n) # 第一个随机下标
I2::Int = ceil(rng()*(n-1))
if I2 >= I1
I2 += 1 # I2是第二个随机下标
end
DEBUG && println("尝试交换:", I1, " ", I2, " ", x[I1], " ", x[I2])
# 按照新的位置,计算目标的新值,比较是否超过界限
sum2 = sum1 - I1*x[I1] - I2*x[I2] + I1*x[I2] + I2*x[I1]
DEBUG && println("sum1: ", sum1, " sum2: ", sum2)
if sum2 >= bound # 交换得到新的合法元素,看是否要转移
# 先跳过去,如果不满足概率要求再跳回来
tmp1 = x[I1]; x[I1] = x[I2]; x[I2] = tmp1
tran = false
nn2 = nneighb(x)
if nn2 <= nn1
tran = true
DEBUG && println("nn1: ", nn1, " nn2: ", nn2)
else
R = rng()
DEBUG && println("nn1: ", nn1, " nn2: ", nn2, " U(0,1): ", R)
if R < nn1 / nn2
tran = true
end
end
if tran
nsucc += 1
nfail = 0
resmat[nsucc, :] = x
nn1 = nn2
sum1 = sum2
else
tmp1 = x[I1]; x[I1] = x[I2]; x[I2] = tmp1
nfail += 1
end
else
nfail += 1
end
end
resmat
end测试运行:
10×5 Array{Int64,2}:
1 2 3 5 4
1 2 3 4 5
1 2 5 4 3
2 1 5 4 3
2 1 5 3 4
1 2 5 3 4
1 2 4 3 5
1 2 4 5 3
1 2 5 4 3
1 2 3 4 520×10 Array{Int64,2}:
1 2 3 4 5 9 7 8 6 10
1 2 3 4 5 10 7 8 6 9
1 2 3 4 5 10 7 9 6 8
1 2 3 4 5 10 7 6 9 8
1 2 3 4 5 9 7 6 10 8
1 2 3 4 5 10 7 6 9 8
1 2 3 4 5 7 10 6 9 8
1 2 3 4 5 10 7 6 9 8
1 2 3 4 6 10 7 5 9 8
1 2 3 4 6 7 10 5 9 8
1 2 3 6 4 7 10 5 9 8
1 2 3 6 4 7 10 5 8 9
1 2 3 6 4 5 10 7 8 9
1 2 3 5 4 6 10 7 8 9
1 2 5 3 4 6 10 7 8 9
1 2 6 3 4 5 10 7 8 9
1 2 6 3 4 5 10 8 7 9
1 2 3 6 4 5 10 8 7 9
1 2 3 6 4 5 10 8 9 7
1 2 3 6 4 5 10 8 7 9有了抽样后可以考察\(\mathcal X\)上的均匀分布的一些问题。 例如, 求\(X_n\)的概率分布和期望值。 取\(n=100\), \(a=330000\),用模拟方法求解。 在模拟量过大时, 存储所有的结果会超出可用内存, 这时一般分批模拟, 下一批从上一批最后的状态开始模拟。 因为模拟是从一个规则状态开始的, 丢弃初始的1万次抽样, 使用随后的100万次抽样的结果。
rng = rand # 使用Julia官方的均匀随机数发生器
Random.seed!(101)
n = 100
a = 330000
batch = 100 # 每批次抽取100个样本
nb = 10100 # 总共101万个抽样
nb0 = 100 # 丢弃的初始模拟样本1万个
tab = zeros(n) # 用来记录每个数值在$X_n$出现的次数
resm = zeros(Int, batch, n) # 一个批次的存储,在各批次之间复用
x = collect(1:n)
for ib = 1:nb
println("Batch NO. ", ib)
resm[:,:] = demo_permsub(x, batch, n, a)
x[:] = resm[batch, :]
if ib > nb0 # 跳过nb0批次
for j=1:batch
tab[resm[j,n]] += 1
end
end
end估计\(X_n\)的概率分布为:
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
0.0, 0.0, 0.0, 0.0, 0.0, 1.5e-5, 0.0, 5.4e-5, 1.4e-5, 0.0,
0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 8.0e-6, 0.0,
9.2e-5, 0.0, 6.0e-6, 0.000156, 0.000253, 0.000149, 0.000307, 0.000687, 0.000853, 0.000813,
0.000644, 0.00121, 0.001393, 0.001503, 0.002198, 0.001811, 0.002581, 0.002672, 0.003203, 0.004005,
0.004883, 0.006127, 0.006593, 0.008228, 0.010117, 0.010797, 0.010435, 0.015785, 0.014116, 0.017574,
0.017558, 0.021747, 0.024416, 0.026553, 0.026831, 0.028487, 0.035404, 0.032202, 0.037334, 0.039685,
0.041615, 0.042638, 0.044291, 0.051675, 0.057559, 0.059117, 0.066057, 0.06187, 0.076104, 0.079575]\(EX_n\)的估计:
※※※※※
19.2.1 连续型分布的MH抽样法
对于连续型的目标分布, 设\(\pi(x)\)为目标分布的密度, 这时\(T(y|x)\)改为给定\(x\)条件下的试抽样密度, \(r(x,y)\)定义不变,算法和离散型目标分布的情形相同。
例19.2 考虑一个贝叶斯推断问题。 在金融投资中,投资者经常把若干种证券组合在一起来减少风险。 假设有5支股票的\(n=250\)个交易日的收益率记录, 每个交易日都找出这5支股票收益率最高的一个, 设\(X_i\)表示第\(i\)支股票在\(n\)个交易日中收益率为最高的次数(\(i=1,2,\dots,5\))。 设\((X_1, \dots, X_5)\)服从多项分布, 相应的概率假设为 \[\begin{aligned} \boldsymbol p = \left( \frac13, \frac{1-\beta}{3}, \frac{1 - 2\beta}{3}, \frac{2\beta}{3}, \frac{\beta}{3} \right), \end{aligned}\] 其中\(\beta \in (0,0.5)\)为未知参数。 假设\(\beta\)有先验分布\(p_0(\beta) \sim \text{U}(0,0.5)\)。 设\((x_1, \dots, x_5)\)为\((X_1, \dots, X_5)\)的观测值, 则\(\beta\)的后验分布为 \[\begin{aligned} & f(\beta | x_1, \dots, x_5) \propto p(x_1, \dots, x_5 | \beta) p_0(\beta) \\ =& \binom{n}{x_1,\dots,x_5} \left( \frac13 \right)^{x_1} \left( \frac{1-\beta}{3} \right)^{x_2} \left( \frac{1-2\beta}{3} \right)^{x_3} \left( \frac{2\beta}{3} \right)^{x_4} \left( \frac{\beta}{3} \right)^{x_5} \frac{1}{0.5} I_{(0,0.5)}(\beta) \\ \propto& (1-\beta)^{x_2} (1 - 2\beta)^{x_3} \beta^{x_4+x_5} I_{(0,0.5)}(\beta) = \tilde\pi(\beta). \end{aligned}\]
为了求\(\beta\)后验均值,需要产生服从\(f(\beta | x_1, \dots, x_5)\)的抽样。 从\(\beta\)的后验分布很难直接抽样, 采用Metropolis抽样法。
设当前\(\beta\)的状态为\(\beta^{(t)}\), 取试抽样分布\(T(y | \beta^{(t)})\)为U(0,0.5), 则\(T(y|x)=T(x|y)\), \[\begin{aligned} r(\beta^{(t)}, y) = \min\left(1, \frac{\tilde\pi(y)}{\tilde\pi(\beta^{(t)})} \right) = \min\left(1, \left(\frac{1-y}{1-\beta^{(t)}} \right)^{x_2} \left(\frac{1 - 2y}{1 - 2\beta^{(t)}} \right)^{x_3} \left(\frac{y}{\beta^{(t)}} \right)^{x_4 + x_5} \right), \end{aligned}\] 从U(0, 0.5)试抽取\(y\),以概率\(r(\beta^{(t)}, y)\)接受\(\beta^{(t+1)} = y\)即可。
※※※※※
19.2.2 随机游动MH算法
MH抽样中试转移概率函数\(T(y | x)\)较难找到, 容易想到的是从\(x^{(t)}\)作随机游动的试转移方法, 叫做随机游动Metropolis抽样。
设\(X\)的目标分布\(\pi(\boldsymbol x)\)取值于欧式空间\(\mathcal{X} = \mathbb R^d\)。 从\(\boldsymbol x^{(t)}\)出发试转移,令 \[\begin{aligned} \boldsymbol y = \boldsymbol x^{(t)} + \boldsymbol\varepsilon_t, \end{aligned}\] 其中\(\boldsymbol\varepsilon_t \sim g(\boldsymbol x; \sigma)\)对不同\(t\)是独立同分布的, \(T(\boldsymbol y | \boldsymbol x) = g(\boldsymbol y - \boldsymbol x)\)。 设\(g\)是关于\(\boldsymbol x = \boldsymbol 0\)对称的分布, 则\(T(\boldsymbol y | \boldsymbol x) = T(\boldsymbol x | \boldsymbol y)\)。
常取\(g\)为N(\(\boldsymbol 0\), \(\sigma^2 I\))和半径为\(\sigma\)的中心为\(\boldsymbol 0\)的球内的均匀分布。
转移法则为: 从\(\boldsymbol x^{(t)}\)出发试转移到\(\boldsymbol y\)后, 若\(\pi(\boldsymbol y) > \pi(\boldsymbol x^{(t)})\)则令\(\boldsymbol x^{(t+1)} = \boldsymbol y\); 否则, 独立地抽取\(U \sim \text{U}(0,1)\), 取 \[\begin{aligned} \boldsymbol x^{(t+1)} =& \begin{cases} \boldsymbol y, & \text{当 }U \leq \pi(\boldsymbol y)/\pi(\boldsymbol x^{(t)}), \\ \boldsymbol x^{(t)}, & \text{其它}. \end{cases} \end{aligned}\]
随机游动MH算法是一种Metropolis抽样方法。 随机游动的步幅\(\sigma\)是重要参数,步幅过大导致拒绝率大, 步幅过小使得序列的相关性太强,收敛到平衡态速度太慢。 一个建议选法是试验各种选法, 使得试抽样被接受的概率在0.25到0.35之间。 见 Liu (2001) § 5.4 P. 115.
例19.3 考虑如下的简单气体模型: 在平面区域\(G = [0,A]\times[0,B]\)内有\(K\)个直径为 \(d\)的刚性圆盘。 随机向量\(\boldsymbol X = (x_1, y_1, \ldots, x_K, y_k)\)为这些圆盘的位置坐标。 分布\(\pi(\boldsymbol x)\)是\(G\)内所有允许位置的均匀分布。希望对\(\pi\)抽样。
先找一个初始的允许位置\(\boldsymbol x^{(0)}\)。比如,把圆盘整齐地排列在左上角。
设已得到\(\boldsymbol x^{(t)}\),随机选取一个圆盘\(i\),把圆盘\(i\)的位置试移动到 \((x_i', y_i') = (x_i + \delta_i, y_i + \epsilon_i)\), 其中\(\delta_i, \epsilon_i\)独立同N(0, \(\sigma^2\))分布。 如果得到的位置是允许的则接受结果,否则留在原地不动。
下面给出R实现。 运行参数:
N <- 100 # 重复抽样个数
A <- 3.5 # 摆放区域宽度
B <- 3.5 # 摆放区域高度
d <- 0.8 # 圆盘直径
K <- 6 # 圆盘个数
r <- d/2 # 圆盘半径
d2 <- d^2
sigma <- 0.5 # 随机移动的标准差
oldpar <- par(pty="s", bty="n", mar=c(0,0,1,0))用来画出一个圆盘的函数。
x, y为圆心,r为半径。
circ <- function(x,y,r,...){
n <- 30
theta <- seq(0, 2*pi, length=n)
xx <- x + r * cos(theta)
yy <- y + r * sin(theta)
lines(xx,yy,...)
}初始摆放,将所有6个圆盘整齐地摆放在区域的左下角位置:
x <- rep(seq(r+0.01, length=3, by=d+0.01),2)
y <- c(rep(r+0.01, 3), rep(3*r+0.01, 3))
plot(c(-d,A+d), c(-d,B+d), type="n", axes=FALSE,
xlab="", ylab="")
lines(c(0,A,A,0,0), c(0,0,B,B,0), lwd=2)
for(i in 1:K) circ(x[i], y[i], r)
locator(1)下面定义一个函数,对要移动的圆盘,看要移动到的新位置是否与其他圆盘矛盾。
x, y是新的圆心位置,i是要移动的圆盘序号。
fit <- function(xnew, ynew, i){
res <- xnew > r && xnew < A-r && ynew > r && ynew < B-r
res <- res && all((x[-i] - xnew)^2 + (y[-i] - ynew)^2 > d2)
res
}其中的x, y将使用外部的变量值。
下面产生\(N-1\)个新的位置。 每次尝试移动,直到移动成功。
set.seed(1)
nfit <- 0 # 总成功次数
tt <- 0 # 总尝试次数
batch <- FALSE
while(nfit <= N){
tt <- tt + 1
i <- sample(1:K, 1) # 随机选一个圆盘移动
xnew <- x[i] + rnorm(1, 0, sigma) # 产生尝试的新位置
ynew <- y[i] + rnorm(1, 0, sigma)
isfit <- fit(xnew, ynew, i)
## 画出尝试移动
plot(c(-d,A+d), c(-d,B+d), type="n", axes=FALSE,
xlab="", ylab="")
text(A, -0.1*d, "BATCH") # 画简单的图上按钮
lines(c(0,A,A,0,0), c(0,0,B,B,0), lwd=2) # 画边框
for(j in 1:K) if(j != i) circ(x[j], y[j], r) # 画不移动的那些圆盘
circ(x[i], y[i], r, lty=2) # 画要移动的圆盘的原始位置,虚线
if(isfit){ # 可移动
nfit <- nfit + 1
circ(xnew, ynew, r, col="blue") # 画出要移动的圆盘的新位置
x[i] <- xnew; y[i] <- ynew
} else {
circ(xnew, ynew, r, col="red") # 尝试的新位置是不可行的
}
title(main=paste("t = ", tt, " success = ", nfit, sep=""))
if(tt <= 40){ # 前40次要求用户点击
menu <- locator(1)
}
if(!batch && tt > 40){ # 40次以后,允许不再点击就继续模拟
menu <- locator(1)
if(menu$x > A-0.2 && menu$y < 0.2) batch=TRUE
}
}
cat("Acception rate = ", round( N / tt * 100, 1), "%\n")
par(oldpar)※※※※※
19.3 Gibbs抽样
一般的MH抽样每一步首先进行尝试从上一步的状态进入一个新的状态, 然后根据新的状态是否靠近目标分布来接受或拒绝试抽样点, 如果拒绝,就停留在上一步的状态,效率较低。
Gibbs抽样是另外一种MCMC方法, 它仅在坐标轴方向尝试转移, 用当前点的条件分布决定下一步的试抽样分布, 所有试抽样都被接受, 不需要拒绝, 所以效率可以更高。
设状态用\(\boldsymbol x = (x_1, x_2, \dots, x_n)\)表示, 设目标分布为\(\pi(\boldsymbol x)\), 用\(\boldsymbol x_{(-i)}\)表示\((x_1\), \(\ldots\), \(x_{i-1}\), \(x_{i+1}\), \(\ldots\), \(x_n)\), 假设\(\pi(\cdot)\)的条件分布 \(p(x_i | \boldsymbol x_{(-i)})\)都能够比较容易地抽样。
Gibbs抽样每一步从条件分布中抽样, 可以轮流从每一分量抽样, 这样的算法称为系统扫描Gibbs抽样算法:
\[\begin{aligned} \qquad & \text{从} \pi(\boldsymbol x) \text{的取值区域任意取一个初值} \boldsymbol X^{(0)} \\ & \text{for}(t \text{ in } 0:(N-1)) \{ \\ & \qquad \text{for} (i \text{ in } 1:n) \{ \\ & \qquad\qquad \text{从条件分布} p(x_i | X_1^*, \dots, X_{i-1}^*, X_{i+1}^{(t)}, \dots, X_n^{(t)}) \text{抽取} X_i^* \\ & \qquad \} \\ & \qquad \boldsymbol X^{(t+1)} \leftarrow (X_1^*, \dots, X_n^*) \\ & \} \end{aligned}\]
从条件分布抽样的次序也可以是随机选取各个分量, 这样的算法称为随机扫描Gibbs抽样算法:
\[\begin{aligned} \qquad & \text{从} \pi(\boldsymbol x) \text{的取值区域任意取一个初值} \boldsymbol X^{(0)} \\ & \text{for}(t \text{ in } 0:(N-1)) \{ \\ & \qquad \text{按概率} \boldsymbol\alpha = (\alpha_1, \dots, \alpha_n) \text{随机抽取下标} i \\ & \qquad \text{从条件分布} p(x_i | \boldsymbol X_{(-i)}^{(t)}) \text{抽取} X_i^* \\ & \qquad \boldsymbol X^{(t+1)} \leftarrow (X_1^{(t)}, \dots, X_{i-1}^{(t)}, X_i^*, X_{i+1}^{(t)}, \dots, X_{n}^{(t)}) \\ & \} \end{aligned}\]
其中下标的抽样概率\(\boldsymbol \alpha\)为事先给定。
容易看出,无论采用系统扫描还是随机扫描的Gibbs抽样, 如果\(\boldsymbol X^{(t)}\)服从目标分布, 则\(\boldsymbol X^{(t+1)}\)也服从目标分布。 以系统扫描方法为例, 设在第\(t+1\)步已经抽取了\(X_1^{*}, \dots, X_{i-1}^{*}\), 令\(\boldsymbol Y = (X_1^{*}, \dots, X_{i-1}^{*}, X_i^{(t)}, \dots, X_{n}^{(t)})\), 设\(\boldsymbol Y \sim \pi(\cdot)\)。 下一步从\(\pi(\cdot)\)的边缘密度 \(p(x_i | X_1^{*}, \dots, X_{i-1}^{*}, X_{i+1}^{(t)}, \dots, X_{n}^{(t)})\)抽取\(X_i^*\), 则\(\boldsymbol Y^* = (X_1^{*}, \dots, X_{i-1}^{*}, X_i^*, X_{i+1}^{(t)}, \dots, X_{n}^{(t)})\) 的分布密度在\(\boldsymbol Y^*\)处的值为 \[\begin{aligned} & p(X_1^{*}, \dots, X_{i-1}^{*}, X_i^*, X_{i+1}^{(t)}, \dots, X_{n}^{(t)}) \\ =& p(X_i^* | X_1^{*}, \dots, X_{i-1}^{*}, X_{i+1}^{(t)}, \dots, X_{n}^{(t)}) \;p(X_1^{*}, \dots, X_{i-1}^{*}, X_{i+1}^{(t)}, \dots, X_{n}^{(t)}) \\ =& \pi(X_1^{*}, \dots, X_{i-1}^{*}, X_i^*, X_{i+1}^{(t)}, \dots, X_{n}^{(t)}) \end{aligned}\] 即\(\boldsymbol Y \sim \pi(\cdot)\)则\(\boldsymbol Y^* \sim \pi(\cdot)\)。
例19.4 设目标分布为二元正态分布,设\(\boldsymbol{X} \sim \pi(\boldsymbol{x})\)为 \[ \text{N}\left\{ \left( \begin{array}{c} 0 \\ 0 \end{array} \right), \left( \begin{array}{cc} 1 & \rho \\ \rho & 1 \end{array} \right) \right\} \]
采用系统扫描Gibbs抽样方案,每一步的迭代为, \[\begin{aligned} & \text{抽取 } X_1^{(t+1)} | X_2^{(t)} \sim \text{N}(\rho X_2^{(t)}, \, 1-\rho^2) \\ & \text{抽取 } X_2^{(t+1)} | X_1^{(t+1)} \sim \text{N}(\rho X_1^{(t+1)}, \, 1-\rho^2) \end{aligned}\] 递推可得 \[\begin{align} \left( \begin{array}{c} X_1^{(t)} \\ X_2^{(t)} \end{array} \right) \sim& \text{N} \left\{ \left( \begin{array}{c} \rho^{2t-1}X_2^{(0)} \\ \rho^{2t} X_2^{(0)} \end{array} \right), \left( \begin{array}{cc} 1 - \rho^{4t-2} & \rho - \rho^{4t-1} \\ \rho - \rho^{4t-1} & 1 - \rho^{4t} \end{array} \right) \right\} \tag{19.5} \end{align}\] 当\(t \to \infty\)时,\((X_1^{(t)}, X_2^{(t)})\)的期望与目标分布期望之差为\(O(|\rho|^{2t})\), 方差与目标分布方差之差为\(O(|\rho|^{4t})\)。
例19.5 设目标分布为 \[\begin{aligned} \pi(x,y) \propto \binom{n}{x} y^{x+\alpha-1} (1-y)^{n-x+\beta-1}, \ x=0, 1, \ldots, n, \ 0 \leq y \leq 1, \end{aligned}\] 则\(X | Y \sim\) B(\(n,y\)), \(Y | X \sim\) Beta(\(x+\alpha, n-x+\beta\))。 易见\(Y\)的边缘分布为Beta(\(\alpha, \beta\))。 可以用Gibbs抽样方法模拟生成\((X,Y)\)的样本链。
下面用Julia语言实现这个模拟, 并用抽样样本估计\(\theta=EY\)。 在这个例子中,我们重点演示如何选取抽样量\(N\)与老化期(预热期)长度\(N_1\)。
先取定模拟参数α, β和n。 调入用于随机数生成的包Random和Distributions, 用于作曲线图的包CairoMakie:
在下面为了度量分段平均值是否不相关, 需要一个计算一阶自相关系数的函数, 这里自己定义一个这样的函数:
function autocor1(x::Vector)
n = length(x)
s = 0.0
s2 = 0.0
sc = 0.0
for k=1:(n-1)
s += x[k]
s2 += x[k]^2
sc += x[k]*x[k+1]
end
xm = (s + x[n])/n # 均值
s2 += x[n]^2
s2 = (s2 - n*xm^2)/(n-1) # 方差
sc = (sc - (n+1)*xm^2 + xm*(x[1]+x[n]))/(n-1) # 协方差
scor = sc/(s2*(n-1)/n)
scor
end针对不同的总抽样长度\(N\), 可以写出模拟生成样本的函数:
function simtrial(N=1000)
x = zeros(Int, N+1)
y = zeros(Float64, N+1)
x[1] = 0
y[1] = rand(Beta(α,β))
for k=1:N
# 系统扫描Gibbs算法
x[k+1] = rand(Binomial(n, y[k]))
y[k+1] = rand(Beta(x[k+1]+α, n-x[k+1]+β))
end
(x[2:(N+1)], y[2:(N+1)])
end在生成模拟样本后,交互地确定预热期长度。 一种办法是用逐步平均值作图查看需要的预热期长短。 令 \[ \bar y_k = \frac{1}{k} \sum_{i=1}^k y_i, \ k=1,2,\dots,N \] 为逐步平均值。 当逐步平均值相比开始的时候不再剧烈震荡,就可以认为已经过了预热期。 先定义一个计算序列的逐步平均序列的函数:
暂时取总长度\(N=1000\)进行模拟,然后用逐步平均值图形查看预热期长度:
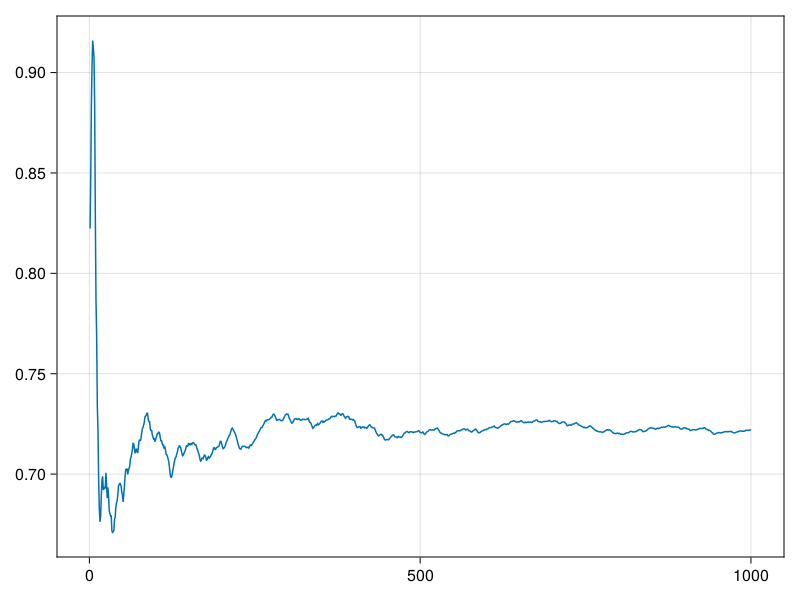
可以看出,在经过200次迭代后平均值已经比较稳定,但是一直到\(N=1000\)时,平均值都有一定的上升趋势。 为了进一步确认向平稳分布的收敛,增大到\(N=10000\):
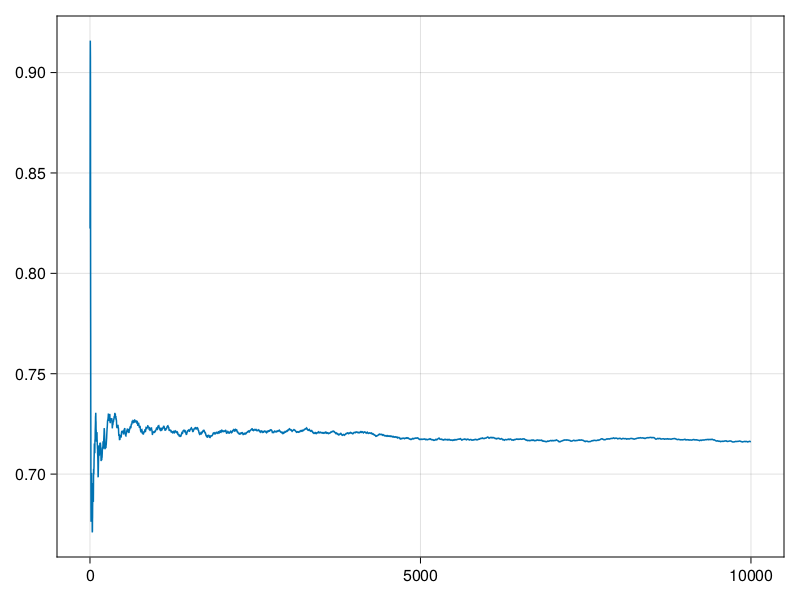
从这个图看出,\(N=1000\)确实有些不足,取预热期为\(N_1=2000\),利用最后的8000点作为抽样。 要注意的是,从局部看, 经过预热期之后,这样的迭代平均值仍会有波动, 只不过波动幅度变小了许多而已:
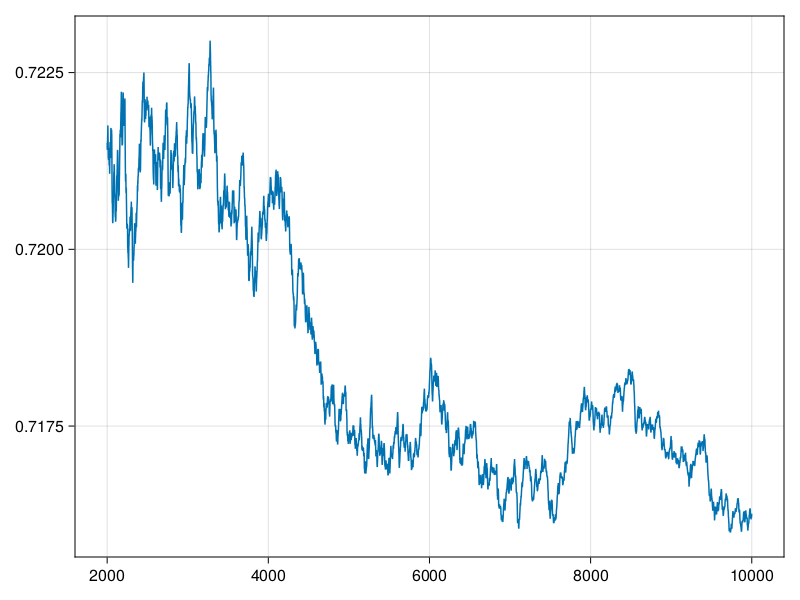
从上图看仍在剧烈震荡,但实际上变动幅度已经仅在0.715到0.725之间了。 现在用第2001到10000点的观测值估计\(\theta=EY\), 令\(\hat\theta\)为最后\(N_2 = N-N_1\)的\(Y\)样本的平均值:
\(Y\)的边缘分布期望的理论值:
用8000个抽样给出了\(EY\)的一个估计, 从与理论值的比较来看精度还不错。 但是,随机模拟的结果具有随机性, 我们需要评估随机模拟的估计精度。 因为MCMC方法产生的是相关样本, 所以不能利用独立同分布样本的\(\sigma/\sqrt{N}\)公式估计样本均值的标准差。
可以将样本分成若干段, 每段\(r\)个样本点, 对每段计算平均值, 在每段长度\(r\)足够长以后这些分段平均值应该是近似不相关的。 下面的函数分段计算均值:
function segavg(x::Vector, r)
# x 是输入向量
# r 是每段长度, m是分段数
n = length(x)
m = Int(floor(n/r))
z = zeros(Float64, m)
for k=1:m
z[k] = mean(x[((k-1)*r+1):(k*r)])
end
z
end问题是,需要多长一段? 采用试验的方法。先试验\(r=100\)一段, 利用一阶自相关系数估计段之间的相关性。
这个自相关系数绝对值过大。 现在分段均值序列长度\(m=80\), 如果序列是独立同分布列的话, 由时间序列中的结论其一阶自相关系数应近似服从\(\text{N}(0, \frac{1}{m})\), 取值在\(\pm 2/\sqrt{m}\)范围是正常的:
这个界限也比较大, 所以我们应该每段应该更长, 并模拟更多的段数。 尝试改为\(r=1000\)和\(m=1000\), 这样\(N_2 = 10^6\):
N1 = 10_000
N2 = 1000_000
N = N1 + N2
Random.seed!(101)
x, y = simtrial(N)
avg = mavg(y)
lines(1:N, avg)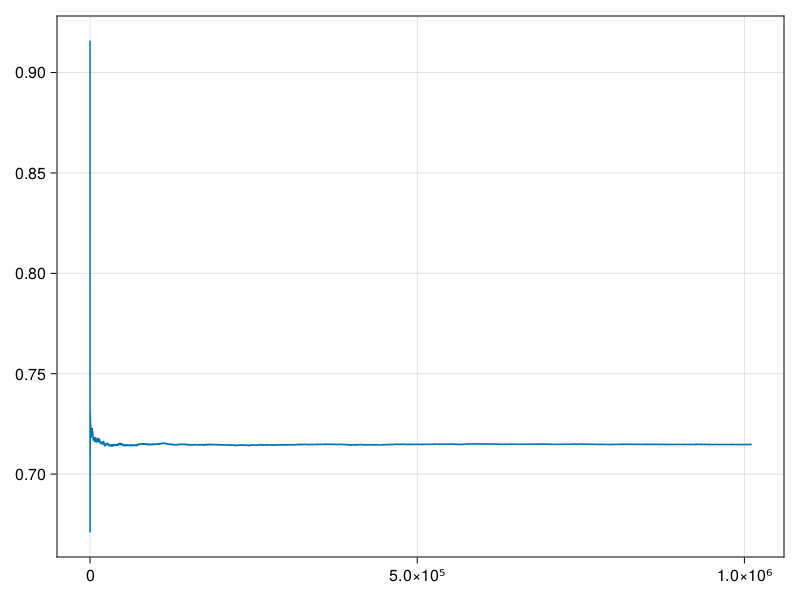
\(Y\)的均值估计:
尝试计算每段\(r=1000\)个点的分段平均值, 共有\(m=1000\)段, 再次评估这样的分段长度是否合适:
r = 1000 # 试验使用的每段长度
m = 1000 # 段数
z = segavg(yout, r)
round.((autocor1(z), 2/sqrt(m)), digits=5)
## (-0.03673, 0.06325)第二个数是自相关的合理界限, 这个界限已经比较小; 第一个数是各段均值的自相关, 这个自相关的绝对值受到界限的控制而且比较小, 可以这样分段估计\(\hat\theta\)的标准误差。 用分段平均值的标准差来估计\(\hat\theta\)的标准误差, 用\(N_2=10^6\)个样本点给出的点估计\(\hat\theta\)的标准误差估计为
这说明\(EY\)的估计值可报告为\(\hat\theta=0.715\),精度在小数点后三位。 为了增加一位有效数字精度,需要抽样量增大100倍,到一亿的级别。
※※※※※
例19.6 在Gibbs抽样中,每次变化的可以不是单个的分量,而是两个或多个分量。 例如,设某个试验有\(r\)种不同结果, 相应概率为\(\boldsymbol p = (p_1, \dots, p_r)\)(其中\(\sum_{i=1}^r p_i = 1\)), 独立重复试验\(n\)次, 各个结果出现的次数\(\boldsymbol X = (X_1, \dots, X_r)\)服从多项分布。 设\(A = \{ X_1 \geq 1, \dots, X_r \geq 1 \}\), 假设\(P(A)\)概率很小, 要在条件\(A\)下对\(\boldsymbol X\)抽样, 如果先生成\(\boldsymbol X\)的无条件样本再舍弃不符合条件\(A\)的部分则效率太低, 可以采用如下的Gibbs抽样方法。
首先,任取初值\(\boldsymbol X^{(0)}\), 如\(\boldsymbol X^{(0)} = (1,\dots,1)\)。 假设已生成了\(\boldsymbol X^{(t)}\), 下一步首先从\((1, \dots, r)\)中随机地抽取两个下标\((i,j)\), 令\(s = X_i^{(t)} + X_j^{(t)}\), 在给定\(X_k, k \neq i,j\)为\(\boldsymbol X^{(t)}\)对应元素的条件下, \((X_i, X_j)\)的条件分布实际是\((X_i, X_j)\) 在\(X_i + X_j = s\)以及\(X_i \geq 1, X_j \geq 1\)条件下的分布。 于是,在以上条件下, \(X_i\)服从B(\(s, p_i/(p_i+p_j)\))分布限制在\(1 \leq X_i \leq s-1\)条件下的分布, 即 \[\begin{aligned} q_k =& P(X_i=k | X_i+X_j=s, X_i \geq 1, X_j \geq 1) \\ =& \frac{C_s^k \left(\frac{p_i}{p_i + p_j} \right)^k \left(\frac{p_j}{p_i + p_j} \right)^{s-k}} {1 - \left(\frac{p_j}{p_i + p_j} \right)^s - \left(\frac{p_i}{p_i + p_j} \right)^s}, \ k=1,2,\dots,s-1. \end{aligned}\] 要生成这样的\(X_i\)的抽样只要用生成离散型随机数的逆变换法。 设抽取的\(X_i\)值为\(X_i^*\), 取\((X_i^{(t+1)}, X_j^{(t+1)}) = (X_i^*, s - X_i^*)\), 取\(\boldsymbol X^{(t+1)}\)的其它元素为\(\boldsymbol X^{(t)}\)的对应元素。 如此重复就可以生成所需的\(\boldsymbol X\)在条件\(A\)下的抽样链。
※※※※※
19.4 MCMC计算软件(*)
MCMC是贝叶斯统计计算中最常用的计算工具。 OpenBUGS是一个成熟的MCMC计算开源软件(见 (Lunn et al. 2009), (Cowles 2013), 另一个类似的有关软件是WinBUGS(Lunn et al. 2000)), 能够进行十分复杂的贝叶斯模型的计算, 可以在R中直接调用OpenBUGS进行计算。
OpenBUGS采用Gibbs抽样方法从贝叶斯后验分布中抽样, 用户只需要指定先验分布和似然函数以及观测数据、已知参数, 以及并行地生成多少个马氏链、链的一些初值、运行步数。 软件自动计算Gibbs抽样所需的条件分布, 产生马氏链, 并可以用图形和数值辅助判断收敛性, 给出后验推断的概括统计。
在R中通过BRugs包调用OpenBUGS的功能。 BRugs用三类输入文件指定一个贝叶斯模型, 第一类文件指定似然函数和参数先验密度, 第二类文件指定已知参数、样本值, 第三类文件指定马氏链初值(并行产生多个链时需要指定多组初值)。 R的coda软件包可以帮助对MCMC抽样结果进行分析和诊断。 下面用一个简单例子介绍在R中用BRugs和OpenBUGS从贝叶斯后验中抽样的基本步骤。
例19.7 对例19.2,用R的BRugs包调用OpenBUGS来计算。 设\((X_1,\dots, X_5)\)的观测值为\((74, 85, 69, 17, 5)\)。
OpenBUGS用模型文件描述随机变量分布和对参数的依赖关系,
以及参数之间的关系。
首先建立如下模型文件, 保存在文件pfl-model.txt中:
model
{
p[1] <- 1/3
p[2] <- (1-b)/3
p[3] <- (1-2*b)/3
p[4] <- 2*b/3
p[5] <- b/3
b <- b2 / 2
b2 ~ dbeta(1,1)
x[1:5] ~ dmulti(p[1:5], N)
}文件中用向左的箭头表示确定性的关系,
用方括号加序号表示下标,
用\(\sim\)表示左边的变量服从右边的分布。
这里,\(b\)为参数\(\beta\),
\(\mbox{b2} = 2 b\)服从Beta(1,1)分布即U(0,1)分布,
于是\(\beta\)有先验分布U(0,0.5)。
x[1:5]表示向量\((x_1, \dots, x_5)\),
服从多项分布,参数为\((p_1, \dots, p_5)\),
试验次数为\(N\)。
\(N\)在模型文件中没有指定,将在数据文件中给出。
建立如下的数据文件,保存在文件pfl-data.txt中:
list(x=c(74, 85, 69, 17, 5),
N=250)这样的数据文件是R软件的列表格式, 列表中的标量和向量为通常的R程序写法, 矩阵用如
list(M=structure(.Data=c(1,2,3,4,5,6), .Dim=c(3,2)))表示,其中.Dim给出矩阵的行、列数(\(3\times 2\)),
.Data给出按行排列的所有元素(第一行为1,2, 第二行为3,4,
第三行为5,6)。
OpenBUGS需要用户指定各个链的要抽样的参数的初值,
这里我们要抽样的参数是b,
但b是由b2计算得到的,
所以对b2设置初值。
设有如下两个初值文件,不同链的初值应尽可能不同,
文件pfl-inits1.txt内容为:
list(b2=0.2)文件pfl-inits2.txt内容为:
list(b2=0.8)在R中,首先调用BRugs软件包:
然后,读入并检查模型文件:
读入数据文件:
下面,对模型和数据进行编译,得到抽样方案, 下面的语句要求并行运行两个链:
准备迭代地生成MCMC抽样了,首先指定初值:
下面,先试验性地运行1000次,作为老化期:
现在才指定抽样要输出那些随机变量的随机数:
现在可以抽样了,指定运行10000次,两个链并行运行:
得到抽样后,可以把抽样的结果保存在R的变量中,比如
得到一个列表,
有唯一的元素b,
为\(2\times 10000\)的矩阵,
每行是一个链的记录。
sampleHistory可以抽样链的曲线图,如
OpenBUGS提供了一系列的简单统计和收敛诊断功能。 如下程序列出各抽样变量的简单统计:
结果为:
mean sd MC_error val2.5pc median val97.5pc start sample
b 0.08757 0.016900 1.168e-04 0.05737 0.08668 0.12330 1001 20000
p[2] 0.30410 0.005632 3.892e-05 0.29230 0.30440 0.31420 1001 20000
p[3] 0.27500 0.011260 7.784e-05 0.25120 0.27550 0.29510 1001 20000
p[4] 0.05838 0.011260 7.784e-05 0.03824 0.05778 0.08217 1001 20000
p[5] 0.02919 0.005632 3.892e-05 0.01912 0.02889 0.04109 1001 20000统计使用所有链的数据。
可以看出,\(\beta\)的后验均值为0.08757。
表中的MC_error表示估计后验均值时由于随机模拟导致的误差的标准差的估计,
这个标准差估计针对抽样自相关性进行了校正。
在老化期之后的运行次数越多MC_error越小,
一个常用的经验规则是保证MC_error小于后验标准差的5,
这里的结果提示还需要更多的运行次数。
val2.5pc和val97.5pc是抽样的后验分布的2.5%和97.5%分位数的估计值,
由此得到\(\beta\)的水平95%的可信区间(credible interval)为
\((0.0574, 0.1233)\)。
如下程序画出b的后验密度估计:
samplesDensity('b', mfrow=c(1,1))如下程序画抽样的b的自相关函数估计:
samplesAutoC('b', 1, mfrow=c(1,1))当自相关函数很大而且衰减缓慢时生成的抽样链的效率较低。 本例中的自相关函数基本表现为不相关列。
为了检查链是否收敛, OpenBUGS提供了BGR统计量图:
samplesBgr('b', mfrow=c(1,1))BGR统计量的原理是考虑并行运行的每个链内部的变化情况, 以及把所有的链合并在一起的变化情况, 对这两种变化情况进行比较, 当链收敛时,每个链内部的变化情况应该与合并在一起的变化情况很类似。 类似于单因素方差分析中组间平方和与组内平方和的比较。 当BGR图中的红色线接近于1并且三条线都保持稳定时就提示链收敛了。
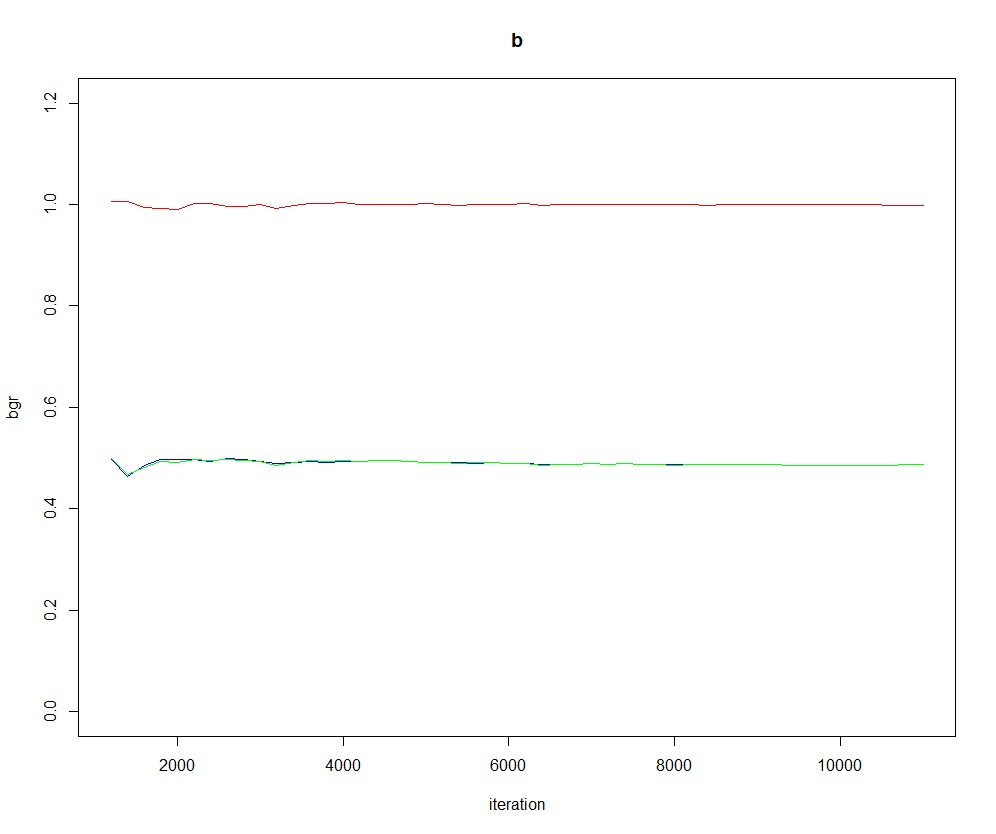
※※※※※
习题
习题1
设\(\{X_t, t=0,1,\dots \}\)为状态取值于\(S = \{ 1,2,\dots,m \}\)的马氏链, 有平稳分布\(\pi_j, j=1,2,\dots,m\), 若\(X_0\)服从平稳分布, 证明所有\(X_t\)都服从平稳分布(\(t\geq 0\))。
习题2
在例19.1中, 设\(n=100\), \(a = 10000\), 编写R程序产生MCMC抽样链。
习题3
在例19.2中, 设\((x_1, x_2, x_3, x_4, x_5)=(82, 72, 45, 34, 17)\), 选取适当的预热期和模拟,编写R程序计算\(\beta\)的后验均值估计。 从不同初值出发多做几次考察估计的误差大小。
习题4
在例19.3中, 设\(A=10, B=10\), \(d=1\), \(K=11\), 选取适当的预热期和步幅\(\sigma\), 编写R程序产生MCMC抽样链。
习题5
设向量\(\boldsymbol x = (x_1, \dots, x_n)\), 每个\(x_i\)取值为\(+1\)或\(-1\),记这样的\(\boldsymbol x\)的集合为\(\mathcal X\)。 设随机向量\(\boldsymbol X\)有如下概率质量函数 \[\begin{aligned} \pi(\boldsymbol x) = P(\boldsymbol X = \boldsymbol x) = \frac{1}{Z} \exp\left\{ \mu \sum_{i=1}^{n-1} x_i x_{i+1} \right\} \end{aligned}\] 其中\(\mu\)已知, \(Z\)为归一化常数。 这样的模型称为一维Ising模型。 取\(\mu=1, n=50\), 设计MCMC算法从\(\pi(\boldsymbol x)\)抽样。
习题7
对例19.5, 取\(n=20\), \(\alpha=\beta=0.5\), 生成\((X,Y)\)的Gibbs抽样链, 比较\(Y\)的样本的直方图和Beta(\(\alpha, \beta\))分布密度。