A R软件基础(*)
R是一个用于统计计算、绘图和数据分析的自由软件, 最初由新西兰Auckland大学的Ross Ihaka和Robert Gentleman 于1997年发布, 现在由R核心团队开发维护, 全世界的用户都可以贡献软件包。 R软件使用R语言, R语言直接提供了向量、矩阵、数据框、一般对象等高级数据结构, 其语法简单易学, 功能强大,尤其适用于开发新的统计算法, 用R语言编写程序就像写公式一样简单, 也可以调用C、C++、Fortran等编译语言的代码实现附加功能或提高计算效率。 R软件通过附加软件包(package)的方式提供了各种经典的统计方法以及最新的统计方法, R的网站 http://www.r-project.org/上已经有超过1.8万个软件包(截止2022年4月), 还有一些软件包发布在github、Bioconductor等网站。 R软件已经成为全世界统计学家研究新算法和进行统计计算的首选软件之一, 在生物、金融、医药、工农业等各行各业的数据分析中也获得了广泛应用。
R语言可以看成是S语言的一个变种, S语言是Rick Becker, John Chambers等人在贝尔实验室开发的一个用于交互数据分析和作图的软件, 最初的版本开发于1976-1980年, 后来又有改进(见(R. A. Becker and Chambers 1984), (Richard A. Becker, Chambers, and Wilks 1988), (Chambers and Hastie 1992))。
这一节讲述R软件的基础用法, 这样读者可以用R语言实现自己的算法, 本书的算法也用类似R语言的语法描述。 R软件的进一步使用需要读者自己阅读R手册和R软件的相关书籍, 可参考李东风的统计软件教程。
A.1 向量
R软件可以在图形界面内以命令方式交互运行,
也可以整体地运行存放在扩展名为.R或.r的程序文件中的代码。
如果有某个R程序存放在当前目录中的mysrc.R文件中,
如下命令可以运行这样的程序文件:
R语言最基本的数据类型是向量(vector), 这是R的对象中最简单的一种。 标量(单个的数值或字符串)可以看成是长度为1的向量。 数值型的R向量基本可以看成是线性代数中的向量, 但不区分行向量和列向量; 与其它程序语言相比, R向量相当于其它程序语言中的一维数组, 可以保存若干个相同基本类型的值, 各个元素用向量名和序号(下标)访问, 下标从1开始计数。
R中用函数c()来把若干个元素组合为一个向量, 如
定义了一个长度为5、数据类型为数值(numeric)的向量,
保存在名为marks的变量中。
R中把向量等数据保存在变量中, 如上例的marks,用<-为变量赋值。
R中的变量名可以由字母、数字、句点、下划线组成,
变量名的第一个字符只能是字母或句点,
如果以句点开头必须有第二个字符并且第二个字符不能是数字, 变量名长度不限。
变量名是大小写区分的,所以Amap和amap是不同的名字。
为了访问向量x的第3个元素,只要用x[3]这种方法, 下标是从1开始计数的。
也可以直接修改一个元素,如
在R命令行环境中输入变量名然后按Enter键可以查看变量的值。
如果在程序文件中要显示变量值x的值, 应当使用print(x)。
更一般的输出可以用cat函数显示文本和数据值,如
其中"\n"表示换行。 cat的各项输出自动用空格分隔,
在cat中加sep=""选项表示各项之间不分隔。
可以用“start:stop”的方法定义一个由连续整数值组成的向量,
比如11:13为向量\((11,12,13)\)。
用rep(x, times)可以把向量x重复times次,
比如rep(c(1,3), 2)结果为向量\((1,3,1,3)\)。
用rep(x, each=...)可以把向量x的每个元素重复each次,
如rep(c(1,3), each=2)结果为向量\((1,1,3,3)\)。
如果一个文本文件中用空格和换行分隔保存了多个数值,
用函数scan可以把这些数值读入到一个数值型向量中, 如
其中mydata.txt是当前目录下的一个文本文件,
保存了用空格和换行分隔的数值。
R的基本数据类型包括数值型(numeric)、 字符型(character)、逻辑型(logical)、复数型(complex)。 为了定义一个指定长度、元素初始化为0数值型向量, 方法如
则变量x保存了由4个零组成的数值型向量。
字符型常量可以用两个单撇号或两个双撇号界定,如
R的逻辑型只有真值TRUE、假值FALSE和 缺失值NA三个不同取值。
复数型常量写成如1.2 - 3.3i这样的形式, 虚数单位\(i\)可以写成1i。
和C、C++、Fortran、Java这些严格类型的程序设计语言不同,
R的变量不需要事先声明数据类型。
为了动态地获知某个向量x当前所保存的基本数据类型,
可以调用函数typeof(x),
结果为字符串"integer"、"double"、"character"、"logical"或 "complex"。
"integer"、"double"可以归为"numeric"类别。
基本类型之间可以用as.xxx类的函数进行转换,
比如as.numeric(c(TRUE, FALSE))结果为 数值型向量\((1,0)\)。
向量元素中用NA表示缺失值, 如
但是没有上下文的一个NA被认为是逻辑型的。
向量是R对象中的一种。
R对象用属性用来区分不同数据类型或者对数据附加额外描述信息,
基本类型(mode)就是所有R对象都有的基本属性,
另一个基本属性是长度(length),
用函数length(x)可以返回向量x的元素个数。
为了访问R向量的子集,除了一个元素可以用“”
的格式访问之外,还可以用一个正整数向量作为下标,
比如marks[c(1,5)]结果为\((10,8)\),
把marks的第3到第5号元素赋值为零。
向量下标还可以取为负整数或负整数向量,
如(11:15)[-5]是(11:15)去掉了第5个元素之后 的结果\((11,12,13,14)\),
(11:15)[-c(1,5)]是(11:15)去掉了第1和第5号元素之后
的结果\((12,13,14)\)。
R向量可以定义元素名并使用元素名作为下标, 比如
则可以用得到元素值7, 用得到 结果\((10, 7)\)。
所有元素的元素名组成一个字符型向量, 这是向量的对象属性之一。
可以用names(x)取得向量x的元素名向量, 也可以用如
这样的方法定义或修改元素名属性。
注意,这里赋值符号左边的names(marks)是对象属性的一种表示方法,
不能看成是给一个函数结果赋值。
R程序允许自动续行。 只要前一行程序明显地没有完成, 就可以直接拆分到下一行, 没有配对的括号是前一行程序没有完成的一种常见情况。 在一行的开头或中间以#号开始注释,#以及该行的后续内容都作为注释。 另外,两个语句可以用分号分隔后写在同一行中,比如
因子 (factor)是一种特殊的向量: 元素只能在有限个“水平”中取值, 元素值编码为正整数值保存, 可以用来表示分类变量的观测值。 例如
生成一个水平为“男”和“女”的因子, 用levels(fac)可以查看其各个水平,
用as.numeric(fac)可以查看其编码值, 此例为\((1,1,2,1)\);
用as.character(fac)可以转换为字符型。
A.2 向量运算
R的算术运算符为
+ - * / %% %/% ^分别表示加、减、乘、除、除法余数、整除、乘方。 算术运算的优先级为先乘方、再乘除、最后加减, 可以用圆括号来改变运算次序。 有缺失值参加的四则运算结果还是缺失值。
向量可以和一个标量进行算术运算,
结果为向量的每个元素与标量进行计算得到的新向量。
如(11:14) + 100的结果为向量 \((111, 112, 113, 114)\),
2^(0:4)的结果为向量 \((1, 2, 4, 8, 16)\)。
两个长度相同的向量进行算术运算,
结果为对应元素进行算术运算后得到的新向量。
比如(11:14) - (1:4)结果为向量 \((10,10,10,10)\)。
如果两个向量长度不同,但较大长度是较小长度的整数倍,
则这两个向量也可以进行算术运算, 在运算时把短的一个循环重复使用。 比如,
(11:14) + c(100, 200)结果为向量 \((111, 212, 113, 214)\)。
在R中,允许对一个向量调用数学中的一元函数,
函数输出结果为每个元素取函数值后组成的新向量,比如
sqrt(c(1,4,9))的结果为向量 \((1,2,3)\)。 类似的函数还有 abs(x)
(\(|x|\)), exp(x) (\(e^x\)), log(x) (\(\ln x\)), log10(x) (\(\lg x\)),
sin(x), cos(x), tan(x), asin(x)(反正弦), acos(x)(反余弦),
atan(x)(反正切), atan2(y,x)。
atan2(y,x)函数求平面直角坐标系中原点到点\((x,y)\)的向量与x轴的夹角,
对第I、II象限和x轴上的点,结果取值于\([0,\pi]\),
对第III、IV象限的点,结果取值于\((-\pi, 0)\)。
R的比较运算符为
== != < <= > >=可以表示两个标量比较, 两个等长向量比较,
或两个长度不等但是长度为倍数的两个向量比较,
结果是对应元素比较的结果组成的逻辑型向量。
如(1:4) > (4:1)结果为逻辑型向量 (FALSE, FALSE, TRUE, TRUE),
(1:3) > 1.5的结果为逻辑型向量 (FALSE, TRUE, TRUE),
(1:4) > (3:2)结果为逻辑型向量 (FALSE, FALSE, FALSE, TRUE)。
R用%in%运算符表示元素“属于”集合的判断,
如果a是一个标量,A是一个向量,
把A看成一个集合(集合的元素就是A的各个分量),
a %in% A的结果就是\(a \in A\)是否成立的结果。 如果B是一个向量,
B %in% A就是对B的每个元素分别判断是否属于A的结果。 比如,
c(2,-2) %in% (1:3)结果为(TRUE, FALSE)。
为了判断向量y的所有元素都属于向量x是否成立,
可以用setdiff(y,x)求集合y减去集合x的差集,
如果length(setdiff(y,x))==0为真 则说明向量y的所有元素都属于向量x。
集合运算函数还有union(x,y)(并集)、intersect(x,y)(交集)、
setequal(x,y)(相同集合)、 is.element(el, set)(属于判断)。
R定义了如下的逻辑运算符:
& | !其中&表示逻辑与(同时为真才为真), |表示逻辑或(任一为真则为真),
!表示逻辑非(真变成假,假变成真), 两个逻辑向量之间可以进行逻辑运算,
含义为对应元素的运算。 一般用来把比较运算连接起来得到复杂条件,比如
表示年龄在 18和59之间(含18和59),
表示妇女或年龄在3岁以下(含3岁),
表示年龄在18岁以下或59岁以上(不含18和59)。
为了表示所有元素都满足一个条件, 用函数all(),
如all(age >= 18)表示向量age中所有年龄都在18岁以上。
类似地,函数any()表示向量中有任一元素满足条件。
R中比较和逻辑运算的一个重要作用是按条件挑选向量元素子集。
比如,要挑选向量marks中分数在5分以下(含5分)的元素, 可以用如
这是因为R的向量下标允许取为和向量长度相同的一个逻辑向量。
这样取子集可能取到空集, 结果表示为numeric(0),
即长度为零的数值型向量。
A.3 矩阵
R语言支持矩阵(matrix)和数组(array)类型, 矩阵是数组的特例。
数组有一个属性dim, 比如
定义了一个数组,元素分别为1到24, 每个元素用3个下标访问,
第一个下标可取1和2, 第二个下标可取1, 2, 3, 第三个下标可取1, 2, 3, 4。
数组元素在填入各下标位置时,第一下标变化最快,
第三下标变化最慢,这种排序叫做FORTRAN次序或列次序。
比如,arr中元素的次序为 arr[1,1,1], arr[2,1,1], arr[1,2,1],
arr[2,2,1], \(\ldots\), arr[2,3,4]。
矩阵是dim属性为两个元素的向量的数组,
矩阵元素用两个下标访问,第一下标可以看作是行下标,
第二下标可以看作列下标, 元素按列优先次序存储。 因为矩阵是最常用的数组,
所以单独提供一个matrix函数用来定义矩阵, 如
为了让矩阵元素按行填入,定义时可指定 byrow=TRUE,如
单个数组元素用两个下标访问,如上述M的第2行第3列元素 用M[2,3]访问。
可以取出M的一行或一列组成一个向量, 格式如M[1,],
表示M的第一行组成的向量 (不再是矩阵,所以不区分行向量和列向量),
M[,2]表示M的第二列组成的向量。
可以取出若干行或若干列组成子矩阵,
比如M[,2:3]取出M的第2列和第3列组成的
\(2\times 2\)子矩阵。取出子矩阵时如果仅有一行或仅有一列,
子矩阵会退化成R向量而不再有维数属性,
可以用M[,1,drop=FALSE]这样的方法要求取子集时数组维数不变。
用函数cbind可以把一个向量转换为列向量(列数等于1的矩阵),
或者把若干个向量、矩阵横向合并为一个矩阵。
用函数rbind可以转换行向量或进行纵向合并。
矩阵有两维(行维、列维), 每一维都可以定义维名当作下标使用。
对上述矩阵M, 如下命令定义了矩阵列名:
这样,M的第二列可以用M[,"X2"]访问,
M的第一列和第二列组成的子矩阵可以用 M[,c("X1", "X3")]访问。
类似地可以定义行名并用行名代替行下标:
这时M显示如下:
列名和行名没有命名规则限制, 但不应有重复值以免不能唯一地标识列和行。
矩阵首先是二维数组, 形状相同的矩阵可以进行对应元素之间的四则运算, 运算符与向量的四则运算符相同。 比如,设
则
M + M1
## X1 X2 X3
## John 2 1 4
## Mary 3 6 7
M - M1
## X1 X2 X3
## John 0 3 2
## Mary 5 4 5
M * M1
## X1 X2 X3
## John 1 -2 3
## Mary -4 5 6
M / M1
## X1 X2 X3
## John 1 -2 3
## Mary -4 5 6
M ^ M1
## X1 X2 X3
## John 1.00 0.5 3
## Mary 0.25 5.0 6分别对M和M2的对应元素作加法、减法、乘法、除法、乘方,
结果是形状相同的矩阵。
对于加法和减法,结果与线性代数中两个矩阵相加和相减是一致的。
矩阵可以和标量作四则运算,结果是矩阵的每个元素与该标量进行四则运算。 如果是矩阵与标量相乘,结果与线性代数中数乘结果相同。
两个矩阵相乘用%*%运算符表示。 比如
表示矩阵M左乘矩阵M1的转置 (函数t()表示矩阵转置)。
另外,crossprod(A)表示\(A'A\), crossprod(A, B)表示\(A'B\)。
如果\(A\)是可逆方阵,用solve(A)求逆矩阵\(A^{-1}\)。
对线性方程组\(A x = b\), 用solve(A, b)可以求出线性方程组的解\(x\)。
A.4 数据框
数据框(data frame)是类似于矩阵的数据类型,
但是它允许同时保存数值型、字符型和因子型数据, 每列的类型必须相同。
数据框每列必须有变量名, 用names(df)访问数据框df的各个变量名。
统计数据经常以数据框的形式保存。
用函数read.csv可以把CSV(逗号分隔)格式的文件转换为R数据框,
用函数write.csv可以把R数据框保存为CSV格式的文件。
A.5 分支和循环
R语言因为内置了向量、矩阵这样的高级数据类型, 所以编程比较容易。 很多其它语言中必须用分支、循环结构解决的问题在R语言中可以 用更简洁的代码处理。
R中用
处理分支结构,其中“条件”应该是一个逻辑型标量。 else部分可省略,
但是有else部分时两部分必须在同一个语句中。 例如
也可写成
上例中使用了复合语句。 R中可以用左右大括号把若干个语句组合成一个复合语句, 在程序中当作一个语句使用。
if结构中的条件必须是标量。 在上述问题中如果x是一个向量,
可以改用如下的逻辑下标的方法:
这样可以根据x元素的不同取值而对y的相应元素赋值。
R语言中用for结构进行对向量下标或向量元素进行遍历(循环), 格式为
其中idvar是循环变量,“范围”是下标向量或一般向量。
比如,下例中对向量x的下标循环以计算元素总和:
x <- 11:15
s <- 0
for(k in seq(along=x)){
s <- s + x[k]
cat('k=', k, 'x[k]=', x[k], 's=', s, '\n')
}
## k= 1 x[k]= 11 s= 11
## k= 2 x[k]= 12 s= 23
## k= 3 x[k]= 13 s= 36
## k= 4 x[k]= 14 s= 50
## k= 5 x[k]= 15 s= 65其中seq(along=x)获得向量x的下标向量(本例中为1:5)。
使用seq(along=x)而不是1:length(x),
是因为x可以是零长度的,这时1:length(x)为1:0,
即1和0两个元素,是错误的。
还可以直接对x的元素循环,如
x <- 11:15
s <- 0
for(item in x){
s <- s + item
cat('item=', item, 's=', s, '\n')
}
## item= 11 s= 11
## item= 12 s= 23
## item= 13 s= 36
## item= 14 s= 50
## item= 15 s= 65在不能预知循环次数时,可以使用当型循环,格式为
当循环继续条件成立时反复执行循环体语句, 直到条件不成立时才不再执行。 如果一开始循环继续条件就不成立, 就一次也不执行循环体语句。
在计算机算法中还有所谓*直到型循环**, R没有直接提供直到型循环的语法结构, 在本书的算法描述中有时用如下的直到型结构:
执行循环直到循环退出条件成立时才退出循环, 循环至少执行一次。 R中可以用如下方法模仿直到型循环:
其中repeat是无条件循环语句, break跳出一重循环。
在本书的算法描述中, 使用了类似于R语言语法的伪代码,
伪代码与程序类似,但允许使用描述性的操作说明。
伪代码中主要用到
if ... else ..., for循环, while循环, until循环等控制结构。
在R中,for、while、repeat循环效率较低,
比用FORTRAN、C等编译型语言的计算速度可能慢几个数量级。
R中的循环常常是可以设法避免的。 比如,sum(x)可以直接得到x的元素和。
类似的函数还有mean(x)求平均值, prod(x)求所有元素的乘积,
min(x)求最小值, max(x)求最大值, sd(x)求样本标准差,
cumsum(x)计算元素累加和(包括各中间结果),
cumprod(x)计算元素累乘积,等等。
R的apply、lapply、sapply、 mapply、 vapply、
replicate、 tapply、rapply 等函数隐含了循环。
函数apply可以对矩阵的各行或各列循环处理,
比如,apply(M, 1, sum)表示对M的各行求和,
而apply(M, 2, mean)表示对M的各列求平均。
函数lapply(X,FUN, ...)可以把函数
FUN分别作用于X的每一个元素(比如数据框的每个变量),
输出一个包含这些作用结果的列表,...是FUN所需要的其它自变量。
sapply(X,FUN,...)与lapply(X,FUN...)类似
但尽可能把结果转换为向量或数组。
vapply与sapply作用类似,但需要自己指定输出类型。
mapply(FUN, ...)是把sapply推广到FUN为多元函数的情况。
replicate(n, expr)经常用于重复n次模拟,
expr是调用一次模拟的表达式。
rapply可以把函数作用到嵌套列表的最底层。
R中提供了若干个函数可以进行快速计算, 如fft计算离散傅立叶变换,
convolve计算离散卷积, filter计算滤波或自回归迭代。
R这样的函数很多, 需要用户能够根据函数的帮助信息,
自己构造一些简单可手工验证算例, 快速掌握这些函数的使用。
对于必须使用循环的情况, 如果需要重复的次数不多, 用R的循环不会造成效率损失; 如果重复次数很多, 可以考虑把重复很多的循环改为C代码或C++代码, R的Rcpp软件包支持在R代码内嵌入C代码和C++代码。
A.6 函数
R内置了许多函数,比如,sin(x)可以计算向量x的每个元素的正弦值,
seq(a,b)可以生成从a到b的等差数列,
sum(x)可以计算x的所有元素的总和。
R的函数在调用时可以按照自变量位置调用, 如seq(2,5)结果为(2,3,4,5),
也可以在调用时指定自变量名, 这时自变量次序不再重要,
如seq(to=5, from=2)结果还是(2,3,4,5);
还可以前一部分按自变量位置对应, 后一部分指定自变量名,
如seq(2, length=4)结果仍为(2,3,4,5)。
模块化程序设计是保证软件正确、可复用、易升级的重要方法, 而自定义函数是模块化设计的主要组成部分。 在R中用如下格式定义一个新的函数:
其中函数体内最后一个表达式的值是函数的返回值。 可以为空,表示不需要自变量, 但是括号不能省略。 形式参数表可以是用逗号分开的形式参数名, 并可以带有用等于号给出的缺省值。 例如
调用如demean(c(1,2,3)), 则缺省参数xbar用给出的表达式计算,
返回值为(-1,0,1)。 还可以调用如demean(c(1,2,3), xbar=1)或
demean(c(1,2,3), 1), 结果为(0,1,2)。
函数只能返回一个表达式的结果, 可以是标量、向量、矩阵、数据框或其它更复杂的类型。 为了能够同时返回多个结果, 可以把这些结果组合成为一个列表(list)类型。 列表定义如
则此列表包含了回归系数向量、检验的\(F\)统计量和相应的p值。
设上述列表保存在列表变量li中, 为了访问li的pvalue元素,
可以用li[["pvalue"]]、li$pvalue或 li[[3]]的格式。
用names(li)查询或修改列表的元素名。 为了删除列表中某项,
只要将其赋值为特殊的NULL值,表示不存在的值,
NULL与NA不同,NA表示存在但是缺失的值。
R自定义函数内,形式参数是局部的, 即形式参数和函数定义外其它变量重名时不会有冲突。 在函数定义内赋值变量是局部的, 即使函数定义外部有同名变量也不会给外部的同名变量赋值。 然而,如果在函数定义内读取某个变量的值, 此变量的值在函数内无定义但是在它的外部环境中有定义, 运行时可以读取外部定义的值, 这是一个需要小心的特点, 因为在较长的函数定义中可能忘记给变量赋值而使用了外部环境中同名变量的值。
在数据分析时, 经常将前一步的输出作为后一步的输入, 比如,
可以简写成
但这样写就不容易辨认处理步骤是先进行f1()变换,
再进行f2()变换,
R提供了如下的“管道”运算符用来表示函数复合:
也可以有更多的复合运算。
在f1()和f2()中也可以有其他选项,如:
A.7 简单输入输出
对一个R变量x,用print(x)显示其内容;
如果在命令行状态,
直接用x可以显示变量或表达式x的值。
用cat()函数显示若干个字符串和向量值,如
其中最后的"\n"表示换行。
在cat()中加file=选项要求将欲显示的内容保存到指定文件中,
加选项append=TRUE使得写入到文件时在文件末尾添加而不是替换原有内容。
如:
用scan()函数将用空格和换行分隔的保存在文件中的数值读入为向量。如
用write.csv()将一个数据框或矩阵保存为CSV格式,
这是用逗号分隔两项的格式,
第一行是列名,
这样的格式可以被Excel软件自动判读为表格,
也被大多数的数据处理软件支持。
例如:
用read.csv()读入一个CSV文件。
要求第一行是列名,
后续行的每一个单元格是一个单独的值,
不能有合并格或者公式、图形。
如
A.8 RStudio介绍
RStudio是R软件的一个功能强大的集成环境, 对R软件进行了很多功能增强。 这是一个商业软件, 但提供了免费的功能缩减版本, 免费版本也能满足一般用户的需要。 尤其适用于用Rmd格式制作HTML、Word、PDF、网站、图书、演示等。
软件的界面分为四个窗格, 主要有编辑窗格、命令行窗格、文件窗格等。 在屏幕分辨率较低时可以用Ctrl+Shift+1等快捷键使得某一个窗格最大化, Ctrl+Shift+1使得编辑窗口最大化, Ctrl+Shift+2使得命令行窗口最大化, Ctrl+Shift+5使得文件窗口最大化,等等。 下面是RStudio界面的一个截图:
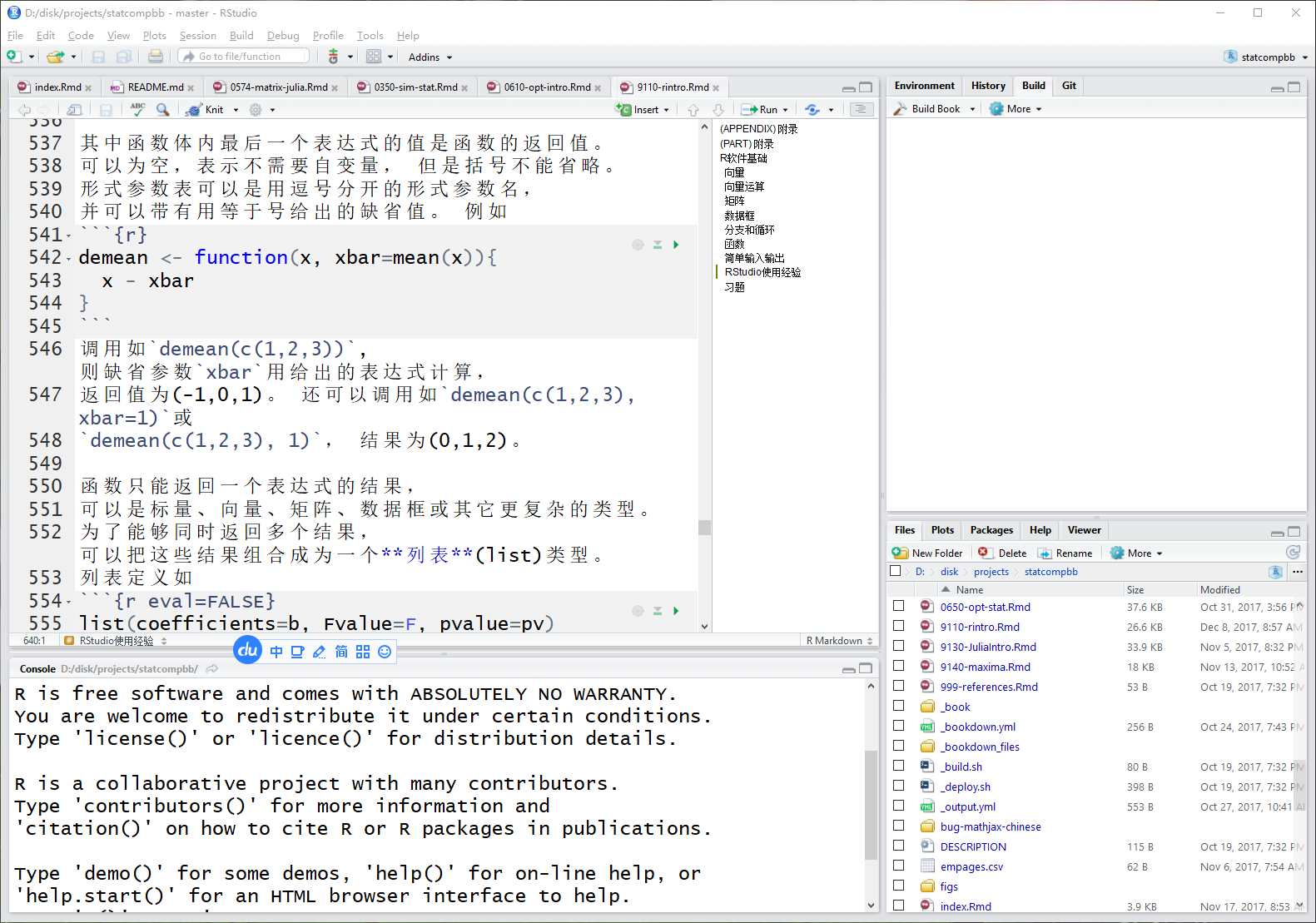
图A.1: RStudio界面
使用RStudio进行一个统计研究或者统计数据分析项目, 一般将有关的文件存放在计算机的一个子目录(文件夹)中, 然后从RStudio的文件菜单, 建立一个新“项目”(project), 将项目与文件存放的子目录关联在一起。 子目录中包括数据、R脚本文件(扩展名.r或.R)、R markdown文件(扩展名.Rmd)等。 关于使用RStudio制作文档、网站、图书、演示稿, 参见李东风的R语言教程。
习题
习题1
设x是一个长度为n的向量,写一段程序,计算x的长度为s的滑动和:
\[
S_x (t) = \sum\limits_{i = 0}^{s - 1} {x_{t - i} } ,\quad t = s,s + 1,\ldots ,n
\]
(提示:使用R的filter()函数)