A 时间序列与R
A.1 本课程的软件需求
金融时间序列分析课需要学生掌握一定的运用统计软件进行建模分析的能力。 作为基础, 学生需要重点掌握R软件如下功能:
- 基本数据类型,日期和日期时间类型,数据输入输出
- Rmd格式文件运用
- 时间序列类型zoo, xts, timeSeries类型
- quantmod包
关于R软件基本使用, 详见李东风的R软件教程, 第1、2章,第9章。
关于Rmd格式文件, 详见李东风的R软件教程, 第19–21章。
关于R软件与金融时间序列分析的较详细的介绍, 参见李东风的《金融时间序列分析》研究生课程讲义。
参考:
A.2 基本R使用
R是一个数据分析、统计建模和作图的软件, 其中包含一门计算机语言称为R语言, 此语言与通常的C、C++、Java等编程语言相比, 支持更多的数据类型, 如向量、矩阵, 并提供了多种统计和数学计算方法。
为了在金融时间序列计算中使用R语言, 这里简单介绍一些最基本的使用方法。
R软件是一个开源软件, 可以免费地从其网站http://www.r-project.org提供的镜像网站下载安装。 另外, RStudio是一个R软件的集成开发环境, 在该软件中可以更方便地使用R软件, 虽然RStudio是商业软件, 但非商业用户可以免费地使用。
R可以在命令行运行, 每次运行一条命令, 结果显示在命令下方。 也可以将多条R命令写成一个源程序文件, 然后运行整个文件。 在RStudio软件中也可以选中若干行程序, 运行选中的部分。
A.2.1 四则运算
R中用+ - * / ^分别表示加、减、乘、除、乘方。
数值可以写成如123, -123, 123.45,
1.23E-5这样的形式,
其中1.23E-5表示\(1.23 \times 10^{-5}\)。
A.2.3 向量
R中最基本的单位是向量,
单个数值是长度为1的向量。
简单的向量可以用c(...)定义,如
长度相同的两个向量之间可以做四则运算, 结果是对应的元素进行四则运算。 单个元素可以和一个向量进行四则运算, 结果是该元素与向量的每一个元素进行四则运算。 如
A.2.4 矩阵
R支持矩阵类型,
矩阵是有\(n\)行、\(p\)列的数值排列成的存储结果,
在第\(i\)行、第\(j\)列有一个数值元素。
矩阵A的第\((i,j)\)元素表示为A[i,j],
矩阵的第\(j\)列作为一个向量,
可以表示为A[,j,drop=TRUE]。
nrow(A)求A的行数,
ncol(A)求A的列数。
两个相同形状的矩阵可以进行加、减、乘、除四则运算, 结果是对应的元素进行四则运算。 单个元素可以与矩阵进行四则运算, 结果是该元素与矩阵的每个元素进行四则运算。
两个向量x1和x2,
可以用cbind(x1, x2)合并为两列的矩阵。
A.2.5 数据框
R数据框是和矩阵类似的存储结构, 但是允许不同列的数据类型不同, 比如, 一列是日期, 一列是评级(字符串), 一列是收益率(数值)。
数据框的每一列都有列名,
用names(d)或者colnames(d)访问。
将数据框d的某一列取出作为一个向量,
用d[["列名"]]的格式。
A.2.6 扩展包
R的许多功能由不同的扩展包(package)提供。
为了调用某个扩展包的功能,
需要先用library()命令载入该扩展包,
如
某些扩展包还允许用包名::函数名()的格式直接调用其中的函数。
A.2.7 日期和日期时间
R日期可以保存为Date类型, 一般用整数保存,数值为从1970-1-1经过的天数。
R中用一种叫做POSIXct和POSIXlt的特殊数据类型保存日期和时间, 可以仅包含日期部分, 也可以同时有日期和时间。 技术上,POSIXct把日期时间保存为从1970年1月1日零时到该日期时间的时间间隔秒数。 日期时间会涉及到所在时区、夏时制等问题, 比较复杂。
lubridate是一个提供了许多日期和日期时间功能的扩展包。
对于"2018-07-02"这样的字符型的日期,
可以用lubridate::ymd("2018-07-02")这样的方法转换成Date类型,
该函数也可以输入字符型向量,向量的每个元素是一个日期字符串,
结果为Date类型元素组成的向量。
如果year, mon, day分别是数值类型的年、月、日,
可以用lubridate::make_date(year, mon, day)转换成Date类型。
lubridate::ymd_hms()可以将"2018-07-02 13:15:59"这样的日期和时间字符串转换成POSIXct类型,
lubridate::make_datetime()可以将单独的整数表示的年、月、日、时、分、秒转换成POSIXct类型。
lubridate包的year(), month(), mday()可以从日期或日期时间中取出年、月、日,
hour()、minute()、second()可以从日期时间中取出时、分、秒。
更详细的用法见R软件教程。
A.2.8 读入时间序列数据
常见的数据形式是用文本格式保存, 数据之间用空行、空格或者逗号分隔。
A.2.8.1 单个向量读入
最简单的情况是仅有一个序列,
数据仅包含序列的数值而不包含时间标签,
这时数据可以保存为用空行和空格分隔的文本格式数据,
例如文件sp500-2691.txt是标准普尔500指数月超额收益率从1926年1月到1991年12月的数据,
内容为(节选):
0.0225 -0.044 -0.0591 0.0227 0.0077 0.0432 0.0455 0.0171 0.0229 -0.0313 0.0223 0.0166
-0.0208 0.0477 0.0065 0.0172 0.0522 -0.0094 0.065 0.0445 0.0432 -0.0531 0.0678 0.019
-0.0051 -0.0176 0.1083 0.0324 0.0127 -0.0405 0.0125 0.0741 0.024 0.0145 0.1199 0.0029
0.0571 -0.0058 -0.0023 0.0161 -0.0428 0.1124 0.0456 0.098 -0.0489 -0.1993 -0.1337 0.0253可以用如下程序读入成R向量:
A.2.8.2 带有时间标签的序列
有些序列带有时间标签,
同一行的数据之间用空格或者制表符分隔。
文件d-ibm-0110.txt为IBM股票从2001-1-2到2010-12-31的日简单收益率,
部分数据如下:
date return
20010102 -0.002206
20010103 0.115696
20010104 -0.015192
20010105 0.008719
20010108 -0.004654
20010109 -0.010688
20010110 0.009453可以用如下程序读入成一个R数据框:
其中的日期可以用如下程序转换成R的Date类型:
有些序列的年月日是分开输入的,
比如,
文件m-unrate.txt为美国从1948年1月到2010年9月的经季节调整的月失业率百分数,
部分数据如:
Year mon dd rate
1948 01 01 3.4
1948 02 01 3.8
1948 03 01 4.0
1948 04 01 3.9
1948 05 01 3.5可以用如下程序读入为R数据框, 并生成日期列:
d <- read.table(
"data/m-unrate.txt", header=TRUE,
colClasses=rep("numeric", 4))
d[["date"]] <- lubridate::make_date(d[["Year"]], d[["mon"]], d[["dd"]])同一个有多个序列时, 也可以用如上方法读入为R数据框。
A.2.8.3 读入csv格式
CSV文件也是一种文本格式的数据文件, 相对而言更规范一些, 所以经常用于在不同的数据管理和数据分析软件之间传递数据。 数据如:
"date","ibm","sp"
"19260130",-0.010381,0.022472
"19260227",-0.024476,-0.043956
"19260331",-0.115591,-0.059113
"19260430",0.089783,0.022688
"19260528",0.036932,0.007679
"19260630",0.068493,0.043184
"19260731",0,0.045455可以用如下程序读入为R数据框:
A.3 生成时间序列数据
R软件中有些时间序列分析函数需要特定的时间序列类型数据作为输入。 常用的有ts类型、xts类型等。
ts类型用于保存一元或者多元的等间隔时间序列, 如月度、季度、年度数据。 生成方法如
其中x是向量或者矩阵,
取矩阵值时矩阵的每一列是一个序列。
frequency对月度数据是12,
对季度数据是4,
对年度数据可以缺省(值为1)。
start=c(2001,1)表示序列开始时间是2001年1月。
如果是年度数据,
用如ts(x, start=2001)即可。
例如,
文件m-unrate.txt
为美国从1948年1月到2010年9月的经季节调整的月失业率百分数,
转换成ts类型的程序如下:
d <- read.table(
"data/m-unrate.txt", header=TRUE,
colClasses=rep("numeric", 4))
unrate <- ts(d[["rate"]], start=c(1948,1), frequency=12)xts也是一种时间序列数据类型, 既可以保存等间隔时间序列数据, 也可以保存不等间隔的时间序列数据, 并且xts类型的数据访问功能更为方便。 读入方法例如
其中x是向量、矩阵或数据框,
date是日期或者日期时间。
x取矩阵或者数据框时每列是一个时间序列。
例如,
文件d-ibm-0110.txt为IBM股票从2001-1-2到2010-12-31的日简单收益率,
读入数据并转换为xts类型的程序如下:
library(xts)
d <- read.table(
"data/d-ibm-0110.txt", header=TRUE,
colClasses=c("character", "numeric"))
ibmrtn <- xts(d[["return"]], lubridate::ymd(d[["date"]]))有了xts类型的变量x后,
可以用coredate(x)返回x的不包含时间的纯数据;
用index(x)返回x的时间标签。
A.4 时间序列图形
对ts类型的时间序列x,用plot(x)作时间序列图。
对xts类型的时间序列,作图如:
library(xts)
xts.ap <- as.xts(AirPassengers)
plot(xts.ap, main="Air Passengers",
major.ticks="years", minor.ticks=NULL,
grid.ticks.on="years",
col="red")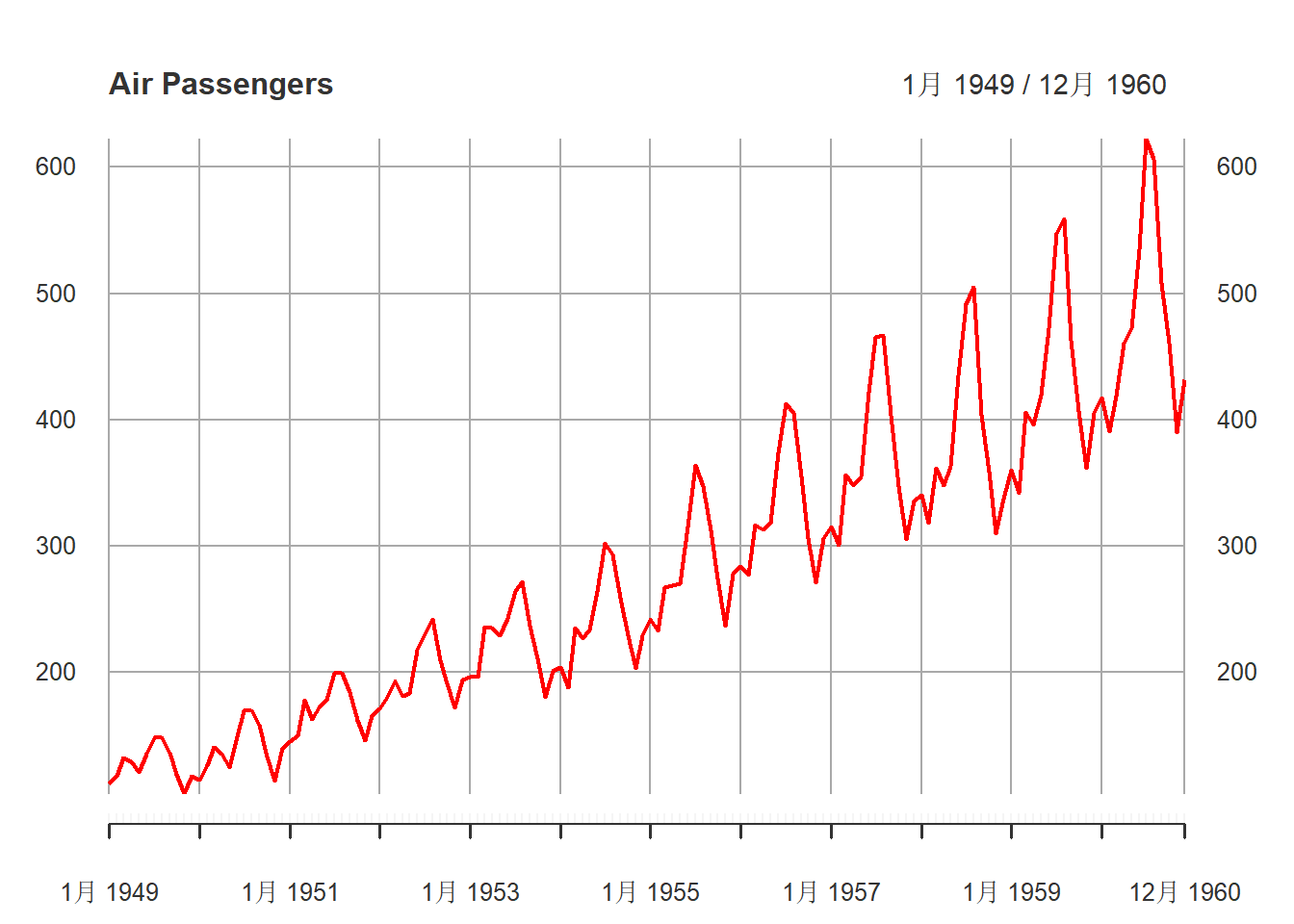
ACF图示例:
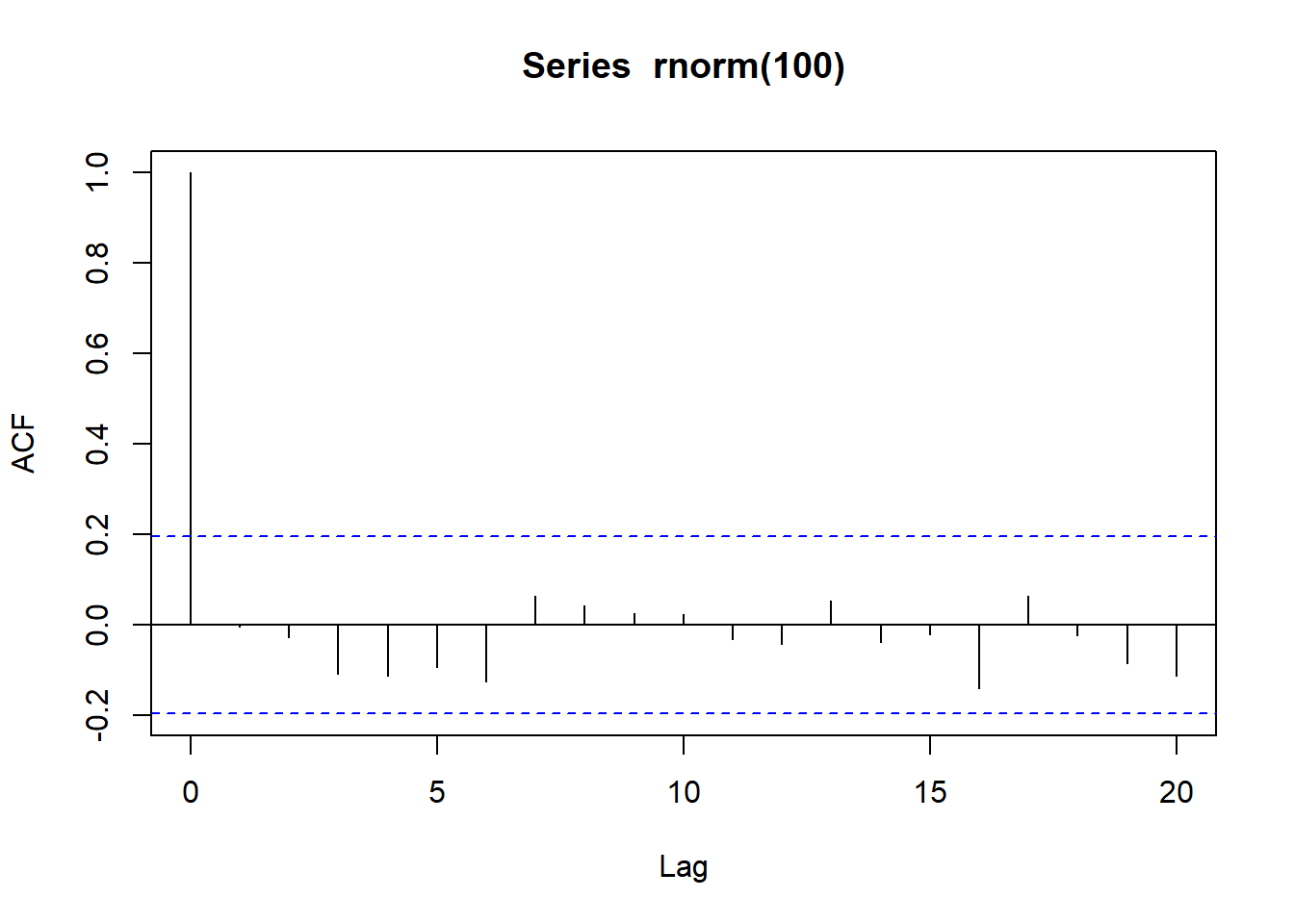
PACF示例:
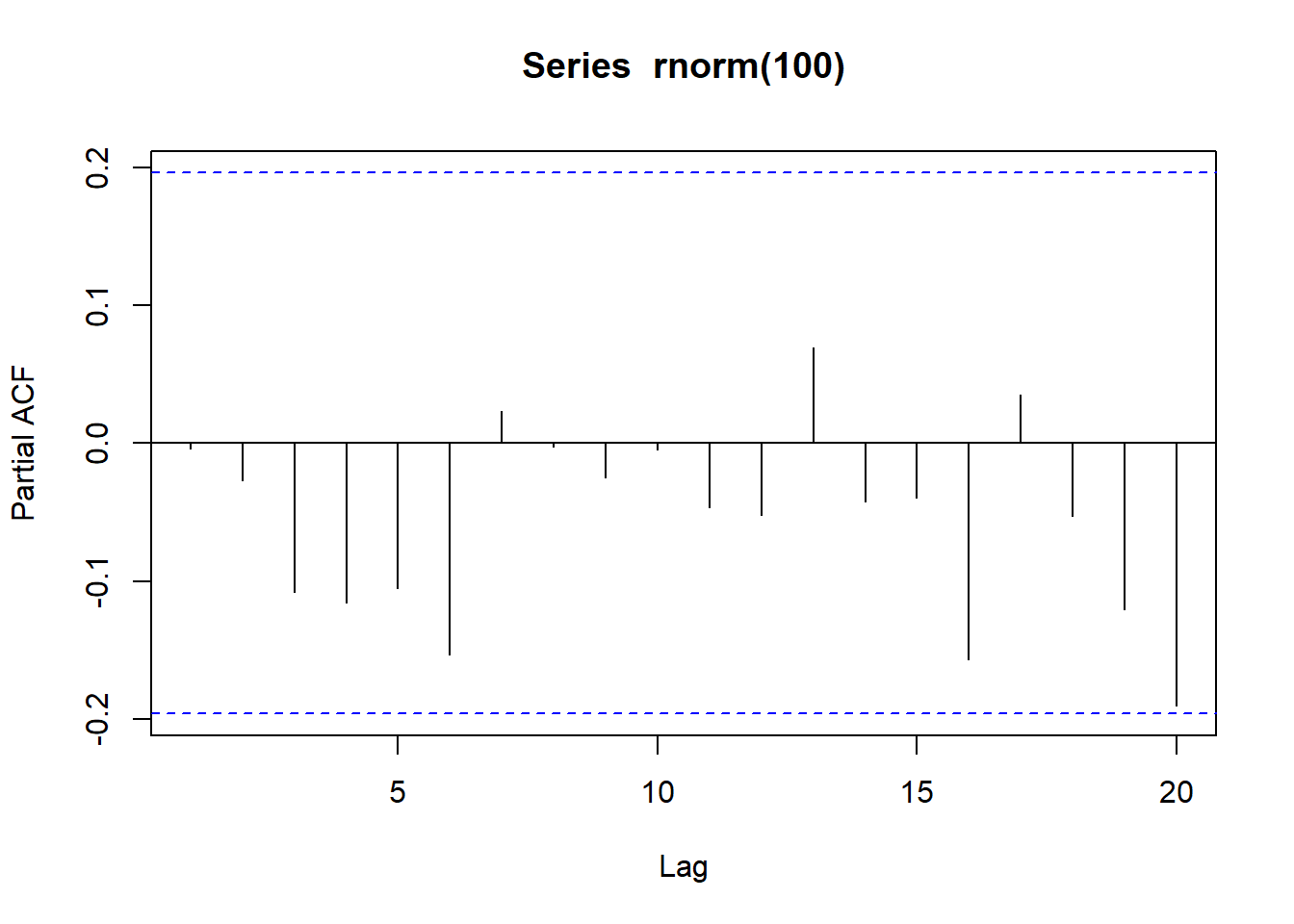
A.5 时间序列基本统计
对于一元时间序列,
仍可以用处理向量的函数如mean, sd, var,
min, max等函数进行统计。
长度可以用length求。
用diff(x)求一阶差分。
用acf(x)作样本自相关函数图,
自动给出上下两条界限作为白噪声情况下近似\(95\%\)界限。
用lag.max=指定需要的最大滞后阶数。
用type="covariance"可以返回样本自协方差估计。
acf()的返回值是一个列表,
对于一元时间序列,
c(acf(x)$acf)返回从滞后0到滞后lag.max的自相关函数值为一个向量,
c(acf(x, type="covariance")$acf)返回自协方差函数值为一个向量。
用pacf(x)作偏相关函数图。
自动给出上下两条界限用来则建立AR模型时帮助判断何处偏相关截尾。
A.6 ARIMA模型有关
可以模拟生成ARMA或者ARIMA模型的模拟数据。
用set.seed(n)在模拟前设置种子编号以保证模拟结果可重复。
用arima.sim()函数模拟生成AR、MA、ARMA或者ARIMA模型数据。
格式为
arima.sim(model, n, rand.gen = rnorm, innov = rand.gen(n, ...),
n.start = NA, start.innov = rand.gen(n.start, ...),
...)其中n是要输出的观测个数,
model是一个列表,
列表元素ar为AR部分的系数(写在方程右侧的格式),
列表元素ma为MA部分的系数,
列表元素order如果存在,
是\((p,d,q)\)三个元素的向量,
\(p\)是AR阶数,\(q\)是MA阶数,\(d\)是差分阶数。
三个列表元素都可以省略。
白噪声默认为零均值标准正态白噪声,
如果需要白噪声方程为\(\sigma^2\),
只要把生成的序列乘以\(\sigma\)。
在模拟ARMA时输出的是零均值序列。
可选参数可以提供一个用来产生白噪声列的随机数函数,
默认为rnorm函数。
可选参数innov可以规定为用户自己提供的白噪声列(R向量格式)。
可选参数n.start是为了达到平稳需要预热模拟的步数,
默认是程序自动选择。
可选参数start.innov可以提供预热阶段的白噪声输入。
例如,模拟如下的AR(2)模型,产生长度为300的样本: \[ X_t = 0.2 X_{t-1} + 0.5 X_{t-2} + \varepsilon_t, \ \varepsilon_t \sim \text{WN}(0, 2^2) \]
程序为:
又如,模拟如下的MA(2)模型, 产生长度为300的样本: \[ X_t = \varepsilon_t - 0.36 \varepsilon_{t-1} + 0.85 \varepsilon_{t-2}, \ \varepsilon_t \sim \text{WN}(0, 2^2) \]
程序为:
再比如,模拟如下的ARMA(4,2)模型,产生长度为300的样本:
\[ X_t = -0.9 X_{t-1} - 1.4 X_{t-2} - 0.7 X_{t-3} - 0.6 X_{t-4} + \varepsilon_t + 0.5 \varepsilon_{t-1} - 0.4 \varepsilon_{t-2}, \ \varepsilon_t \sim \text{WN}(0,2^2) \]
程序为:
模拟如下的ARIMA(1,1,1)模型,产生长度为300的样本: \[ Y_t = X_t - X_{t-1}, \quad X_t = -0.9 X_{t-1} + \varepsilon_t + 0.5 \varepsilon_{t-1}, \ \varepsilon_t \sim \text{WN}(0,2^2) \]
程序为:
为了建立AR模型,
并用AIC定阶,
用ar(x, method="mle")。
例如,对航空乘客数据对数差分序列:
##
## Call:
## ar(x = diff(log(AirPassengers)), method = "mle")
##
## Coefficients:
## 1 2 3 4 5 6 7 8
## -0.2212 -0.2835 -0.2550 -0.2973 -0.2300 -0.2621 -0.2571 -0.3274
## 9 10 11 12
## -0.2195 -0.2934 -0.1980 0.6020
##
## Order selected 12 sigma^2 estimated as 0.001643为了指定\((p,q)\)估计ARMA(\(p,q\))模型,
用arima(x, order=(p,0,q))。
比如,对航空乘客数据对数值差分序列建立ARMA(1,1)模型:
##
## Call:
## arima(x = diff(log(AirPassengers)), order = c(1, 0, 1))
##
## Coefficients:
## ar1 ma1 intercept
## -0.5826 0.8502 0.0098
## s.e. 0.1285 0.0856 0.0099
##
## sigma^2 estimated as 0.0102: log likelihood = 124.8, aic = -241.61上述输出对应的模型为:
\[\begin{aligned}
X_t =& 0.0098 + Y_t \\
Y_t =& -0.5826 X_{t-1} + \varepsilon_t + 0.8502 \varepsilon_{t-1},
\ \varepsilon_t \sim \text{WN}(0, 0.0102)
\end{aligned}\]
注意ar1系数是在模型方程等号右侧的,
sigma^2是白噪声方差\(\sigma^2\)的估计。
为了指定\((p,d,q)\)估计ARIMA模型,
用arima(x, order=(p,d,q))。
比如,对航空乘客数据对数值建立ARIMA(1,1,1)模型:
##
## Call:
## arima(x = log(AirPassengers), order = c(1, 1, 1))
##
## Coefficients:
## ar1 ma1
## -0.5780 0.8482
## s.e. 0.1296 0.0865
##
## sigma^2 estimated as 0.01027: log likelihood = 124.31, aic = -242.63上述模型应该写成: \[\begin{aligned} Y_t =& X_t - X_{t-1} \\ Y_t =& -0.5780 X_{t-1} + \varepsilon_t + 0.8482 \varepsilon_{t-1}, \ \varepsilon_t \sim \text{WN}(0, 0.01027) \end{aligned}\]
A.7 白噪声检验
用Box.test(x, lag=12, type="Ljung")作Ljung-Box白噪声检验,
用lag=指定采用多少个样本自相关系数的平方和计算卡方统计量。
对ARMA模型的输出,
可以加fitdf=指定ARMA模型的系数个数用来进行自由度调整,
必须满足lag>fitdf。
例如:
##
## Box-Ljung test
##
## data: rt(100, 5)
## X-squared = 1.1389, df = 1, p-value = 0.2859A.8 单位根检验
fUnitRoots包的adfTest()函数可以执行单位根ADF检验。 tseries包的adf.test()函数也可以执行单位根ADF检验。
adfTest(x, lags=1, type="nc")作ADF检验,
对应的AR阶数为1(用lags=1指定)。
用type="nc"表示不带漂移的随机游动,
用type="c"表示带有漂移的随机游动,
用type="ct"表示带有常数项和线性时间因素的随机游动。
如:
##
## Title:
## Augmented Dickey-Fuller Test
##
## Test Results:
## PARAMETER:
## Lag Order: 1
## STATISTIC:
## Dickey-Fuller: -2.0185
## P VALUE:
## 0.3072
##
## Description:
## Mon Nov 15 08:43:58 2021 by user: LenovoADF检验的零假设是有单位根,
对立假设是没有单位根。
上述检验的p值0.3072不显著,
表示有单位根。
因为序列有明显增长趋势所以用了type="c"选项,
表示有漂移的随机游动。