33 R多元回归
建模步骤:
- 确定要研究的因变量,以及可能对因变量有影响并且数据可以获得的自变量集合;
- 假定因变量\(y\)与\(p\)个自变量之间为线性相关关系,建立模型;
- 对模型进行评估和检验;
- 判断模型中是否存在多重共线性,如果存在,应进行处理;
- 预测;
- 残差分析。
33.1 模型
模型 \[ y = \beta_0 + \beta_1 x_1 + \dots + \beta_p x_p + \varepsilon \] 其中
- \(y\): 因变量,随机变量;
- \(x_1, \dots, x_p\): 自变量,非随机;
- \(\varepsilon\): 随机误差项,随机变量;
- \(\beta_0\): 截距项;
- \(\beta_j\): 对应于\(x_j\)的斜率项;
- 模型表明因变量\(y\)近似等于自变量的线性组合;
- \(E \varepsilon=0\), \(\text{Var}(\varepsilon)=\sigma^2\)。
对\(n\)组观测数据, 有 \[ y_i = \beta_0 + \beta_1 x_{i1} + \dots + \beta_p x_{ip} + \varepsilon_i, \quad i=1,2,\dots, n \] 对其中的随机误差项\(\varepsilon_i\), \(i=1,2,\dots,n\),假定:
- 期望为零,服从正态分布;
- 方差齐性: 方差为\(\sigma^2\)与自变量值无关;
- 相互独立。
总之,\(\varepsilon_1, \varepsilon_2, \dots, \varepsilon_n\) 相互独立,服从\(\text{N}(0, \sigma^2)\)分布。
数据格式如: \[ \left(\begin{array}{cccc|c} x_1 & x_2 & \cdots & x_p & y\\ \hline x_{11} & x_{12} & \cdots & x_{1p} & y_1 \\ x_{21} & x_{22} & \cdots & x_{2p} & y_2 \\ \vdots & \vdots & \ddots & \vdots & \vdots \\ x_{n1} & x_{n2} & \cdots & x_{np} & y_n \end{array}\right) \] R中回归数据放在一个数据框中,有一列\(y\)和\(p\)列自变量。
根据模型有 \[ Ey = \beta_0 + \beta_1 x_1 + \dots + \beta_p x_p . \]
33.2 参数估计
未知的参数有回归系数\(\beta_0, \beta_1, \dots, \beta_p, \sigma^2\), 另外误差项也是未知的。
模型估计仍使用最小二乘法,得到系数估计 \(\hat\beta_0, \hat\beta_1, \dots, \hat\beta_p\) 及误差方差估计\(\hat\sigma^2\)。 把系数估计代入到模型中, 写出如下的估计的多元线性回归方程: \[ \hat y = \hat\beta_0 + \hat\beta_1 x_1 + \dots + \hat\beta_p x_p . \]
对第\(i\)组观测值,将自变量值代入估计的回归方程中得拟合值 \[ \hat y_i = \hat\beta_0 + \hat\beta_1 x_{i1} + \dots + \hat\beta_p x_{ip} . \] \(e_i = y_i - \hat y_i\)称为残差。
回归参数估计,用残差最小作为目标,令 \[ Q = \sum_{i=1}^n \left[ y_i - (\beta_0 + \beta_1 x_{i1} + \dots + \beta_p x_{ip}) \right]^2 \] 取使得\(Q\)达到最小的\((\beta_0, \beta_1, \dots, \beta_p)\)作为参数估计, 称为最小二乘估计,记为\((\hat\beta_0, \hat\beta_1, \dots, \hat\beta_p)\)。 称得到的最小值为SSE,\(\sigma^2\)的估计为 \[ \hat\sigma^2 = \frac{1}{n-p-1} \text{SSE} = \frac{1}{n-p-1} \sum_{i=1}^n e_i^2 . \]
33.3 R的多元回归程序
在R中用lm(y ~ x1 + x2 + x3, data=d)这样的程序来做多元回归,
数据集为d, 自变量为x1,x2,x3三列。
例33.1 考虑d.class数据集中体重对身高和年龄的回归。
##
## Call:
## lm(formula = weight ~ height + age, data = d.class)
##
## Residuals:
## Min 1Q Median 3Q Max
## -17.962 -6.010 -0.067 7.553 20.796
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -141.2238 33.3831 -4.230 0.000637 ***
## height 3.5970 0.9055 3.973 0.001093 **
## age 1.2784 3.1101 0.411 0.686492
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 11.51 on 16 degrees of freedom
## Multiple R-squared: 0.7729, Adjusted R-squared: 0.7445
## F-statistic: 27.23 on 2 and 16 DF, p-value: 7.074e-06得到的回归模型可以写成 \[ \widehat{\text{weight}} = -141.2 + 3.597 \times \text{height} + 1.278 \times \text{age} \] 其中身高的系数3.597表示, 如果两个学生年龄相同, 则身高增加1个单位(这里是英寸), 体重平均增加3.597个单位(这里是磅)。 注意在仅有身高作为自变量时, 系数为3.899。 年龄的系数1.278也类似解释, 在两个学生身高相同时, 如果一个学生年龄大1岁, 则此学生的体重平均多1.278个单位。
回归系数可以用ggstatsplot包图示如下:
## You can cite this package as:
## Patil, I. (2021). Visualizations with statistical details: The 'ggstatsplot' approach.
## Journal of Open Source Software, 6(61), 3167, doi:10.21105/joss.03167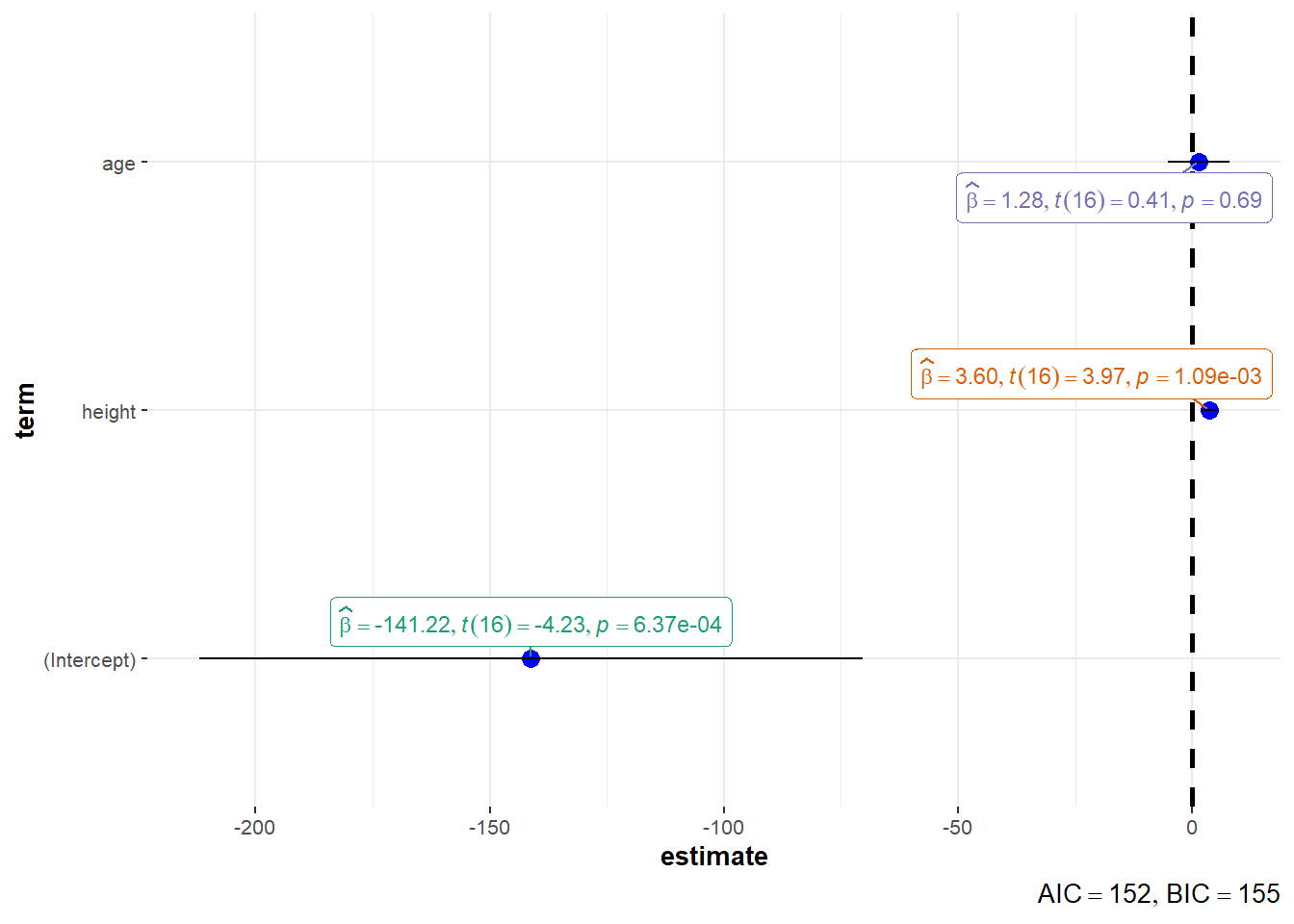
例33.2 Butler Trucking Company是一个短途货运公司。 老板想研究每个驾驶员每天的行驶时间的影响因素。 随机抽取了10名驾驶员一天的数据。考虑行驶里程(Miles)对行驶时间的影响。
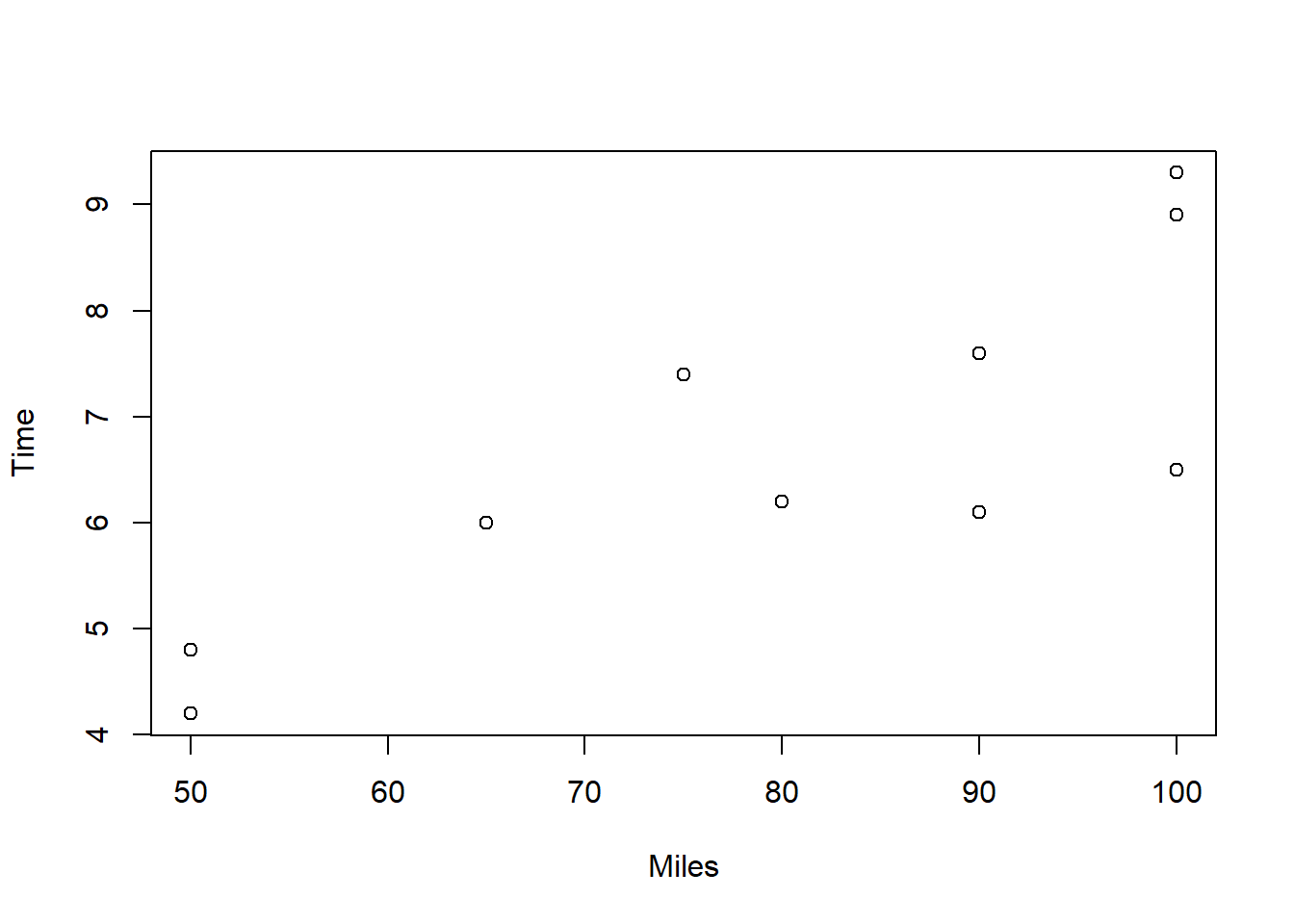
从散点图看,行驶里程与行驶时间有线性相关关系。 作一元线性回归:
##
## Call:
## lm(formula = Time ~ Miles, data = Butler)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.5565 -0.4913 0.1783 0.7120 1.2435
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 1.27391 1.40074 0.909 0.38969
## Miles 0.06783 0.01706 3.977 0.00408 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.002 on 8 degrees of freedom
## Multiple R-squared: 0.6641, Adjusted R-squared: 0.6221
## F-statistic: 15.81 on 1 and 8 DF, p-value: 0.00408这里Miles的系数解释为:行驶里程增加1英里,时间平均增加0.068小时。 老板想进一步改进对行驶时间的预测, 增加“派送地点数”(Deliveries)作为第二个自变量。 作多元回归:
##
## Call:
## lm(formula = Time ~ Miles + Deliveries, data = Butler)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.79875 -0.32477 0.06333 0.29739 0.91333
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -0.868701 0.951548 -0.913 0.391634
## Miles 0.061135 0.009888 6.182 0.000453 ***
## Deliveries 0.923425 0.221113 4.176 0.004157 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.5731 on 7 degrees of freedom
## Multiple R-squared: 0.9038, Adjusted R-squared: 0.8763
## F-statistic: 32.88 on 2 and 7 DF, p-value: 0.0002762这里Miles的系数从一元回归时的0.068改成了0.061, 解释为:在派送地点数相同的条件下,行驶里程每增加1英里, 行驶时间平均增加0.061小时。
Deliveries的系数解释为:在行驶里程相同的条件下, 派送地点数每增加一个地点,行驶时间平均增加0.92小时。
33.4 模型的检验
33.4.1 复相关系数平方
将总平方和分解为: \[ \text{SST} = \text{SSR} + \text{SSE}, \] 其中
- 总平方和 \[\text{SST} = \sum_{i=1}^n (y_i - \bar y)^2\];
- 回归平方和 \[\text{SSR} = \sum_{i=1}^n (\hat y_i - \bar y)^2\] 是能够用回归系数和自变量的变量解释的因变量变化;
- 残差平方和 \[\text{SSE} = \sum_{i=1}^n (y_i - \hat y_i)^2\] 是回归模型不能解释的因变量变化。
回归平方和越大,残差平方和越小,回归拟合越好。 定义复相关系数平方(判定系数) \[ R^2 = \frac{\text{SSR}}{\text{SST}} = 1 - \frac{\text{SSE}}{\text{SST}}, \] 则\(0 \leq R^2 \leq 1\)。 \(R^2\)越大,说明数据中的自变量拟合因变量值拟合越好。
但是,“拟合好”不是唯一标准。 仅考虑拟合好, 可能产生很复杂的仅对建模用数据有效但是对其它数据无效的模型, 这称为“过度拟合”。
定义调整的(修正的)复相关系数平方: \[ R^{*2} = 1 - (1-R^2)\frac{n-1}{n-p-1}, \] 克服了\(R^2\)的部分缺点。
在体重与身高、年龄的模型结果中, \(R^2=0.7729\), \(R^{*2}=0.7445\)。
33.4.2 残差标准误差
模型中\(\varepsilon\)的方差\(\sigma^2\)的估计为\(\hat\sigma_e^2\), \[ \hat\sigma^2 = \frac{1}{n-p-1}\text{SSE}, \]
\(\hat\sigma\)是随机误差的标准差\(\sigma\)的估计量, 称为“残差标准误差”(Residual standard error)。 这是残差\(e_i = y_i - \hat y_i\)的标准差的一个较粗略的近似估计。
在体重与身高、年龄的模型结果中, \(\hat\sigma=11.51\)。
33.4.3 线性关系检验
为了检验整个回归模型是否都无效,考虑假设检验: \[ H_0: \beta_1 = \dots = \beta_p = 0, \] 当\(H_0\)成立时模型退化成\(y=\beta_0 + \varepsilon\), \(y\)与\(x_1, x_2, \dots, x_p\)之间不再具有线性相关关系。
取统计量为 \[ F = \frac{\text{SSR}/p}{\text{SSE}/(n-p-1)}, \] 在模型前提条件都满足且\(H_0\)成立时\(F\)服从\(F(p, n-p-1)\)分布。 计算右侧\(p\)值,给出检验结论。
当检验显著时,各斜率项不全为零。 结果不显著时,当前回归模型不能使用。
在体重与身高、年龄的模型结果中, \(F=27.23\),p值为\(7.074\times 10^{-6}\), 在0.05水平下显著, 模型有意义。
33.4.4 线性关系检验的功效
pwr包可以计算上述F检验的功效, 对立假设是至少有一个斜率项不等于0, 计算功效时针对的效应大小定义为\(R^2\)的如下变换: \[ f_2 = \frac{R^2}{1 - R^2} . \]
体重对年龄、身高的回归获得的\(R^2 = 0.7729\)。 按此\(R^2\)对应的效应大小, 计算功效:
## Warning: package 'pwr' was built under R version 4.2.2R2 <- 0.7729
pwr.f2.test(
u = 2, # 斜率项个数
v = 19 - 2 - 1,
# 19为观测数,v为F统计量的分母自由度
f2 = R2 / (1 - R2), # 效应大小
sig.level = 0.01) # 检验水平##
## Multiple regression power calculation
##
## u = 2
## v = 16
## f2 = 3.403347
## sig.level = 0.01
## power = 0.99995功效为\(100\%\)。 这是因为\(R^2\)很大。
计算达到\(80\%\)功效所需样本量:
##
## Multiple regression power calculation
##
## u = 2
## v = 6.324025
## f2 = 3.403347
## sig.level = 0.01
## power = 0.8样本量为\(n = u + v + 1 = 9.32\)即只需要10个观测。
33.4.5 单个斜率项的显著性检验
为了检验某一个自变量\(X_j\)是否对因变量的解释有贡献 (在模型中已经包含了其它自变量的情况下),检验 \[ H_0: \beta_j = 0, \] 如果不拒绝\(H_0\), 相当于\(x_j\)可以不出现在模型中。 但是, 在多元线性回归中这不代表\(x_j\)与\(y\)之间没有线性相关, 可能是由于其它的自变量包含了\(x_j\)中的信息。
检验使用如下\(t\)统计量 \[ t = \frac{\hat\beta_j}{\text{SE}(\hat\beta_j)}, \] 在模型前提条件都满足且\(H_0\)成立时\(t\)服从\(t(n-p-1)\)分布。 给定检验水平\(\alpha\),计算双侧\(p\)值,做出检验结论。
对单个回归系数的检验,检验水平可取得略高,如0.10, 0.15。
在体重与身高、年龄的模型结果中, 身高的斜率项显著性p值为0.001, 在0.15水平下显著; 体重的斜率项显著性p值为0.686, 在0.15水平下不显著, 可考虑从模型中去掉体重变量。
33.5 回归自变量筛选
例33.3 考虑19个学生的体重与身高、年龄的回归模型。
在19个学生的体重与身高、年龄的线性回归模型结果中, 发现关于年龄的系数为零的检验p值为0.686, 不显著, 说明在模型中已经包含身高的情况下, 年龄不提供对体重的额外信息。 但是如果体重对年龄单独建模的话,年龄的影响还是显著的:
##
## Call:
## lm(formula = weight ~ age, data = d.class)
##
## Residuals:
## Min 1Q Median 3Q Max
## -23.349 -7.609 -5.260 7.945 42.847
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -50.493 33.290 -1.517 0.147706
## age 11.304 2.485 4.548 0.000285 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 15.74 on 17 degrees of freedom
## Multiple R-squared: 0.5489, Adjusted R-squared: 0.5224
## F-statistic: 20.69 on 1 and 17 DF, p-value: 0.0002848模型中不显著的自变量应该逐一剔除。可以用
step函数进行逐步回归变量选择,如:
## Start: AIC=94.93
## weight ~ height + age + sex
##
## Df Sum of Sq RSS AIC
## - age 1 113.76 1957.8 94.067
## <none> 1844.0 94.930
## - sex 1 276.09 2120.1 95.581
## - height 1 1020.61 2864.6 101.299
##
## Step: AIC=94.07
## weight ~ height + sex
##
## Df Sum of Sq RSS AIC
## - sex 1 184.7 2142.5 93.780
## <none> 1957.8 94.067
## - height 1 5696.8 7654.6 117.974
##
## Step: AIC=93.78
## weight ~ height
##
## Df Sum of Sq RSS AIC
## <none> 2142.5 93.78
## - height 1 7193.2 9335.7 119.75##
## Call:
## lm(formula = weight ~ height, data = d.class)
##
## Residuals:
## Min 1Q Median 3Q Max
## -17.6807 -6.0642 0.5115 9.2846 18.3698
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -143.0269 32.2746 -4.432 0.000366 ***
## height 3.8990 0.5161 7.555 7.89e-07 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 11.23 on 17 degrees of freedom
## Multiple R-squared: 0.7705, Adjusted R-squared: 0.757
## F-statistic: 57.08 on 1 and 17 DF, p-value: 7.887e-07例33.4 餐馆营业额的回归建模分析。
考虑另一个例子数据。 在数据框Resturant中包含25个餐馆的一些信息,包括:
- \(y\), 营业额, 日均营业额(万元)
- \(x_1\), 居民数, 周边居民人数(万人)
- \(x_2\), 人均餐费, 用餐平均支出(元/人)
- \(x_3\), 月收入, 周边居民月平均收入(元)
- \(x_4\), 餐馆数, 周边餐馆数(个)
- \(x_5\), 距离, 距市中心距离(km)
对营业额进行回归建模研究。 变量间的相关系数图:
corrgram::corrgram(
Resturant, order=TRUE,
lower.panel=corrgram::panel.shade,
upper.panel = corrgram::panel.pie,
text.panel = corrgram::panel.txt)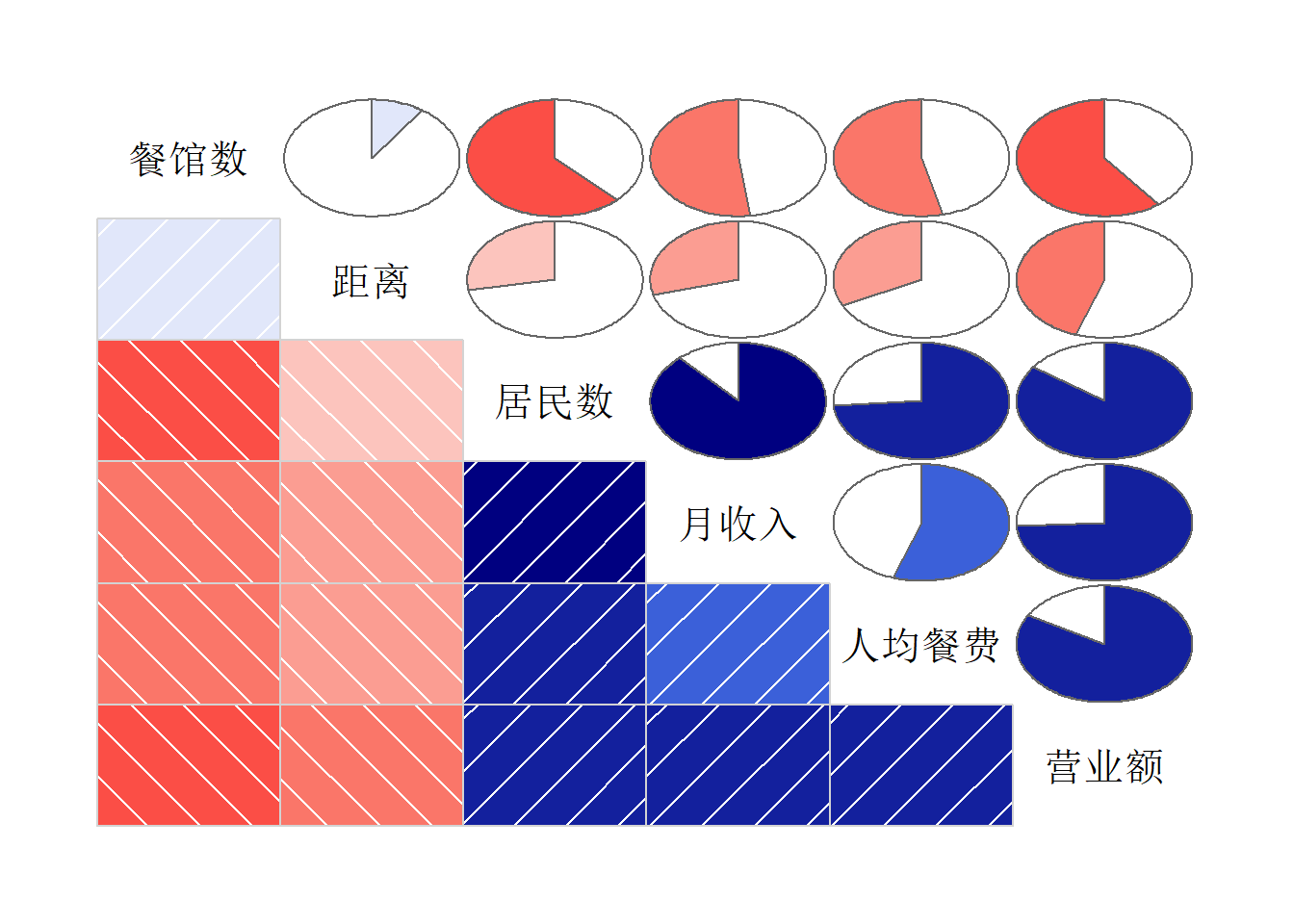
##
## Call:
## lm(formula = 营业额 ~ 居民数 + 人均餐费 + 月收入 +
## 餐馆数 + 距离, data = Resturant)
##
## Residuals:
## Min 1Q Median 3Q Max
## -16.7204 -6.0600 0.7152 3.2144 21.4805
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 4.2604768 10.4679833 0.407 0.68856
## 居民数 0.1273254 0.0959790 1.327 0.20037
## 人均餐费 0.1605660 0.0556834 2.884 0.00952 **
## 月收入 0.0007636 0.0013556 0.563 0.57982
## 餐馆数 -0.3331990 0.3986248 -0.836 0.41362
## 距离 -0.5746462 0.3087506 -1.861 0.07826 .
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 10.65 on 19 degrees of freedom
## Multiple R-squared: 0.8518, Adjusted R-squared: 0.8128
## F-statistic: 21.84 on 5 and 19 DF, p-value: 2.835e-07在0.15水平上只有人均餐费和到市中心距离是显著的。 进行逐步回归筛选:
## Start: AIC=123.39
## 营业额 ~ 居民数 + 人均餐费 + 月收入 + 餐馆数 +
## 距离
##
## Df Sum of Sq RSS AIC
## - 月收入 1 35.96 2189.0 121.81
## - 餐馆数 1 79.17 2232.2 122.30
## <none> 2153.0 123.39
## - 居民数 1 199.42 2352.4 123.61
## - 距离 1 392.54 2545.6 125.58
## - 人均餐费 1 942.22 3095.2 130.47
##
## Step: AIC=121.81
## 营业额 ~ 居民数 + 人均餐费 + 餐馆数 + 距离
##
## Df Sum of Sq RSS AIC
## - 餐馆数 1 78.22 2267.2 120.69
## <none> 2189.0 121.81
## - 距离 1 445.69 2634.7 124.44
## - 人均餐费 1 925.88 3114.9 128.63
## - 居民数 1 1133.27 3322.3 130.24
##
## Step: AIC=120.69
## 营业额 ~ 居民数 + 人均餐费 + 距离
##
## Df Sum of Sq RSS AIC
## <none> 2267.2 120.69
## - 距离 1 404.28 2671.5 122.79
## - 人均餐费 1 1050.90 3318.1 128.21
## - 居民数 1 1661.83 3929.0 132.43##
## Call:
## lm(formula = 营业额 ~ 居民数 + 人均餐费 + 距离, data = Resturant)
##
## Residuals:
## Min 1Q Median 3Q Max
## -14.027 -5.361 -1.560 2.304 23.001
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -1.68928 6.25242 -0.270 0.78966
## 居民数 0.19022 0.04848 3.923 0.00078 ***
## 人均餐费 0.15763 0.05052 3.120 0.00518 **
## 距离 -0.56979 0.29445 -1.935 0.06656 .
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 10.39 on 21 degrees of freedom
## Multiple R-squared: 0.8439, Adjusted R-squared: 0.8216
## F-statistic: 37.85 on 3 and 21 DF, p-value: 1.187e-08最后进保留了周边居民人数、人均餐费、到市中心距离三个自变量, 删去了周边居民月收入和周边餐馆数两个自变量。
33.6 过度拟合示例
\(R^2\)代表了模型对数据的拟合程度, 模型中加入的自变量越多, \(R^2\)越大。 是不是模型中的自变量越多越好? 自变量过多时可能会发生“过度拟合”, 这时用来建模的数据都拟合误差很小, 但是模型很难有合理解释, 对新的数据的预测效果很差甚至于完全错误。 下面给出模拟数据例子。
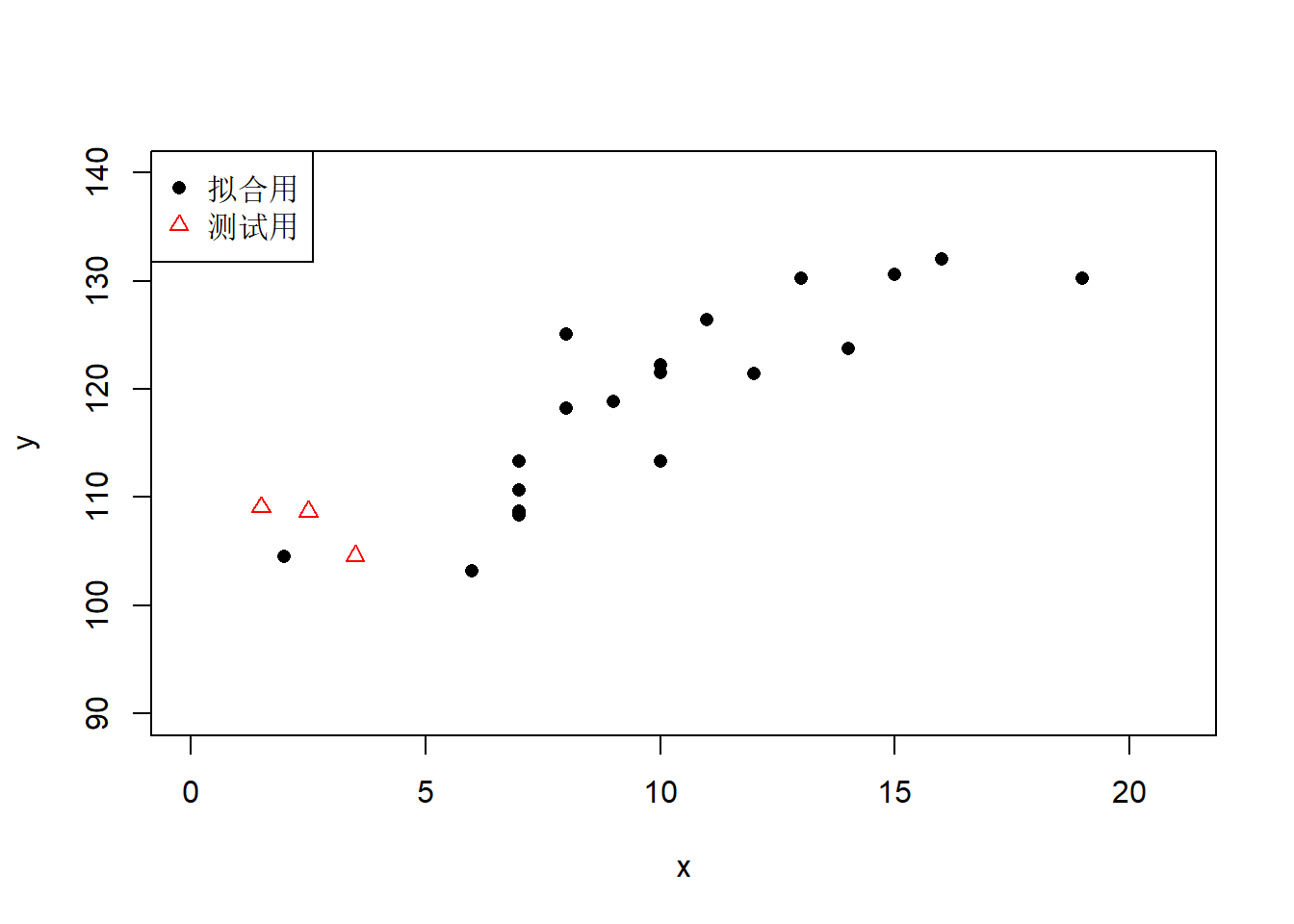
作线性回归:
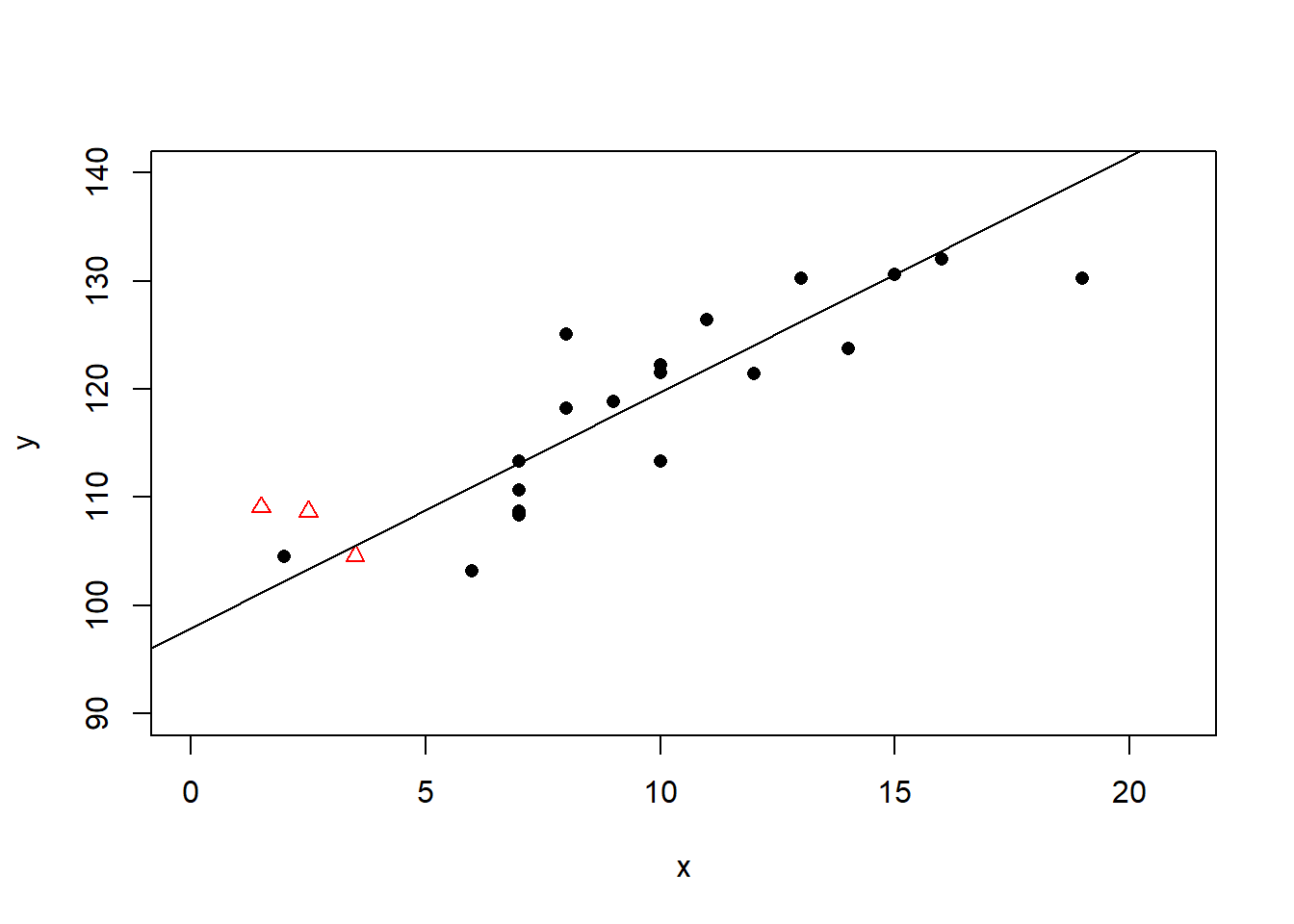
线性回归的\(R^2 = 0.71\)。
作二次多项式回归:
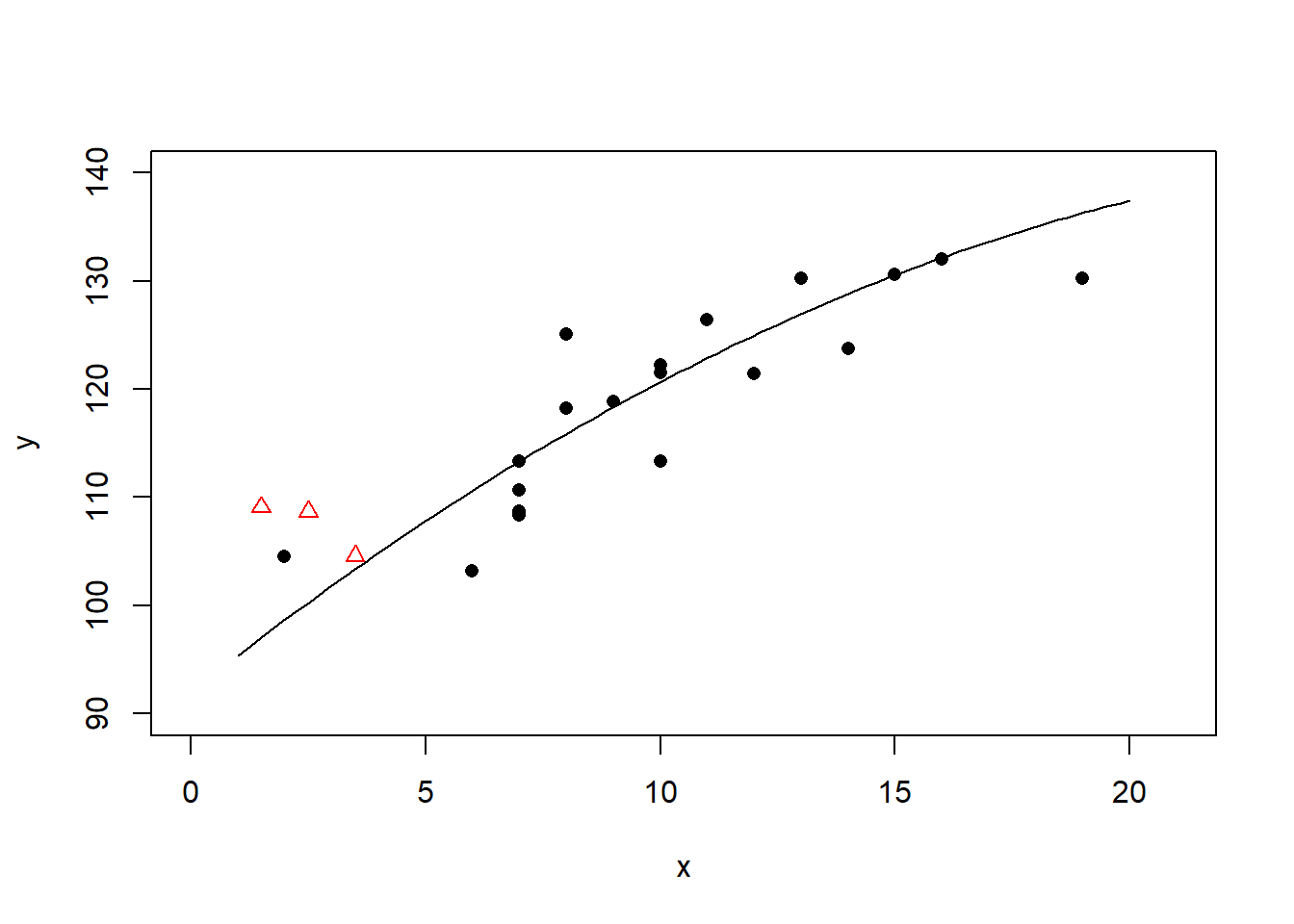
二次多项式回归的\(R^2 = 0.72\)。 这个回归结果出现了多重共线性问题, 也已经过度拟合。
作三次多项式回归:
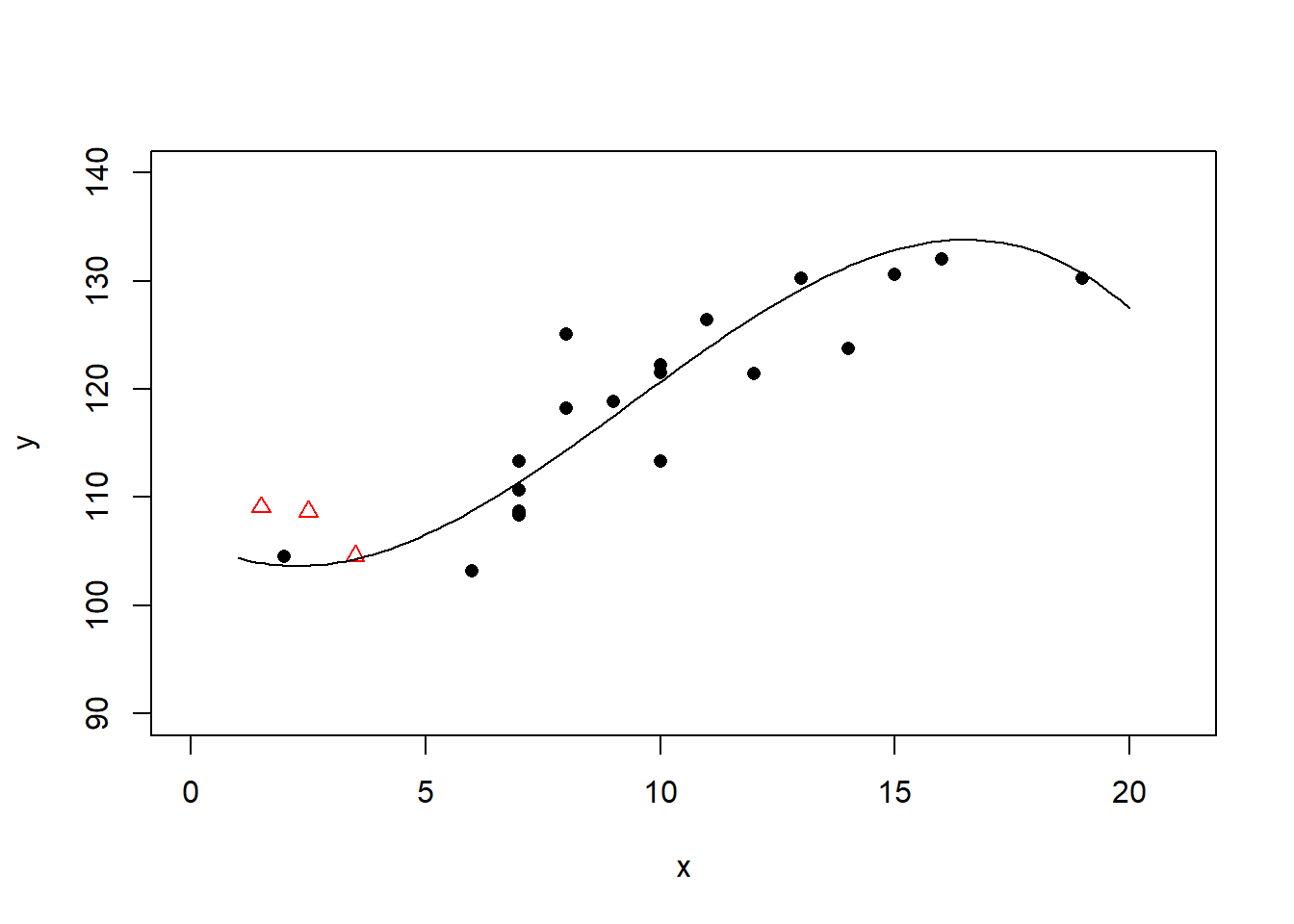
三次多项式回归的\(R^2 = 0.77\)。 有多重共线性问题, 也已经过度拟合。
作四次多项式回归:
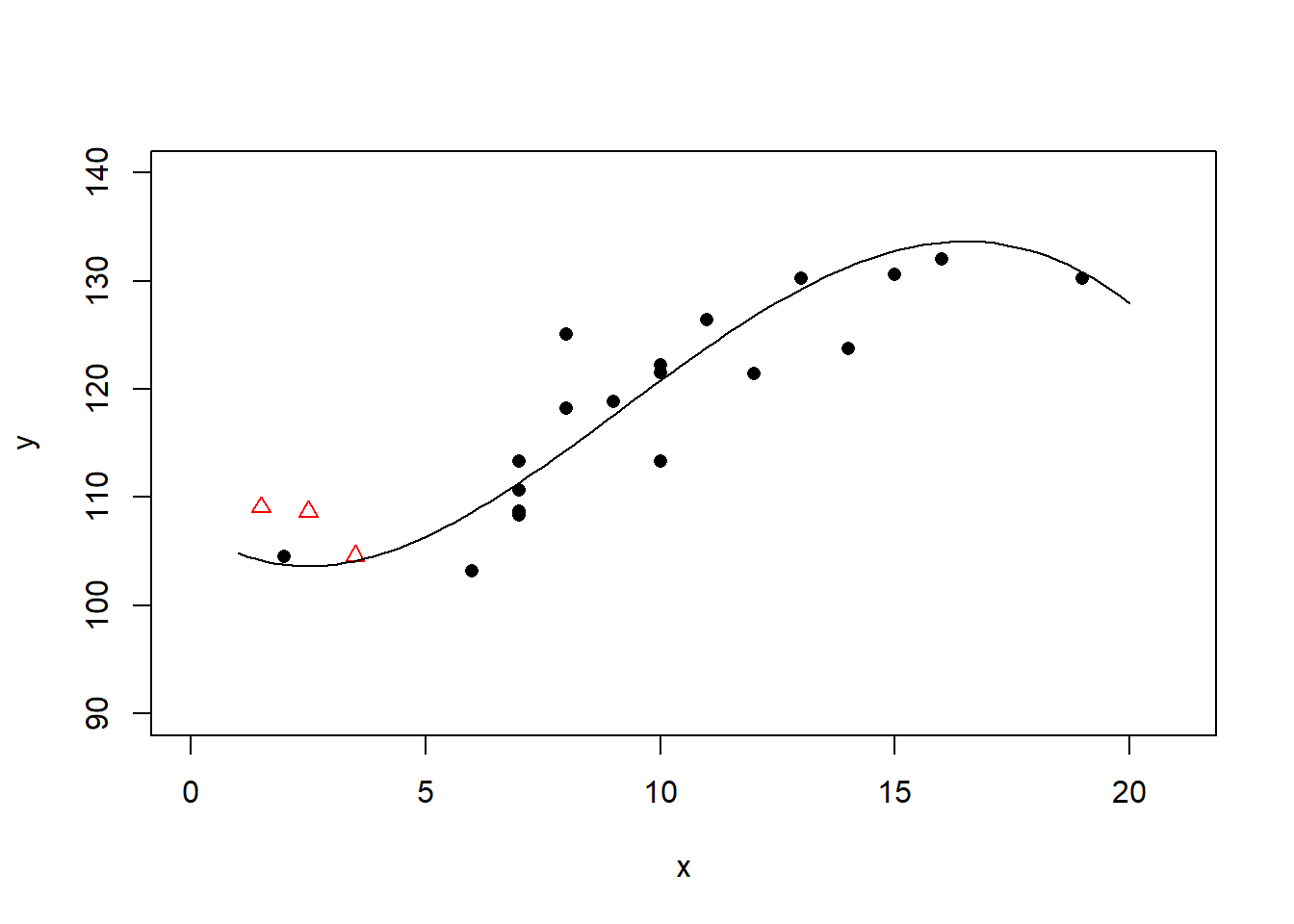
四次多项式回归的\(R^2 = 0.77\), 过度拟合。
作五次多项式回归:
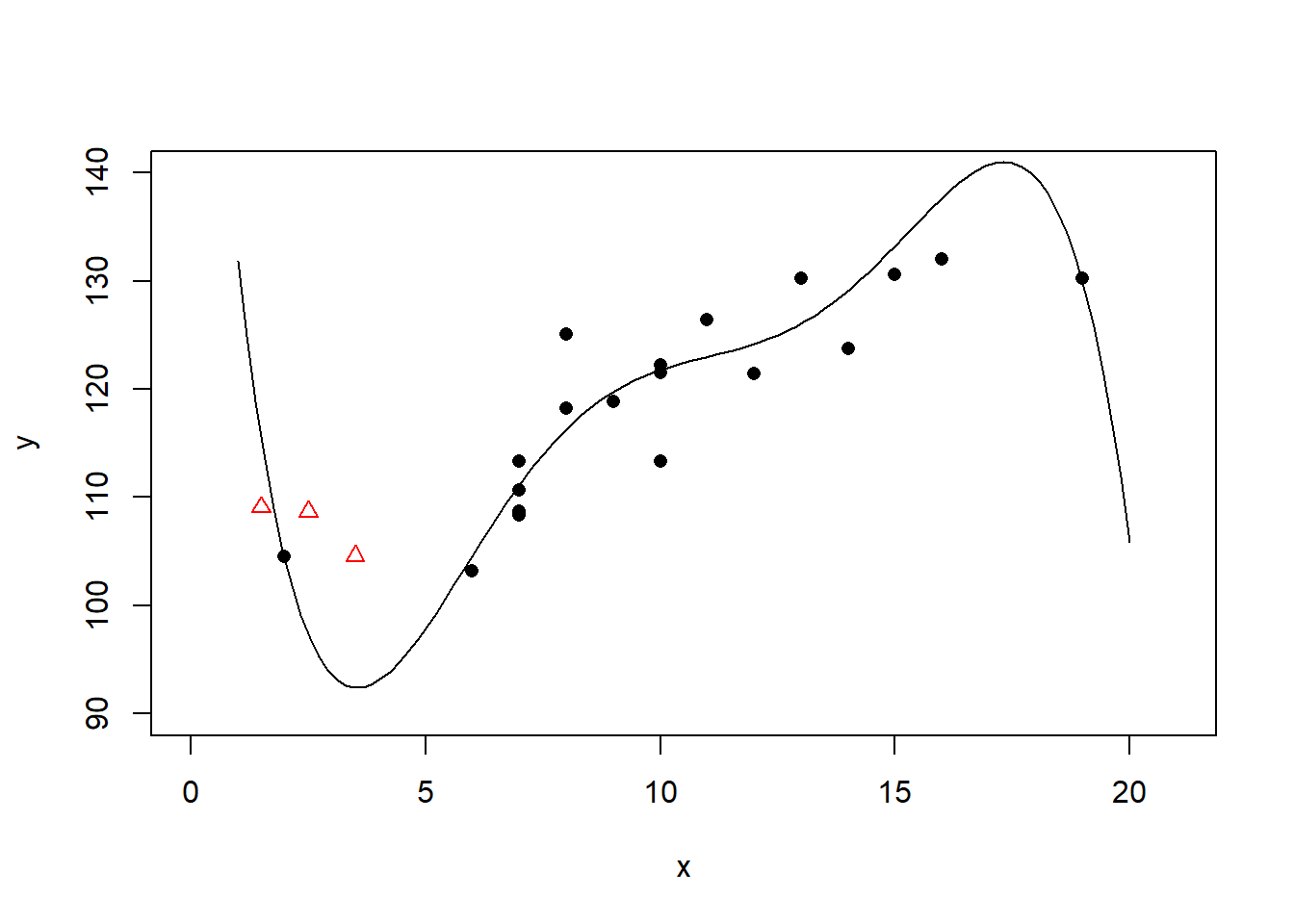
五次多项式回归的\(R^2 = 0.80\), 已经明显过度拟合。 这时可以看出对三个测试点(图中三角形点)中最左边一个的预测效果极差。
六次多项式回归:
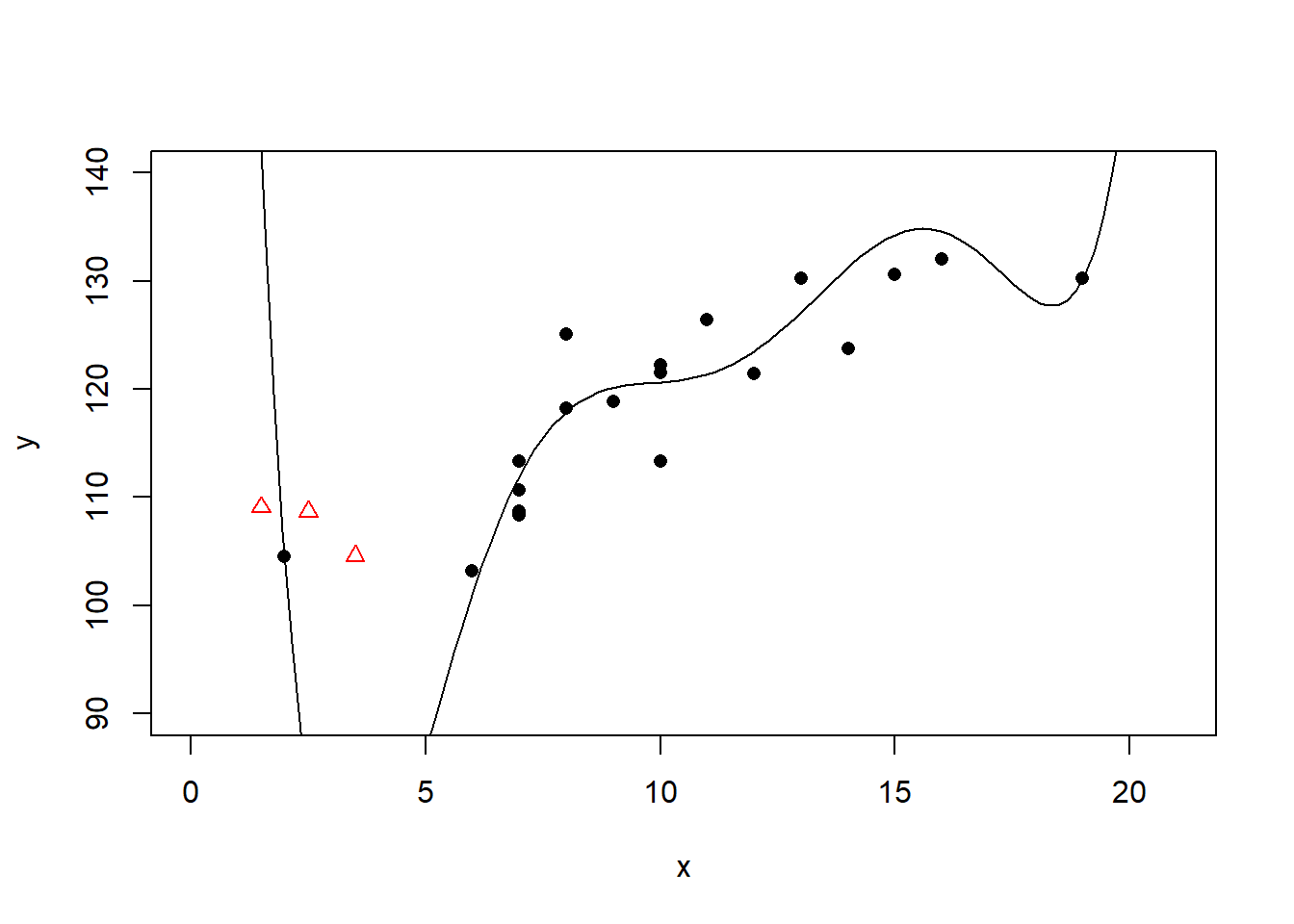
六次多项式回归的\(R^2 = 0.82\), 已经明显过度拟合。 对三个测试点(图中三角形点)中最左边一个的预测效果极差。
注:在lm()的公式中,
用I(x^2)加入自变量x的平方项,
高次项类似。
这样加入高次项可能会造成多重共线性问题,
可以使用正交多项式poly(x, degree)函数。
注:过度拟合在机器学习(统计学习)中是一个重要概念。 机器学习算法往往有大量的模型参数, 根据某种损失函数对这些模型参数进行优化很容易造成过度拟合, 机器学习中有一系列避免过度拟合的方法, 比如, 减少参数个数或者参数自由度(称为正则化), 在迭代优化时使用较小的步长、较早结束迭代, 等等。
33.7 残差诊断
先复习一些回归理论。 将模型写成矩阵形式 \[ {\boldsymbol Y} = {\boldsymbol X}\boldsymbol\beta + \boldsymbol\varepsilon , \] \({\boldsymbol Y}\)为\(n \times 1\)向量, \({\boldsymbol X}\)为\(n \times p\)矩阵(\(n>p\)), 一般第一列元素全是1, 代表截距项。 \(\boldsymbol\beta\)为\(p \times 1\)未知参数向量; \(\boldsymbol\varepsilon\)为\(n \times 1\)随机误差向量, \(\varepsilon\)的元素独立且方差为相等的\(\sigma^2\)(未知)。
假设矩阵\(\boldsymbol X\)列满秩,系数的估计为 \[\begin{aligned} \hat{\boldsymbol\beta} = \left( {{\boldsymbol X^T \boldsymbol X}} \right)^{-1} {\boldsymbol X^T \boldsymbol Y}, \end{aligned}\]
拟合值(或称预报值)向量为 \[\begin{aligned} \hat{\boldsymbol Y} = {\boldsymbol X} \left( {{\boldsymbol X^T \boldsymbol X}} \right)^{-1} {\boldsymbol X^T \boldsymbol Y} = {\boldsymbol H \boldsymbol Y}, \end{aligned}\] 其中\({\boldsymbol H} = {\boldsymbol X}\left( {{\boldsymbol X^T X}} \right)^{-1} {\boldsymbol X^T}\)是\(R^n\)空间的向量向\({\boldsymbol X}\) 的列张成的线性空间\(\mu({\boldsymbol X})\) 投影的投影算子矩阵, 叫做帽子矩阵。 设\(\boldsymbol H = \left( h_{ij} \right)_{n\times n}\)。
拟合残差向量为 \[\begin{aligned} \boldsymbol e = {\boldsymbol Y} - \hat{\boldsymbol Y} = ({\boldsymbol I} - {\boldsymbol H}){\boldsymbol Y} , \end{aligned}\] 满足 \[\begin{aligned} E \boldsymbol e =& \boldsymbol 0, \\ \text{Var}(\boldsymbol e) =& \sigma^2(I - H). \end{aligned}\]
残差平方和为 \[\begin{aligned} \mbox{ESS} = \boldsymbol e^T \boldsymbol e = \sum\limits_{i = 1}^n {\left( {Y_i - \hat Y_i } \right)^2 } . \end{aligned}\]
误差项方差的估计 (要求设计阵\({\boldsymbol X}\)满秩)为均方误差(MSE) \[\begin{aligned} \hat\sigma^2 = \mbox{MSE} = \frac{1}{{n - p}} \mbox{ESS} \end{aligned}\] (其中\(p\)在有截距项时是自变量个数加1)。
在线性模型的假设下, 若设计阵\({\boldsymbol X}\)满秩, \(\hat\beta\)和\(\hat\sigma^2\) 分别是\(\beta\)和\(\sigma^2\)的无偏估计。
系数估计的方差阵 \[ \text{Var}(\hat{\boldsymbol\beta}) = \sigma^2 \left( {\boldsymbol X}^T {\boldsymbol X} \right)^{-1} . \]
回归残差及其方差为 \[\begin{aligned} e_i =& y_i - \hat y_i, \quad i=1,2,\dots,n , \\ \text{Var}(e_i) =& \sigma^2 (1 - h_{ii}) \quad(h_{ii}\text{是}H\text{的主对角线元素}) . \end{aligned}\]
若lmres是R中lm()的回归结果,
用residuals(lmres)可以求残差。
把\(e_i\)除以其标准差估计, 称为标准化残差,或内部学生化残差: \[\begin{aligned} r_i = \frac{e_i}{s \sqrt{1 - h_{ii}}}, \quad i=1,2,\dots,n \end{aligned}\] 其中\(s = \hat\sigma\)。 \(r_i\)渐近服从正态分布。
若lmres是R中lm()的回归结果,
用rstandard(lmres)可以求标准化残差。
如果计算\(y_i\)的预测值时, 删除第\(i\)个观测后建立回归模型得到\(\sigma^2\) 的估计\(s_{(i)}^2\), 则外部学生化残差为 \[\begin{aligned} t_i = \frac{e_i}{s_{(i)} \sqrt{1 - h_{ii}}} \end{aligned}\] \(t_i\)近似服从\(t(n-p-1)\)分布 (有截距项时\(p\)等于自变量个数加1)。 其中\(s_{(i)}\)有简单公式: \[\begin{aligned} s_{(i)}^2 = \frac{n-p-r_i^2}{n-p-1} \hat\sigma^2 \end{aligned}\]
若lmres是R中lm()的回归结果,
用rstudent(lmres)可以求外部学生化残差。
在R中,
与一元回归的诊断类似。
用plot()作4个残差诊断图。
可以用which=1指定仅作第一幅图。
如餐馆营业额例子的残差诊断:
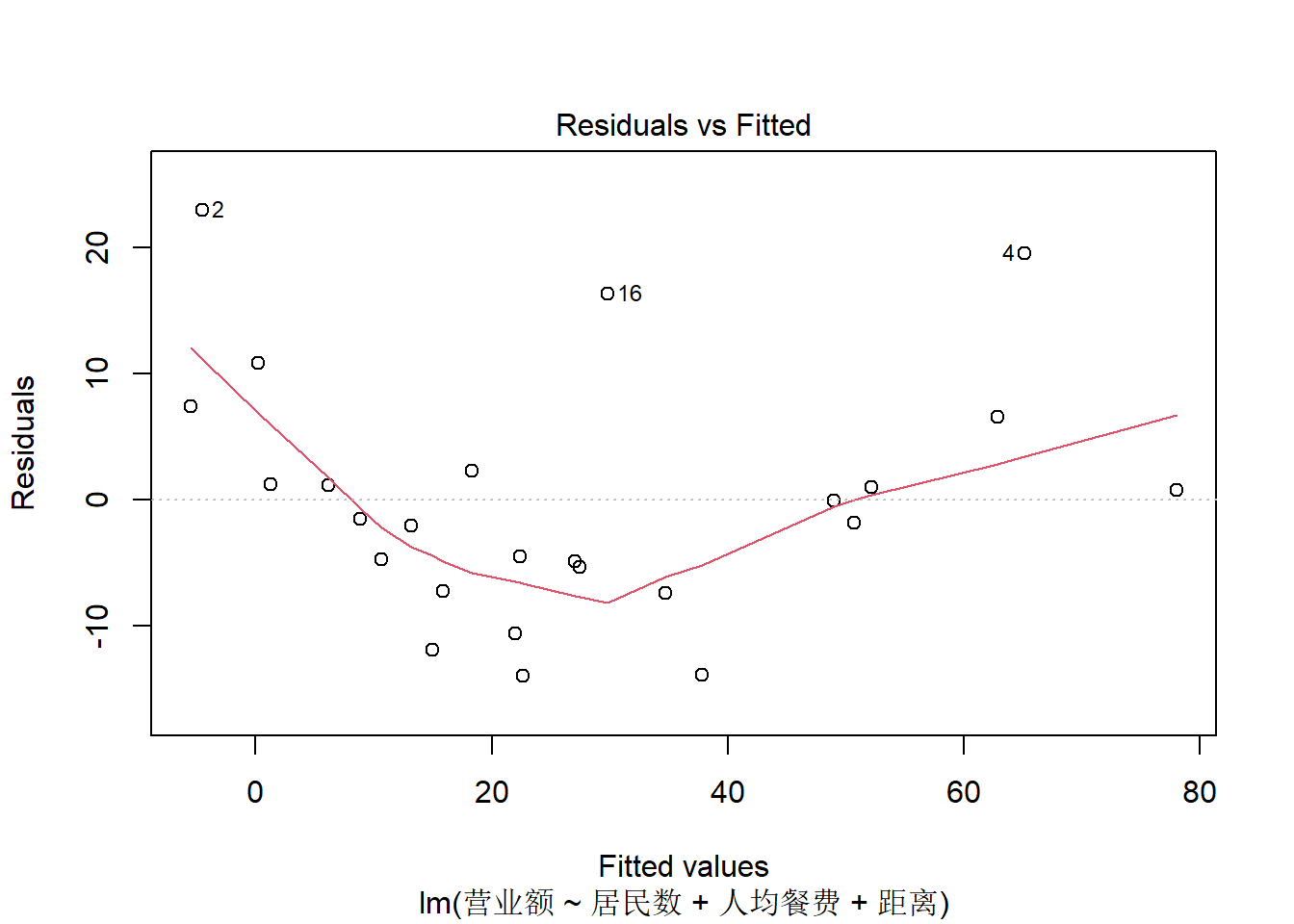
上图是残差对拟合值的散点图, 可以查看有无非线性。 有轻微的非线性关系。
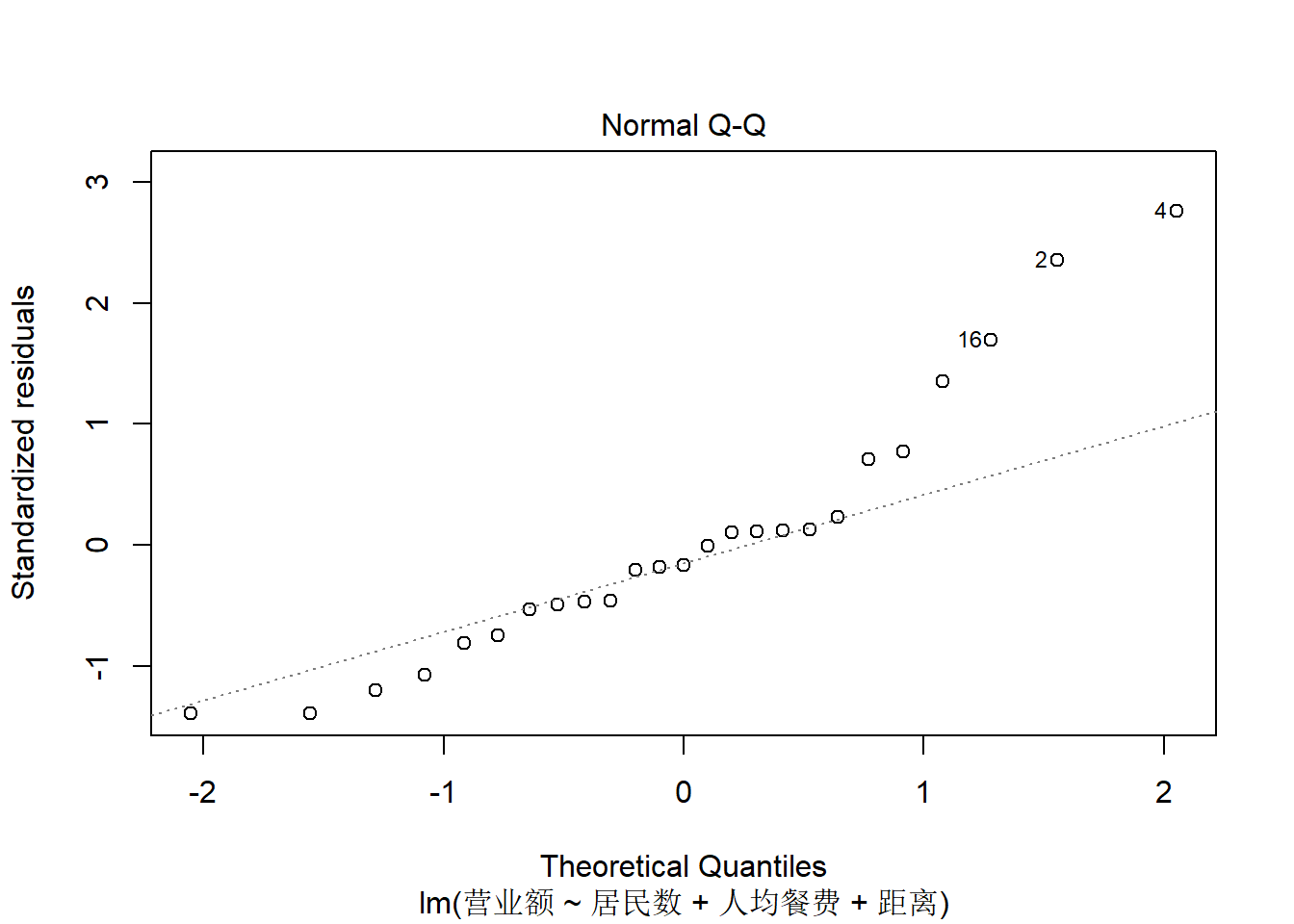
上图是残差的正态QQ图, 查看残差是否正态分布。 残差分布略有右偏,不算太严重。
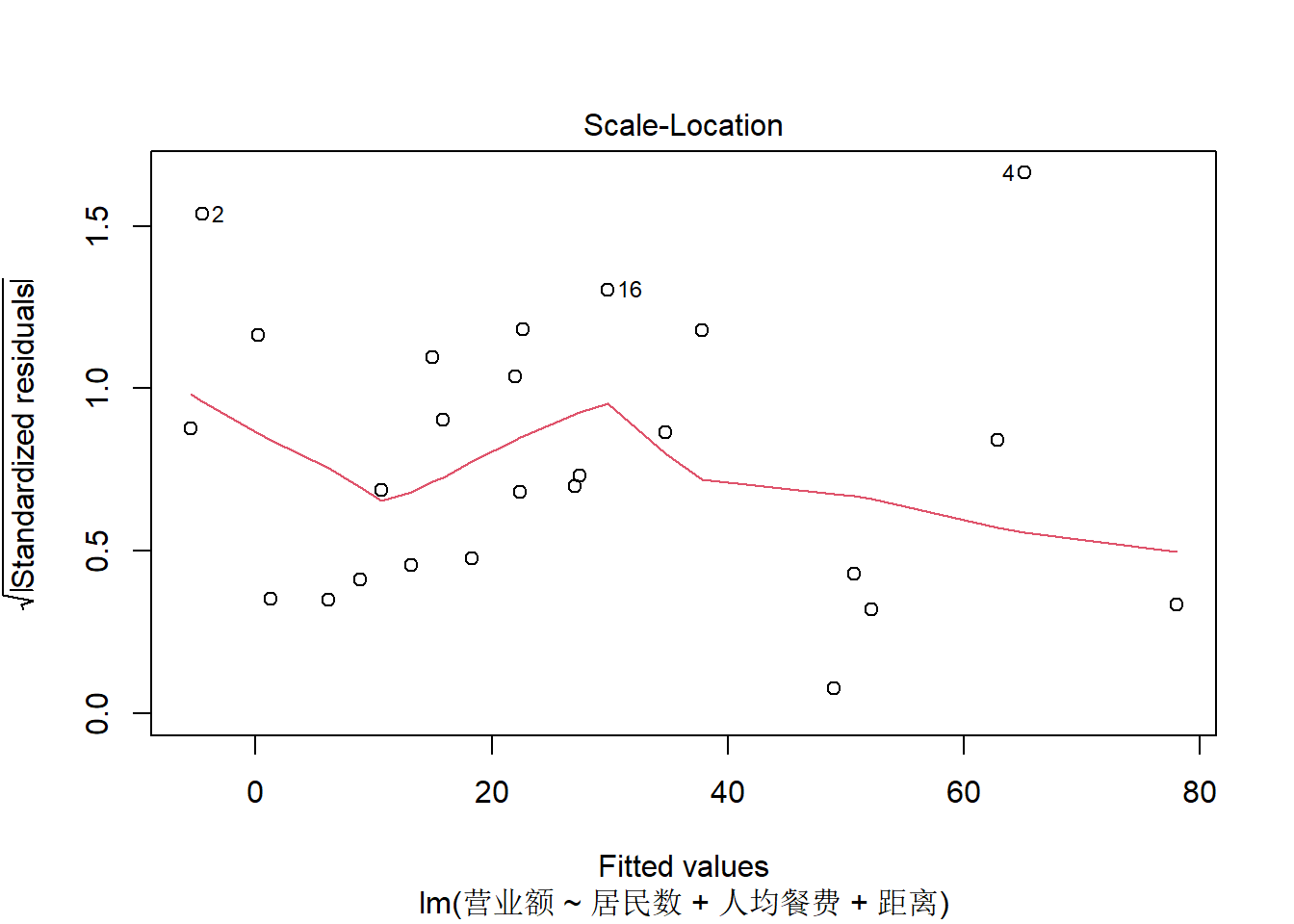 上图是标准化残差绝对值平方根对拟合值的散点图,
可以查看是否有异方差。
没有明显的异方差。
上图是标准化残差绝对值平方根对拟合值的散点图,
可以查看是否有异方差。
没有明显的异方差。

上图用来查看强影响点, 4号观测是一个强影响点。
货运公司例子的多元回归的残差诊断:
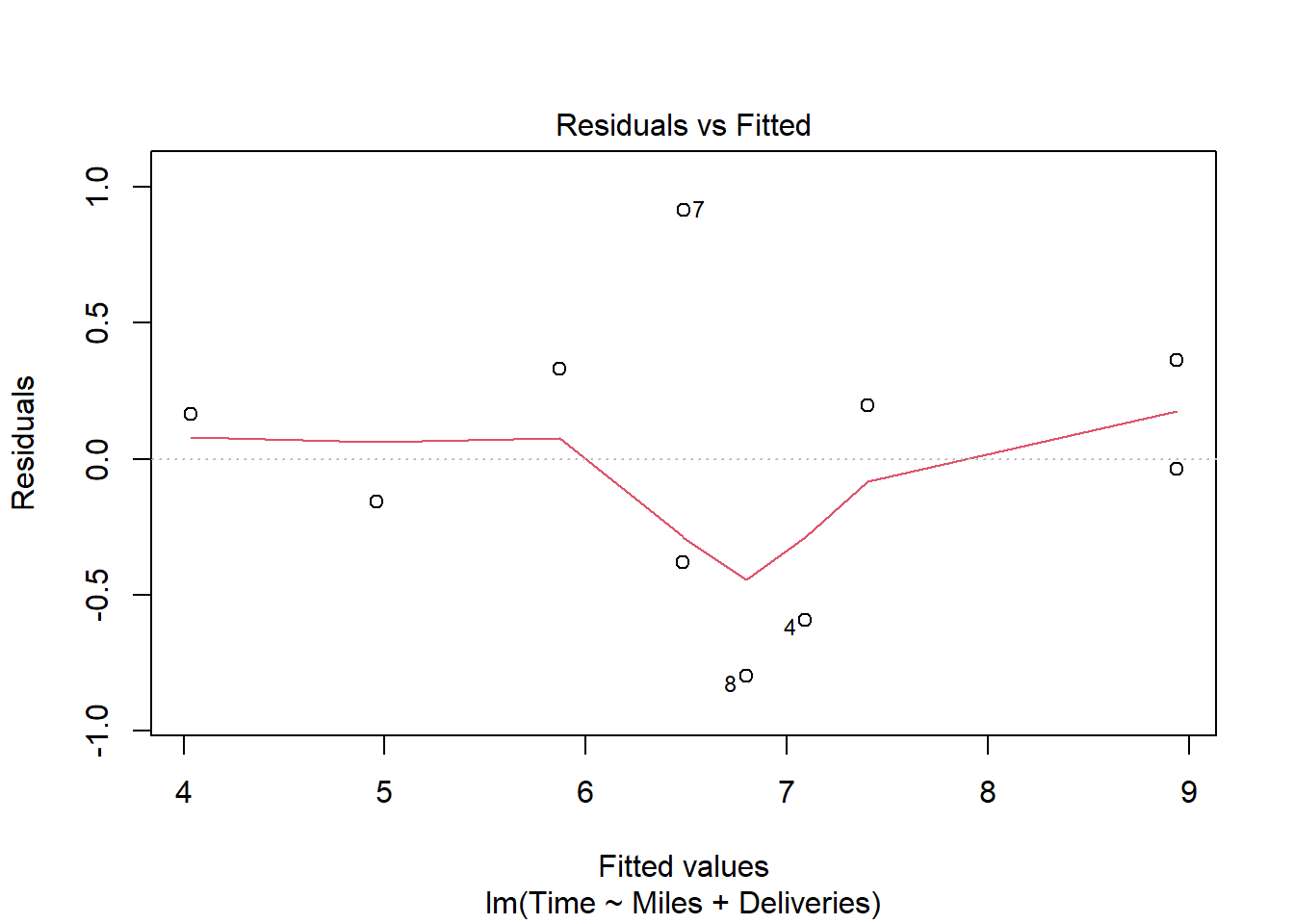
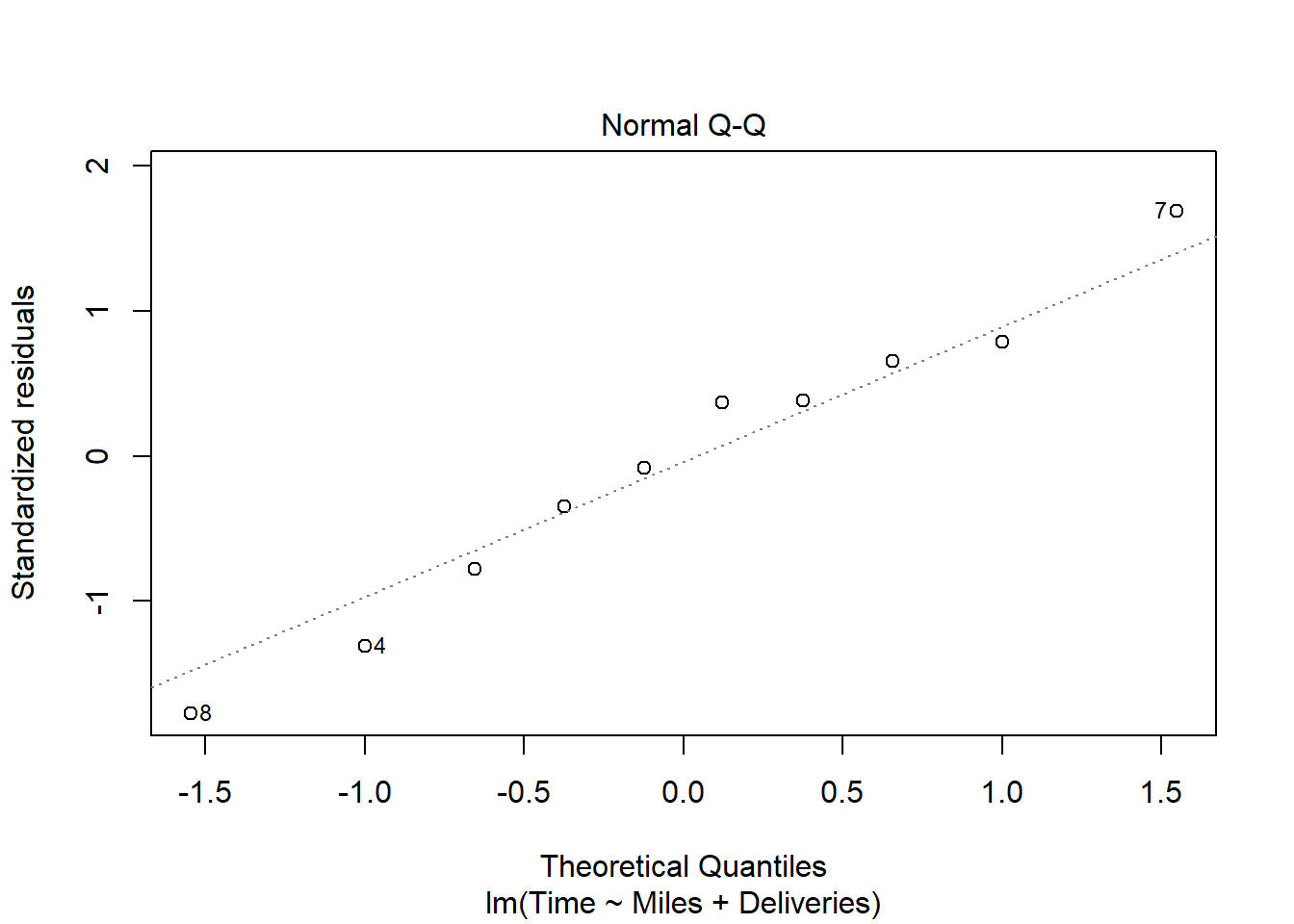
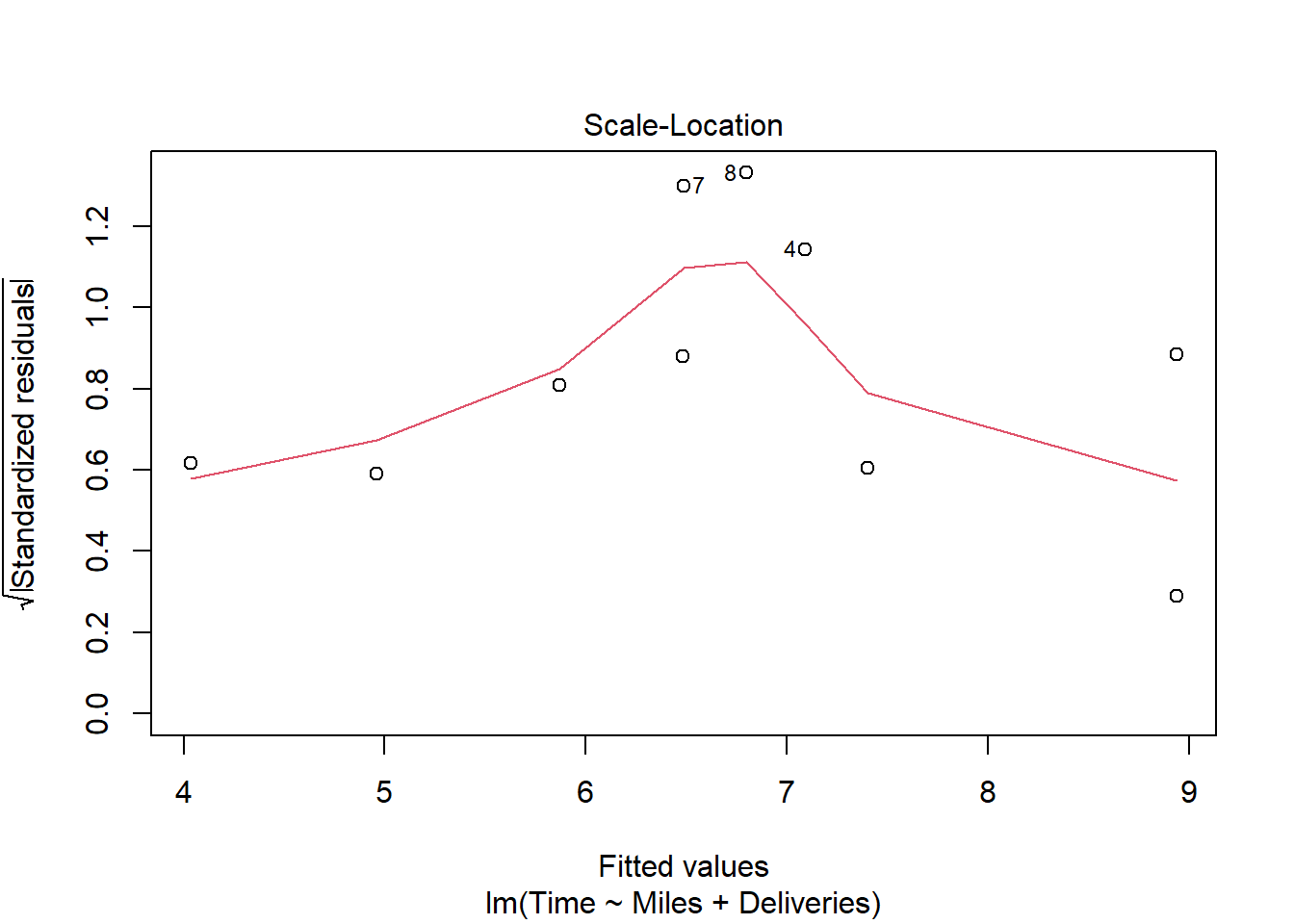
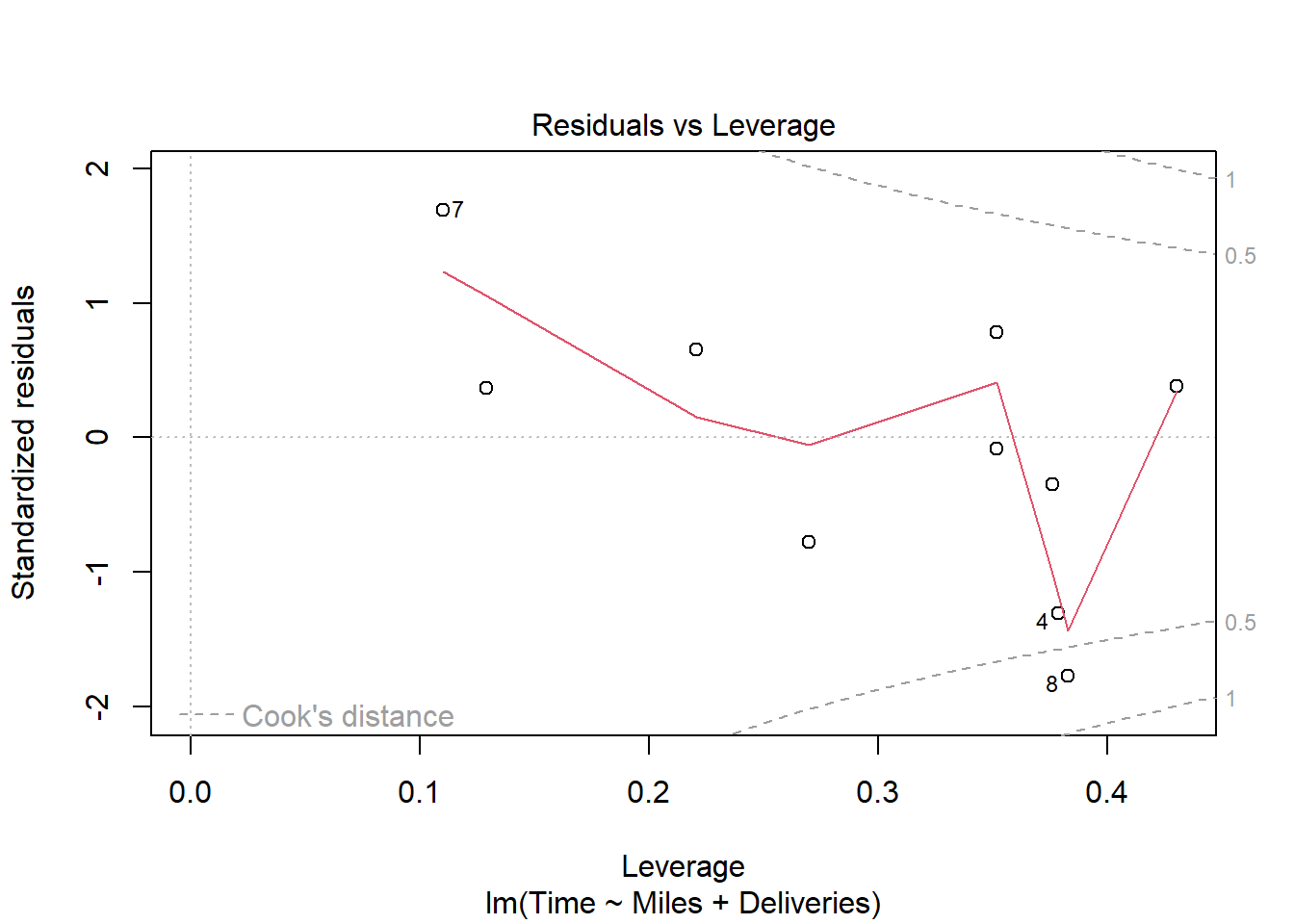
有一定的异方差倾向,但是数据量不大就不做处理。
33.8 多重共线性
狭义的多重共线性(multicollinearity): 自变量的数据存在线性组合近似地等于零, 使得解线性方程组求解回归系数时结果不稳定, 回归结果很差。
广义的多重共线性: 自变量之间存在较强的相关性, 这样自变量是联动的, 互相之间有替代作用。 甚至于斜率项的正负号都因为这种替代作用而可能是错误的方向。
例如, 餐馆营业额例子中, F检验显著, 5个自变量如果用在一元回归中斜率项都显著, 但是在多元回归中, 在0.15水平下仅有人均餐费和到市中心的距离的系数是显著的, 月收入、餐馆数、居民数的系数不显著。
但是实际上,单独使用这三个自变量作一元线性回归, 结果都是显著的,比如单独以月收入为自变量进行一元回归:
##
## Call:
## lm(formula = 营业额 ~ 月收入, data = Resturant)
##
## Residuals:
## Min 1Q Median 3Q Max
## -32.151 -10.725 -0.696 6.033 47.819
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 0.484580 5.955478 0.081 0.936
## 月收入 0.004995 0.000944 5.291 2.27e-05 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 16.88 on 23 degrees of freedom
## Multiple R-squared: 0.549, Adjusted R-squared: 0.5294
## F-statistic: 27.99 on 1 and 23 DF, p-value: 2.273e-05如何识别多重共线性?
- 如果两个自变量之间的相关系数显著地不等于零, 这两个自变量就有广义的共线性。
- 如果线性关系的F检验显著但是单个回归系数都不显著, 可能是由于多重共线性。
- 如果有单个回归系数显著但是\(F\)检验不显著, 可能是由于多重共线性。
- 如果某些回归系数的正负号与通常的认识相反, 可能是由于多重共线性。
将第\(i\)个自变量\(x_i\)作为因变量, 用其它的\(p-1\)个自变量作为自变量作多元线性回归, 得到一个复相关系数平方\(R_i^2\), 这个\(R_i^2\)接近于1时\(x_i\)与其他自变量之间存在多重共线性。 令\(x_i\)的容忍度(tolerance)等于\(1-R_i^2\), 容忍度接近于0时存在多重共线性。
容忍度小于0.1时多重共线性为严重程度。
称容忍度的倒数为方差膨胀因子(VIF), VIF大于10或者大于5作为严重的多重共线性。
为了计算VIF, 首先把矩阵\(X^T X\)看成一个协方差阵, 把它转换为相关系数阵设为\(M\), 则\(M^{-1}\)的各主对角线元素就是各个VIF。
car包的vif()函数计算方差膨胀因子。
如:
## 居民数 人均餐费 月收入 餐馆数 距离
## 8.233159 2.629940 5.184365 1.702361 1.174053可以认为变量“居民数”和“月收入”有共线问题。
做共线诊断还可以用条件数(Conditional Index): 这是一个正数,用来衡量\((X^T X)^{-1}\)的稳定性, 定义为\(X^T X\)的最大特征值与最小特征值之比。 条件数在0—100之间时认为无共线性, 在100—1000之间时认为自变量之间有中等或较强共线性, 在1000以上认为自变量之间有强共线性。
解决多重共线性问题, 最简单的方法是回归自变量选择, 剔除掉有严重共线性的自变量, 这些自变量的信息可以由其他变量代替。 还可以对自变量作变换,如用主成分分析降维。 可以用收缩方法如岭回归、lasso回归等。
33.9 强影响点分析
强影响点是删去以后严重改变参数估计值的观测。 包括自变量取值离群和因变量拟合离群的点。
杠杆(leverage)指帽子矩阵的对角线元素\(h_{ii}\), \[\begin{aligned} \frac{1}{n} \leq h_{ii} \leq \frac{1}{d_i} \end{aligned}\] 其中\(d_i\)是第\(i\)个观测的重复观测次数。 某观测杠杆值高说明该观测自变量有异常值。 杠杆值大于\(2p/n\)的观测需要仔细考察 (有截距项时\(p\)等于自变量个数加1)。
若lmres是R中lm()的回归结果,
用hatvalues(lmres)可以求杠杆值。
考察外学生化残差\(t_i\), 绝对值超过2的观测拟合误差大, 在\(y\)方向离群,需要关注。
若lmres是R中lm()的回归结果,
用rstudent(lmres)可以求外学生化残差。
Cook距离统计量
\[\begin{aligned}
D_i = \frac{1}{p} r_i^2 \frac{h_{ii}}{1 - h_{ii}}
\end{aligned}\]
用来度量估计模型时是否使用第\(i\)个观测对回归系数\(\boldsymbol{\beta}\)的估计的影响。
超过\(\frac{4}{n}\)的值需要注意。
若lmres是R中lm()的回归结果,
用cooks.distance(lmres)可以求Cook距离。
R中的强影响点诊断函数还有
dfbetas(), dffits(),
covratio()。
偏杠杆值衡量每个自变量(包括截距项)对杠杆的贡献。 把第\(j\)个自变量关于其它自变量回归得到残差, 第\(i\)个残差的平方占总残差平方和的比例为第\(j\)自变量在第\(i\)观测处的偏杠杆值。 偏杠杆值影响自变量选择时对该变量的选择。
33.10 协方差分析
33.10.1 哑变量
回归分析的因变量是连续型的,服从正态分布。 回归分析的自变量是数值型的,可以连续取值也可以离散取值。 但是,如果自变量是类别变量, 用简单的1,2,3编码并不能正确地表现不同类别的作用。 可以将类别变量转换成一个或者多个取0、1值的变量, 称为哑变量(dummy variables)或虚拟变量。 如果模型中既有连续型自变量又有分类自变量, 称这样的模型为协方差分析模型。
33.10.2 二值哑变量与平行线模型
如果\(f\)是一个二值分类变量,将其中一个类编码为1, 另一个类编码为零。 例如,\(f=1\)表示处理组,\(f=0\)表示对照组。 这样编码后二值分类变量可以直接用在回归模型中。
例如
\[
Ey = \beta_0 + \beta_1 x + \beta_2 f
\]
相当于
\[\begin{aligned}
Ey = \begin{cases}
\beta_0 + \beta_1 x, & \text{对照组} \\
(\beta_0 + \beta_2) + \beta_1 x, & \text{处理组} .
\end{cases}
\end{aligned}\]
这样的模型叫做平行线模型,
处理组的数据与对照组的数据服从斜率相同、截距不同的一元线性回归模型。
比每个组单独建模更有效。
在R建模函数(如lm())中将这样的公式写成y ~ x + f,
这里f是一个因子的主效应,
对于二值因子,
用模型截距项(\(\beta_0\))表示对应于水平0的截距,
用f的系数(\(\beta_2\))加模型截距项表示对应于水平1的截距。
如果检验: \[H_0: \beta_2 = 0\] 则不显著时, 可以认为在处理组和对照组中\(y\)与\(x\)的关系没有显著差异。
进一步考虑
\[
Ey = \beta_0 + \beta_1 x + \beta_2 f + \beta_3 f x
\]
相当于
\[\begin{aligned}
Ey = \begin{cases}
\beta_0 + \beta_1 x, & \text{对照组} \\
(\beta_0 + \beta_2) + (\beta_1 + \beta_3) x, & \text{处理组}
\end{cases}
\end{aligned}\]
比每个组单独建立回归模型更有效。
在R建模函数中这个模型可以写成y ~ x + f + x:f或者y ~ x*f,
其中x对应于系数\(\beta_1\),
f对应于系数\(\beta_2\),
f:x对应于系数\(\beta_3\)。
可以检验 \[H_0: \beta_3=0\] 不显著时可以用平行线模型。
例33.5 考虑MASS包的whiteside数据。
因变量Gas是天然气用量,
自变量包括一个因子Insul,
表示是否安装了隔热层(Before和After),
一个连续型变量Temp为室外温度。
按是否安装了隔热层分别作图并显示线性回归拟合线:
data(whiteside, package="MASS")
ggplot(data=whiteside, mapping = aes(
x = Temp, y = Gas )) +
geom_point() +
geom_smooth(method="lm", se=FALSE) +
facet_wrap(~ Insul, ncol=2)## `geom_smooth()` using formula 'y ~ x'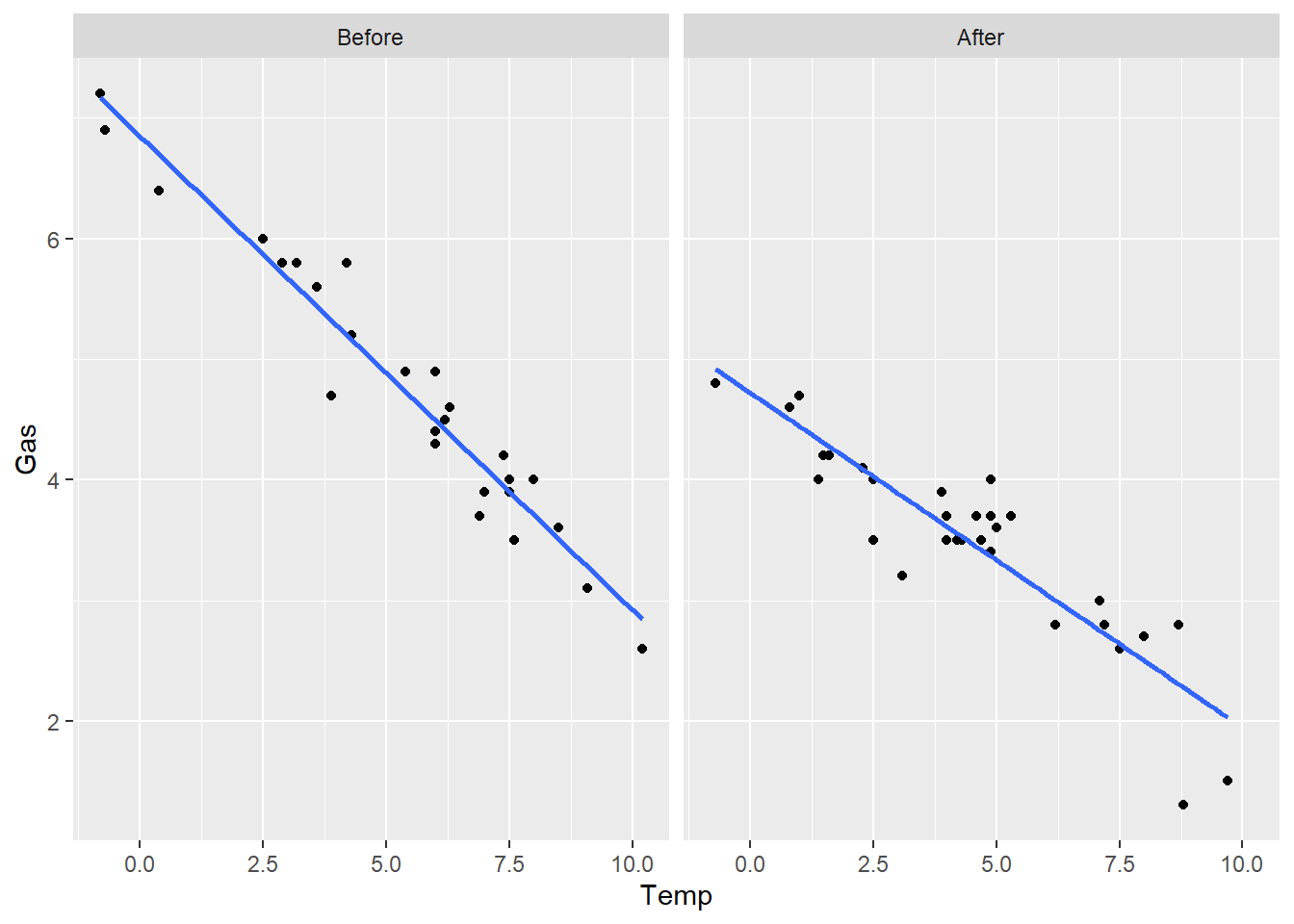
从图上看,两组的截距项有明显差距, 斜率的差距不一定显著。
拟合平行线模型:
##
## Call:
## lm(formula = Gas ~ Temp + Insul, data = whiteside)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.74236 -0.22291 0.04338 0.24377 0.74314
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 6.55133 0.11809 55.48 <2e-16 ***
## Temp -0.33670 0.01776 -18.95 <2e-16 ***
## InsulAfter -1.56520 0.09705 -16.13 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.3574 on 53 degrees of freedom
## Multiple R-squared: 0.9097, Adjusted R-squared: 0.9063
## F-statistic: 267.1 on 2 and 53 DF, p-value: < 2.2e-16以“Before”为基线, 所以Before组的截距为\(6.55\), After组的截距为\(6.55 - 1.57\)。
设定两组分别有不同斜率:
##
## Call:
## lm(formula = Gas ~ Temp + Insul + Insul:Temp, data = whiteside)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.97802 -0.18011 0.03757 0.20930 0.63803
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 6.85383 0.13596 50.409 < 2e-16 ***
## Temp -0.39324 0.02249 -17.487 < 2e-16 ***
## InsulAfter -2.12998 0.18009 -11.827 2.32e-16 ***
## Temp:InsulAfter 0.11530 0.03211 3.591 0.000731 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.323 on 52 degrees of freedom
## Multiple R-squared: 0.9277, Adjusted R-squared: 0.9235
## F-statistic: 222.3 on 3 and 52 DF, p-value: < 2.2e-16交叉项也显著, 说明应该使用不同斜率项的模型。
有些例子中如果忽略了分类变量, 结论可能是错误的。
例33.6 考察iris数据中花萼长宽之间的关系。 数据中有三个品种的花, 仅考虑其中的setosa和versicolor两个品种。
下面的程序做了散点图和回归直线。
d.iris2 <- iris |>
select(Sepal.Length, Sepal.Width, Species) |>
filter(Species %in% c("setosa", "versicolor")) |>
mutate(Species = factor(Species, levels=c("setosa", "versicolor")))
ggplot(data=d.iris2, mapping = aes(
x = Sepal.Length, y = Sepal.Width )) +
geom_point(mapping = aes(color = Species)) +
geom_smooth(method="lm", se=FALSE)## `geom_smooth()` using formula 'y ~ x'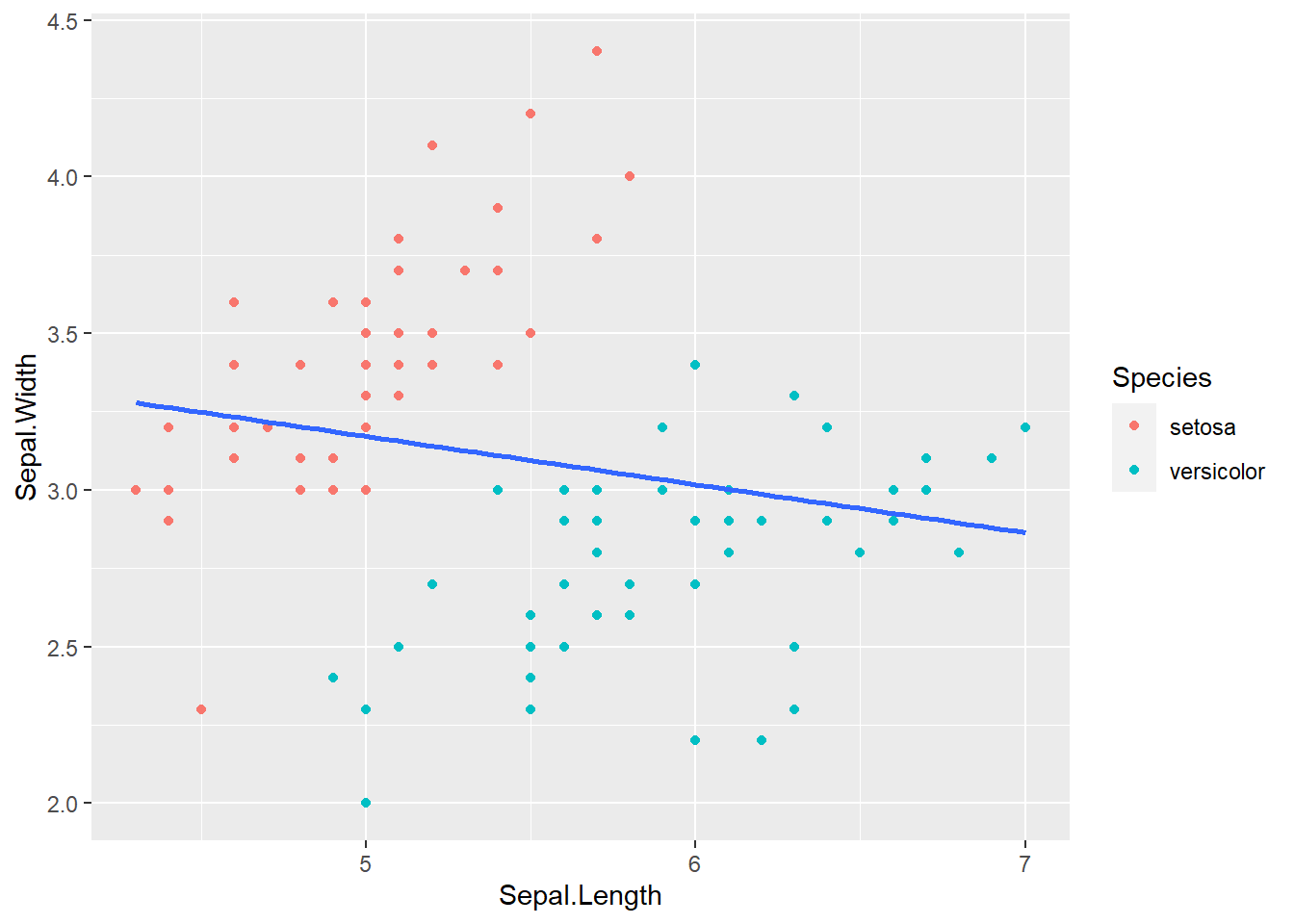
从图形看,回归结果花萼长、宽是负相关的, 这明显不合理,出现了“悖论”。 实际是因为两个品种的样本混杂在一起了。 这个回归的程序和结果如下:
##
## Call:
## lm(formula = Sepal.Width ~ Sepal.Length, data = d.iris2)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.17136 -0.26382 -0.04468 0.29966 1.33618
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 3.93951 0.40621 9.698 5.47e-16 ***
## Sepal.Length -0.15363 0.07375 -2.083 0.0398 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.4709 on 98 degrees of freedom
## Multiple R-squared: 0.04241, Adjusted R-squared: 0.03263
## F-statistic: 4.34 on 1 and 98 DF, p-value: 0.03984回归结果在0.05水平下显著。 这也给出了一个例子, 即回归结果检验显著, 并不能说明模型就是合理的。
我们采用平行线模型,
加入Species分类变量作为回归自变量:
##
## Call:
## lm(formula = Sepal.Width ~ Sepal.Length + Species, data = d.iris2)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.88917 -0.14677 -0.02517 0.16643 0.64444
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 1.06519 0.32272 3.301 0.00135 **
## Sepal.Length 0.47200 0.06398 7.377 5.51e-11 ***
## Speciesversicolor -1.09696 0.08170 -13.427 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.2799 on 97 degrees of freedom
## Multiple R-squared: 0.665, Adjusted R-squared: 0.6581
## F-statistic: 96.28 on 2 and 97 DF, p-value: < 2.2e-16现在花萼长度变量的系数为正而且高度显著。
两个品种区别的变量Speciesversicolor表示versicolor品种取1,
setosa取0的哑变量。
versicolor品种的花萼宽度与setosa相比在长度相等的情况下平均较小。
考虑斜率也不同的模型:
lm.iris3 <- lm(Sepal.Width
~ Sepal.Length + Species + Species:Sepal.Length,
data=d.iris2)
summary(lm.iris3)##
## Call:
## lm(formula = Sepal.Width ~ Sepal.Length + Species + Species:Sepal.Length,
## data = d.iris2)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.72394 -0.16281 -0.00306 0.15936 0.60954
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -0.5694 0.5352 -1.064 0.290049
## Sepal.Length 0.7985 0.1067 7.487 3.41e-11 ***
## Speciesversicolor 1.4416 0.6891 2.092 0.039069 *
## Sepal.Length:Speciesversicolor -0.4788 0.1292 -3.707 0.000351 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.2632 on 96 degrees of freedom
## Multiple R-squared: 0.707, Adjusted R-squared: 0.6978
## F-statistic: 77.2 on 3 and 96 DF, p-value: < 2.2e-16结果中交互作用项Speciesversicolor:Sepal.Length是显著的,
这提示两组的斜率不同。
下面的图形是对两个品种分别拟合一条回归直线的结果。
ggplot(data=d.iris2, mapping = aes(
x = Sepal.Length, y = Sepal.Width, color = Species)) +
geom_point() +
geom_smooth(method="lm", se=FALSE)## `geom_smooth()` using formula 'y ~ x'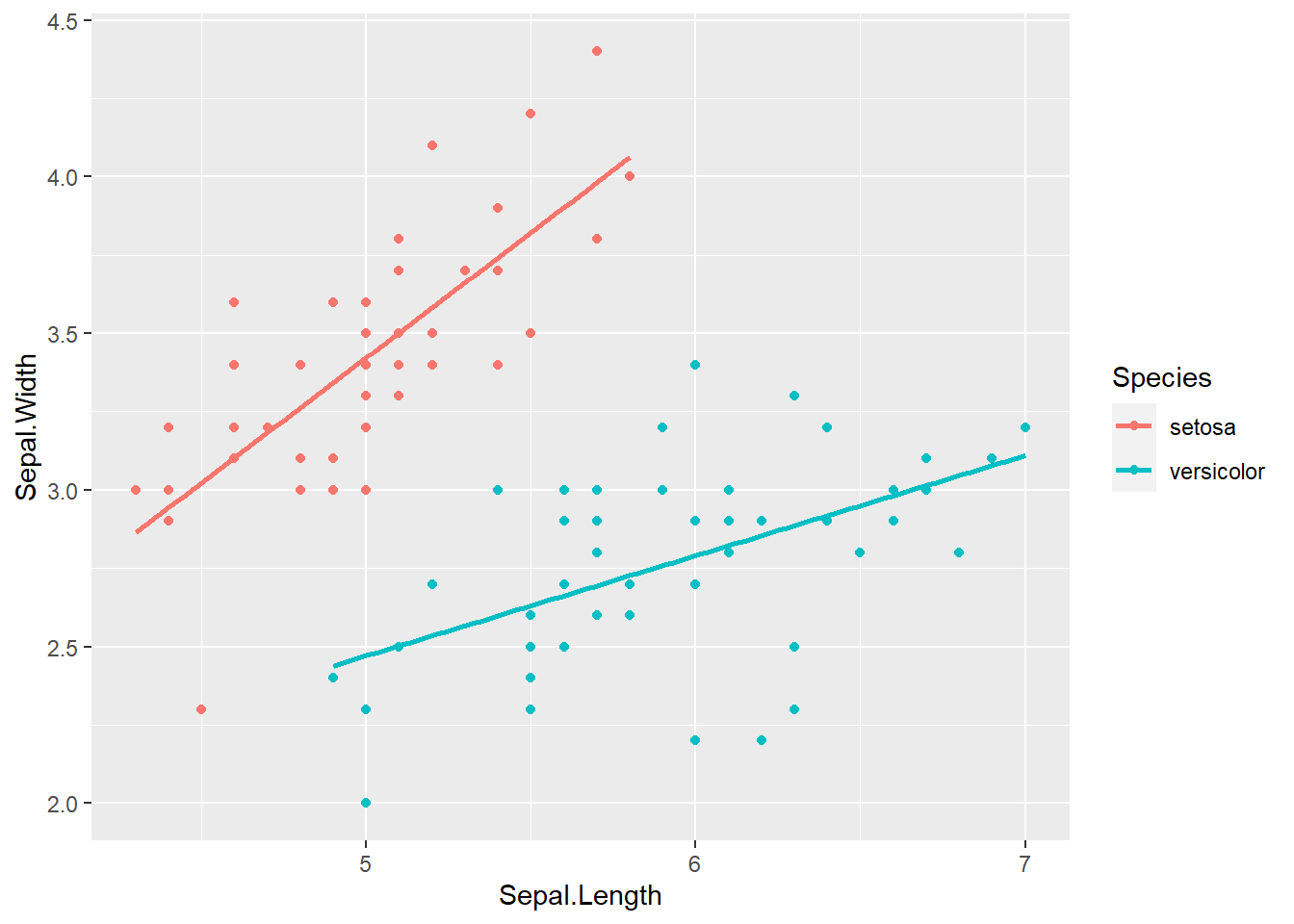
33.10.3 多值哑变量
如果变量\(f\)是一个有\(k\)分类的变量, 可以将\(f\)变成\(k-1\)个取0、1值的哑变量 \(z_1, z_2, \dots, z_{k-1}\)。
例如,\(f\)取三种不同的类别,可以转换为两个哑变量\(z_1, z_2\), 常用的编码方式为: \[\begin{aligned} & f=1 \Leftrightarrow (z_1, z_2)=(0,0), \\ & f=2 \Leftrightarrow (z_1, z_2)=(1,0), \\ & f=3 \Leftrightarrow (z_1, z_2)=(0,1) \end{aligned}\] 这是将\(f=1\)看成对照组。
在R中,
用model.matrix(y ~ x1 + f, data=d)
可以生成将因子f转换成哑变量后的包含因变量和自变量的矩阵。
详见34.2。
注意,使用多值的分类变量作为自变量时, 一定要显式地将其转换成因子类型再加入到公式中, 否则用数值表示的分类变量会被当作普通连续型自变量。
例33.7 以iris数据为例, 用Petal.Width为因变量, Petal.Lenth和Species为自变量, 建立有三个分组的平行线模型。
##
## Call:
## lm(formula = Petal.Width ~ Species + Petal.Length, data = iris)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.63706 -0.07779 -0.01218 0.09829 0.47814
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -0.09083 0.05639 -1.611 0.109
## Speciesversicolor 0.43537 0.10282 4.234 4.04e-05 ***
## Speciesvirginica 0.83771 0.14533 5.764 4.71e-08 ***
## Petal.Length 0.23039 0.03443 6.691 4.41e-10 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.1796 on 146 degrees of freedom
## Multiple R-squared: 0.9456, Adjusted R-squared: 0.9445
## F-statistic: 845.5 on 3 and 146 DF, p-value: < 2.2e-16这里分类变量Species有3个水平,
用两个哑变量Speciesversicolor和Speciesvirginica表示,
这两个变量分别是类别versicolor和virginica的示性函数值。
关于哑变量检验依赖于所使用的对照,
这里采用的是默认的contr.treatment()对照,
以3个水平中第一个水平setosa为基线,
summary()关于哑变量Speciesversicolor的系数的检验对应与零假设“versicolor和setosa的模型截距项相同”,
关于关于哑变量Speciesvirginica的系数的检验对应与零假设“virginica和setosa的模型截距项相同”。
为了检验分类变量Species的主效应在模型中是否显著,
应该使用anova()函数:
## Analysis of Variance Table
##
## Response: Petal.Width
## Df Sum Sq Mean Sq F value Pr(>F)
## Species 2 80.413 40.207 1245.887 < 2.2e-16 ***
## Petal.Length 1 1.445 1.445 44.775 4.409e-10 ***
## Residuals 146 4.712 0.032
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1这个结果就显示了Species的主效应在模型中有显著影响。
anova()进行F检验,
对因子和包含因子的交互作用效应检验效应的显著性而非单个哑变量的显著性;
另外,
anova()进行的是序贯的检验称为第一类检验,
比如,上面结果关于Species的结果是包含自变量Species的模型与仅有截距项的模型比较的F检验,
而关于Petal.Length的结果是包含自变量Species和Petal.Length的模型与仅包含自变量Species的模型比较的F检验。
summary()函数结果中的t检验则是进行的第三类检验,
这是包含某个变量(或哑变量)的模型与去掉此变量的模型的比较。
也可以利用下面比较嵌套模型的方法, 参见33.11。
33.11 嵌套模型的比较
如果两个多元线性回归模型, 第一个模型中的自变量都在第二个模型中, 且第二个模型具有更多的自变量, 可以通过对第二个模型的参数施加约束(如某些斜率项等于零)变成第一个模型, 则称第一个模型嵌套在第二个模型中。
例如:第一个模型中自变量为\(x_1, x_2, x_5\), 第二个模型自变量为\(x_1, x_2, x_3, x_4, x_5\), 则第一个模型嵌套在第二个模型中。
又如:第一个模型自变量为\(x_1, x_2\), 第二个模型自变量为\(x_1, x_2, x_1^2, x_2^2, x_1 x_2\), 则第一个模型嵌套在第二个模型中。 这时令\(x_3=x_1^2\), \(x_4=x_2^2\), \(x_5=x_1 x_2\), 第二个模型变成有5个自变量的多元线性回归模型。
在嵌套的模型中, 相对而言自变量多的模型叫做完全模型(full model), 自变量少的模型叫做简化模型(reduced model)。
完全模型是否比简化模型更好? 在回归模型选择中贯彻一个“精简性”原则(Ocam’s razor): 在对建模数据拟合效果相近的情况下, 越简单的模型越好。
例如:全模型是 \[ Ey = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \beta_3 x_3 + \beta_4 x_4 , \] 精简模型是 \[ Ey=\beta_0 + \beta_1 x_1 + \beta_2 x_2 , \] 判断两个模型是否没有显著差异,只要检验: \[ H_0: \beta_3 = \beta_4 = 0 , \] 这可以构造一个方差分析F检验,
设全模型有\(t\)个自变量, 模型得到的回归残差平方和为\(\text{SSE}_f\); 设精简模型有\(s\)个自变量(\(s < t\)), 模型得到的回归残差平方和为\(\text{SSE}_r\); 检验零假设为多出的自变量对应的系数都等于零。 检验统计量为 \[ F = \frac{(\text{SSE}_r - \text{SSE}_f)/(t-s)}{\text{SSE}_f/(n-t-1)} \] 在全模型成立且\(H_0\)成立时,\(F\)服从\(F(t-s, n-t-1)\)分布。 计算右侧p值。
在R中用anova()函数比较两个嵌套的线性回归结果可以进行这样的方差分析F检验。
例33.8 餐馆营业额回归模型的比较。
lmrst01是完全模型,包含5个自变量;
lmrst02是嵌套的精简模型,
包含居民数、人均餐费、到市中心距离共3个自变量。
用anova()函数可以检验多出的变量是否有意义:
## Analysis of Variance Table
##
## Model 1: 营业额 ~ 居民数 + 人均餐费 + 月收入 + 餐馆数 +
## 距离
## Model 2: 营业额 ~ 居民数 + 人均餐费 + 距离
## Res.Df RSS Df Sum of Sq F Pr(>F)
## 1 19 2153.0
## 2 21 2267.2 -2 -114.17 0.5038 0.6121模型p值为0.61, 在0.05水平下不拒绝多出的月收入和餐馆数的系数全为零的零假设, 两个模型的效果没有显著差异, 应选择更精简的模型。
33.12 非嵌套模型的比较
方差分析检验仅能比较嵌套模型。
对不同模型计算AIC,
取AIC较小的模型,
这可以对非嵌套的模型进行比较选择。
R中用AIC()函数比较两个回归结果的AIC值。
如:
## df AIC
## lmrst01 7 196.3408
## lmrst02 5 193.6325精简模型lmrst02的AIC更小,是更好的模型。
AIC和BIC基于最大似然估计的似然函数值,
所以最好使用最大似然估计,
对线性模型,
系数的最大似然估计与最小二乘估计相同,
但是方差的最大似然估计与最小二乘估计不同。
目前lm()仅支持最小二乘估计。
33.13 参数线性组合的检验
\(H_0: \beta_j = 0\)这样关于系数的检验, 以及\(H_0: \beta_1 = \dots = \beta_p = 0\)这样的检验, 是关于回归系数线性组合的检验的特例。
33.13.1 可估性、对照
对一般的线性模型 \[ \boldsymbol{Y} = X \boldsymbol{\beta} + \boldsymbol{\varepsilon}, \] 其中\(\boldsymbol{\varepsilon} \sim \text{N}(0, \sigma^2 I)\), \(X\)称为设计阵, \(\boldsymbol{\beta}\)为回归系数。 如果设计阵\(X_{n \times p}\)列满秩, 则 \[ \hat{\boldsymbol \beta} = (X^T X)^{-1} X^T \boldsymbol{Y} \] 是\(\boldsymbol{\beta}\)的无偏估计, \(\text{Var}(\hat{\boldsymbol \beta}) = \sigma^2 (X^T X)^{-1}\), 对任意\(\boldsymbol c \neq \boldsymbol 0 \in \mathbb R^p\), 都有\(E(\boldsymbol c^T \hat{\boldsymbol \beta}) = \boldsymbol c^T \boldsymbol{\beta}\)。
如果存在\(\boldsymbol a \in \mathbb R^n\)使得\(E(\boldsymbol a^T \boldsymbol Y) = \boldsymbol c^T \boldsymbol\beta\), 则称\(\boldsymbol c^T \boldsymbol{\beta}\)线性可估。 当设计阵\(X\)列满秩时所有的\(\boldsymbol c^T \boldsymbol\beta\)都是线性可估的。
但是, 如果\(X\)非列满秩, 则存在\(\boldsymbol c \in \mathbb R^p\)使得\(\boldsymbol c^T \boldsymbol\beta\)没有无偏估计。 事实上, 只要\(\boldsymbol c \neq \boldsymbol 0\)使得\(X \boldsymbol c = \boldsymbol 0\), 则\(\boldsymbol c^T \boldsymbol\beta\)非线性可估。 \(\boldsymbol c^T \boldsymbol\beta\)线性可估, 当且仅当\(\boldsymbol c\)等于设计阵\(X\)的行向量的线性组合, 即\(\boldsymbol c\)属于设计阵\(X\)的行向量张成的\(\mathbb R^p\)的线性子空间。 参见(陈家鼎、孙山泽、李东风、刘力平 2015) P.169定理3.3。
在利用R软件进行线性模型建模时, 通常都保证了设计阵\(X\)列满秩, 比如, 当自变量中有分类变量时, \(K\)个水平的分类变量一般都用\(K-1\)个取0、1值的哑变量来表示, 这样设计阵保持列满秩。 设\(\boldsymbol c \in \mathbb R^p\)使得\(\boldsymbol 1^T \boldsymbol c = 0\), 即\(c_1 + \dots + c_p = 0\), 称\(\boldsymbol c\)为参数的一个对照向量。 考虑检验问题 \[ H_0: c_1 \beta_1 + \dots + c_p \beta_p = a . \]
33.13.2 t检验法和嵌套模型方法
设\(\boldsymbol c\)是一个对照,
零假设
\[
H_0 : \boldsymbol c^T \boldsymbol\beta = a
\]
可以用如下的\(H_0\)下服从t分布的统计量检验:
\[
t = \frac{\boldsymbol c^T \hat{\boldsymbol\beta} - a}{
\hat\sigma \sqrt{\boldsymbol c^T (X^T X)^{-1} \boldsymbol c} } .
\]
其中\(\hat\sigma = \sqrt{\text{MSE}}\)。
R的multcomp包的lhgt函数提供了这样的检验。
也可以建立满足约束条件\(\boldsymbol c^T \boldsymbol\beta = a\)的模型,
用anova()函数比较两个模型。
下面用模拟数据说明。
例33.9 对模型 \[ y = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \varepsilon, \] 考虑检验 \[ H_0: \beta_1 = \beta_2 . \]
解答: 令\(\boldsymbol\beta = (\beta_0, \beta_1, \beta_2)^T\), \(\boldsymbol c = (0, 1, -1)^T\), \(H_0\)可以写成\(\boldsymbol c^T \boldsymbol\beta = 0\)。 我们产生一个模拟数据, 检验这样的假设。
##
## Attaching package: 'MASS'## The following object is masked from 'package:dplyr':
##
## select##
## Attaching package: 'TH.data'## The following object is masked from 'package:MASS':
##
## geysersim.lt <- function(n=30,
betas = c(100, 2, 2)){
x1 <- sample(1:20, size=n, replace=TRUE)
x2 <- sample(1:20, size=n, replace=TRUE)
eps <- rnorm(n, 0, 10)
y <- betas[1] + betas[2]*x1 + betas[3]*x2 + eps
data.frame(x1=x1, x2=x2, y=y)
}
set.seed(101)
d.lt <- sim.lt(betas = c(100, 2, 2))
lm.lt1 <- lm(y ~ x1 + x2, data=d.lt)
summary(lm.lt1)##
## Call:
## lm(formula = y ~ x1 + x2, data = d.lt)
##
## Residuals:
## Min 1Q Median 3Q Max
## -18.5569 -6.1377 -0.7288 5.1499 18.6338
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 99.7713 4.9133 20.306 < 2e-16 ***
## x1 1.9394 0.3188 6.084 1.70e-06 ***
## x2 2.1445 0.3054 7.021 1.51e-07 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 9.633 on 27 degrees of freedom
## Multiple R-squared: 0.7565, Adjusted R-squared: 0.7384
## F-statistic: 41.94 on 2 and 27 DF, p-value: 5.227e-09上面产生的模拟数据中设定了\(\beta_1 = \beta_2\)。 用multcomp包的lhgt函数检验\(\beta_1=\beta_2\):
##
## Simultaneous Tests for General Linear Hypotheses
##
## Fit: lm(formula = y ~ x1 + x2, data = d.lt)
##
## Linear Hypotheses:
## Estimate Std. Error t value Pr(>|t|)
## 1 == 0 -0.2051 0.4350 -0.471 0.641
## (Adjusted p values reported -- single-step method)结果不显著, 不拒绝零假设。
产生\(\beta_1 \neq \beta_2\)的模拟样本进行检验:
##
## Call:
## lm(formula = y ~ x1 + x2, data = d.ltb)
##
## Residuals:
## Min 1Q Median 3Q Max
## -22.104 -7.204 1.210 5.866 20.987
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 98.5311 4.8156 20.461 < 2e-16 ***
## x1 0.8861 0.3435 2.579 0.0157 *
## x2 2.2535 0.3254 6.925 1.93e-07 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 10.15 on 27 degrees of freedom
## Multiple R-squared: 0.7081, Adjusted R-squared: 0.6865
## F-statistic: 32.75 on 2 and 27 DF, p-value: 6.026e-08##
## Simultaneous Tests for General Linear Hypotheses
##
## Fit: lm(formula = y ~ x1 + x2, data = d.ltb)
##
## Linear Hypotheses:
## Estimate Std. Error t value Pr(>|t|)
## 1 == 0 -1.3674 0.5222 -2.619 0.0143 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
## (Adjusted p values reported -- single-step method)结果显著。
这样的检验问题也可以利用建立嵌套模型解决。
在\(\beta_1 = \beta_2\)约束下,
模型变成
\[
y = \beta_0 + \beta_1(x_1 + x_2) + \varepsilon,
\]
只要用anova()比较两个模型。
\(\beta_1 = \beta_2\)的模拟数据的检验:
##
## Call:
## lm(formula = y ~ I(x1 + x2), data = d.lt)
##
## Residuals:
## Min 1Q Median 3Q Max
## -19.0341 -5.8075 -0.6999 5.6555 18.0947
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 99.7301 4.8438 20.589 < 2e-16 ***
## I(x1 + x2) 2.0464 0.2206 9.276 4.93e-10 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 9.498 on 28 degrees of freedom
## Multiple R-squared: 0.7545, Adjusted R-squared: 0.7457
## F-statistic: 86.04 on 1 and 28 DF, p-value: 4.926e-10## Analysis of Variance Table
##
## Model 1: y ~ I(x1 + x2)
## Model 2: y ~ x1 + x2
## Res.Df RSS Df Sum of Sq F Pr(>F)
## 1 28 2526.1
## 2 27 2505.5 1 20.624 0.2223 0.6411结果不显著。
对\(\beta_1 \neq \beta_2\)的模拟数据检验:
##
## Call:
## lm(formula = y ~ I(x1 + x2), data = d.ltb)
##
## Residuals:
## Min 1Q Median 3Q Max
## -29.5424 -8.1704 -0.0426 6.2143 22.8775
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 97.5681 5.2800 18.479 < 2e-16 ***
## I(x1 + x2) 1.6002 0.2298 6.964 1.43e-07 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 11.16 on 28 degrees of freedom
## Multiple R-squared: 0.634, Adjusted R-squared: 0.6209
## F-statistic: 48.5 on 1 and 28 DF, p-value: 1.426e-07## Analysis of Variance Table
##
## Model 1: y ~ I(x1 + x2)
## Model 2: y ~ x1 + x2
## Res.Df RSS Df Sum of Sq F Pr(>F)
## 1 28 3486.8
## 2 27 2780.6 1 706.23 6.8576 0.0143 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1两个模型有显著差异。 注意尽管\(\beta_1 = \beta_2\)不成立, 但是在\(\beta_1 = \beta_2\)约束下建立的模型也显著, 这提示我们, 仅从回归模型结果显著不能说明模型就是正确的。
○○○○○○
33.13.3 多个对照的检验
设矩阵\(H_{k \times p}\)是由对照行向量组成的矩阵, 行秩为\(k\), 考虑检验 \[\begin{align} H_0: H \boldsymbol\beta = \boldsymbol a . \tag{33.1} \end{align}\] 取\(H\)为\(I_p\)的第\(j\)行且\(\boldsymbol a = 0\)时, 就是\(H_0: \beta_j = 0\)的检验; 取\(H\)为\(I_p\)且\(\boldsymbol a = \boldsymbol 0\)时, 就是\(H_0: \beta_1 = \dots = \beta_p = 0\)的检验。
可以在约束(33.1)下建立约束模型, 并与无约束的模型用F检验进行比较。 如果要检验\(H_0: H \boldsymbol\beta = \boldsymbol 0\)(即上面的\(\boldsymbol a = 0\)), F统计量为 \[\begin{align} F = \frac{\hat{\boldsymbol\beta}^T H^T [H (X^T X)^{-1} H^T]^{-1} H \hat{\boldsymbol\beta}}{ \text{MSE} } \tag{33.2} \end{align}\] 其中 \[ \text{MSE} = \frac{1}{n - p} (\boldsymbol Y - X \hat{\boldsymbol\beta})^T (\boldsymbol Y - X \hat{\boldsymbol\beta}) = \frac{1}{n - p} \sum_{i=1}^n (y_i - \hat\beta_1 x_{i1} - \dots - \hat\beta_p x_{ip})^2 . \] \(p\)是设计阵\(X\)的列数, 在所有自变量都是普通连续变量时, \(p\)等于自变量个数加1。 参见(陈家鼎、孙山泽、李东风、刘力平 2015) P.195 式(5.17)
如果要检验\(H_0: H \boldsymbol\beta = \boldsymbol a\), 其中\(H\)是\(k>1\)行的对照矩阵, 则不能使用单独检验每个对照的方法, 因为这样会产生多重比较问题, 使得第一类错误概率放大。 可以使用(33.2)这样的F检验。
在R中对参数线性组合进行检验时,
一种办法是建立满足约束的模型,
用比较嵌套模型的anova()函数进行检验。
关于因子自变量的效应之间的比较, 可以采用适当的对照函数编码, 参见34.3。
如果要对多个对照同时进行检验但希望给出每个检验的结果, 可以使用R的multcomp包, 该包使用多元t分布对(33.1)的每一行进行检验, 并控制总错误率。 因为控制了总错误率, 所以只要所有的对照中至少一个有显著差异, 就可以认为零假设\(H_0: H \boldsymbol\beta = \boldsymbol a\)被否定。 参见(Bretz, Hothorn, and Westfall 2011)节3.1。
例33.10 考虑例33.4餐馆营业额的问题。 检验 \[ H_0: \beta_3 = \beta_4 = 0, \] 即周边居民月收入和附近其它餐馆数的效应。
可以用上面的嵌套模型的anova()函数检验,
也可以用multcomp包的多元t分布方法进行检验:
##
## Simultaneous Tests for General Linear Hypotheses
##
## Fit: lm(formula = 营业额 ~ 居民数 + 人均餐费 + 月收入 +
## 餐馆数 + 距离, data = Resturant)
##
## Linear Hypotheses:
## Estimate Std. Error t value Pr(>|t|)
## 1 == 0 0.1605660 0.0556834 2.884 0.0183 *
## 2 == 0 0.0007636 0.0013556 0.563 0.8112
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
## (Adjusted p values reported -- single-step method)程序中linfct输入了两个对照行向量,
分别进行检验并控制总错误率。
注意对照向量维数等于设计阵列数,
而设计阵列数一般等于自变量个数加1,
其中第一列一般都是与截距项配合的一列1。
33.14 拟合与预测
33.14.1 拟合
有了参数最小二乘估计后,对建模用的每个数据点计算 \[ \hat y_i = \hat\beta_0 + \hat\beta_1 x_{i1} + \dots + \hat\beta_p x_{ip} , \] 称为拟合值(fitted value)。
得到回归模型结果lmres后,要对原数据框中的观测值做预测,
只要使用predict(lmres)。
33.14.2 点预测
为了使用得到的模型结果lmres对新数据做预测,
建立包含了自变量的一组新的观测值的数据框dp,
用predict(lmres, newdata=dp)做预测。
如餐馆营业额的选择自变量的回归模型lmrst02的拟合值:
## 1 2 3 4 5 6 7
## 52.1892541 -4.5010247 21.9626575 65.1136964 6.1284803 22.4083426 1.2783244
## 8 9 10 11 12 13 14
## 34.7189934 10.6275869 37.8433996 62.8524888 18.2959990 -5.5101343 14.9558131
## 15 16 17 18 19 20 21
## 8.8598588 29.8309866 78.0159456 13.1673581 15.8469287 50.7274217 27.4608977
## 22 23 24 25
## 0.2331759 22.6274030 48.9610796 27.0050675如果是一元回归,一般还画数据的散点图并画回归直线。 多元回归的图形无法在二维表现出来。
有了估计的回归方程后, 对一组新的自变量值\((x_{01}, \dots, x_{0p})\), 可以计算对应的因变量的预测值: \[ \hat y_0 = \hat\beta_0 + \hat\beta_1 x_{01} + \dots + \hat\beta_p x_{0p} \]
在R中,设lmres保存了回归结果,
newd是一个保存了新的自变量值的数据框,
此数据框结构与原建模用数据框类似但是自变量与原来不同,
且不需要有因变量。
这时用predict(lm1, data=newd)预测。
例如,利用包含居民数、人均餐费、到市中心距离的模型lmrst02,
求居民数=50(万居民),人均餐费=100(元),
距市中心10千米的餐馆的日均营业额:
## 1
## 17.88685预测的日均营业额为17.9千元。
函数expand.grid()可以对若干个变量的指定值,
生成包含所有组合的数据框,如:
## 居民数 人均餐费 距离
## 1 60 50 6
## 2 140 50 6
## 3 60 130 6
## 4 140 130 6
## 5 60 50 16
## 6 140 50 16
## 7 60 130 16
## 8 140 130 16## 1 2 3 4 5 6 7 8
## 14.186636 29.404103 26.797108 42.014574 8.488759 23.706225 21.099230 36.31669633.14.3 均值的置信区间
对\(Ey=\beta_0 + \beta_1 x_1 + \dots + \beta_p x_p\), 可以计算置信度为\(1-\alpha\)的置信区间, 称为均值的置信区间。
在predict()中加选项interval="confidence",
用level=指定置信度,
可以计算均值的置信区间。
如
predict(
lmrst02, interval="confidence", level=0.95,
newdata=data.frame(
`居民数`=50, `人均餐费`=100, `距离`=10
))## fit lwr upr
## 1 17.88685 10.98784 24.78585其中fit是预测值,lwr和upr分别是置信下限和置信上限。
33.14.4 个别值的预测区间
对\(y=\beta_0 + \beta_1 x_1 + \dots + \beta_p x_p + \varepsilon\), 可以计算置信度为\(1-\alpha\)的预测区间, 称为预测区间,预测区间比均值的置信区间要宽。
在predict()中加选项interval="prediction",
用level=指定置信度,
可以计算预测区间。
如
predict(
lmrst02, interval="prediction", level=0.95,
newdata=data.frame(
`居民数`=50, `人均餐费`=100, `距离`=10
))## fit lwr upr
## 1 17.88685 -4.795935 40.56963其中fit是预测值,lwr和upr分别是预测下限和预测上限。
33.15 利用线性回归模型做曲线拟合
某些非线性关系可以通过对因变量和自变量的简单变换变成线性回归模型。
例33.11 彩色显影中, 染料光学密度\(Y\)与析出银的光学密度\(x\) 有如下类型的关系 \[ Y \approx A e^{-B/x}, \quad B > 0 . \]
这不是线性关系。两边取对数得 \[ \ln Y \approx \ln A - B \frac{1}{x} \] 令 \[ Y^* = \ln Y, \qquad x^* = \frac{1}{x} \] 则 \[ Y^* \approx \ln A - B x^* \] 为线性关系。
从\(n\)组数据 \((x_1, y_1), (x_2, y_2), \dots, (x_n, y_n)\)得到变换的数据 \((x_1^*, y_1^*), (x_2^*, y_2^*), \dots, (x_n^*, y_n^*)\)。 对变换后的数据建立线性回归方程 \[\hat y^* = \hat a + \hat b x^*\] 反变换得 \[\hat A = e^{\hat a}, \qquad \hat B = -b\] 则有 \[\hat Y = \hat A e^{-\hat B / x}\]
○○○○○○
例33.12 考虑一个钢包容积的例子。
炼钢钢包随使用次数增加而容积增大。 测量了13组这样的数据:
SteelBag <- data.frame(
x = c(2, 3, 4, 5, 7, 8, 10,
11, 14, 15, 16, 18, 19),
y = c(106.42, 108.20, 109.58, 109.50, 110.0,
109.93, 110.49, 110.59, 110.60, 110.90,
110.76, 111.00, 111.20)
)| x | y |
|---|---|
| 2 | 106.42 |
| 3 | 108.20 |
| 4 | 109.58 |
| 5 | 109.50 |
| 7 | 110.00 |
| 8 | 109.93 |
| 10 | 110.49 |
| 11 | 110.59 |
| 14 | 110.60 |
| 15 | 110.90 |
| 16 | 110.76 |
| 18 | 111.00 |
| 19 | 111.20 |
散点图:
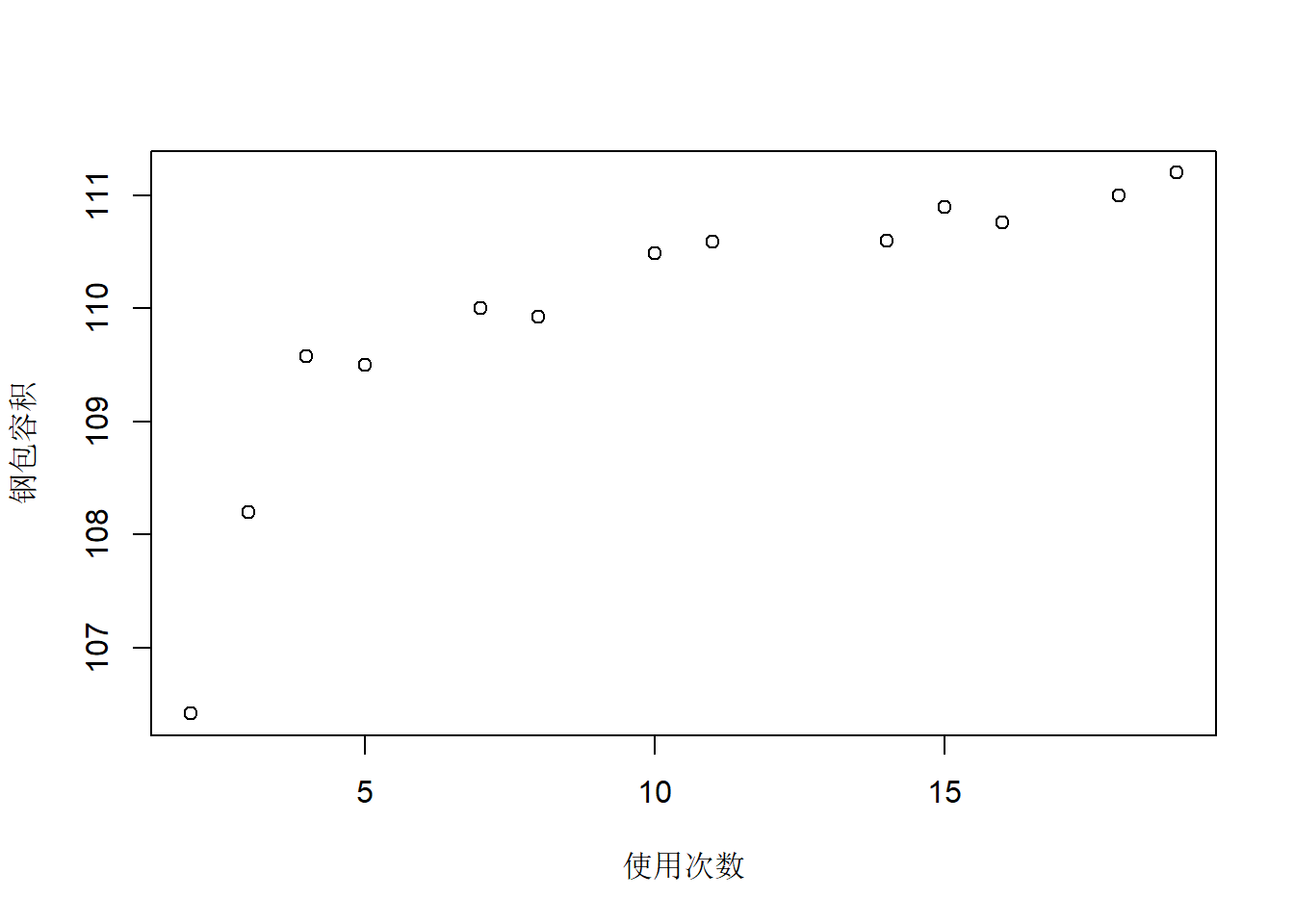
散点图呈现非线性。
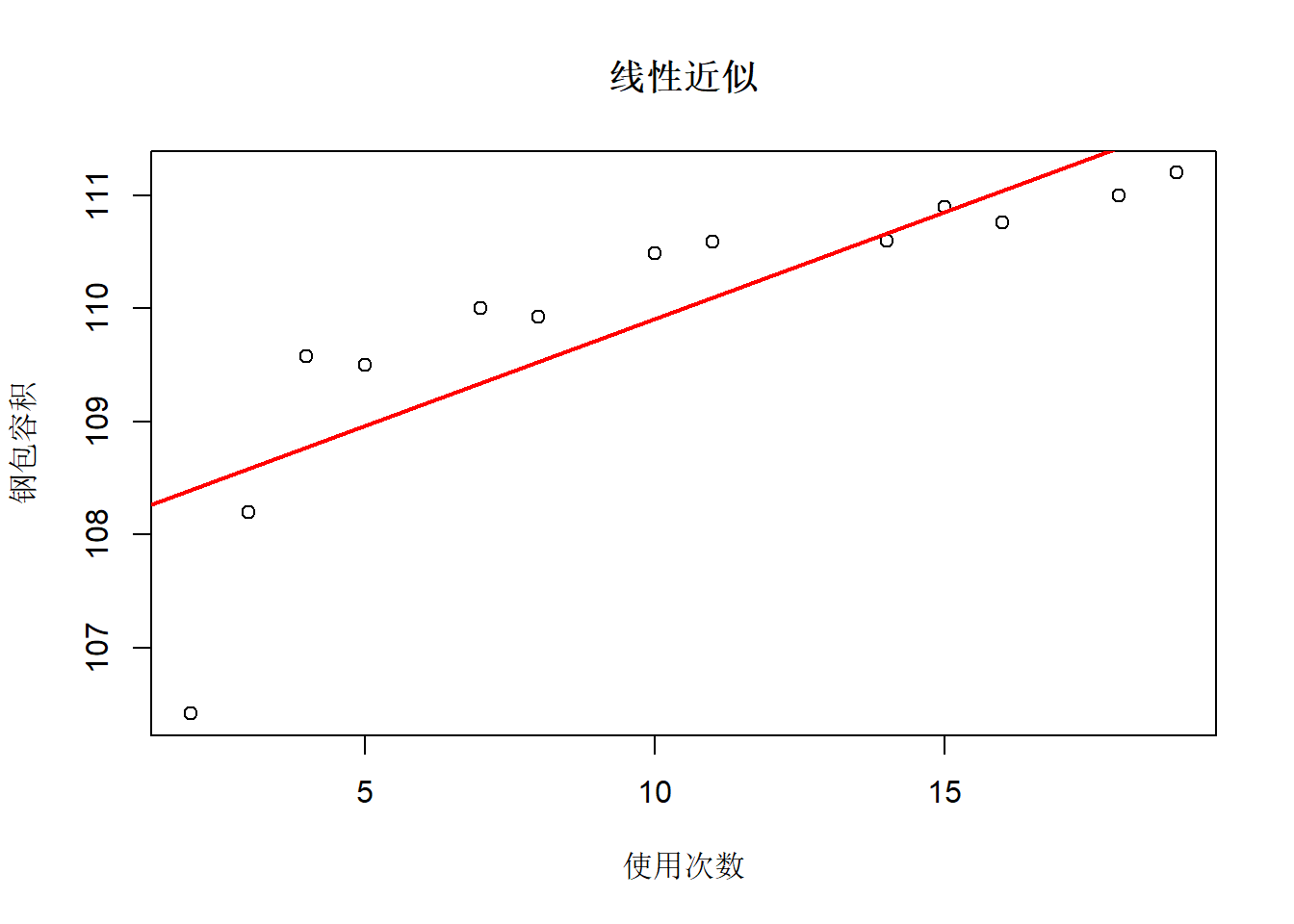
用线性回归近似:
##
## Call:
## lm(formula = y ~ x, data = SteelBag)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.97615 -0.38502 0.04856 0.53724 0.80611
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 108.01842 0.44389 243.346 < 2e-16 ***
## x 0.18887 0.03826 4.937 0.000445 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.7744 on 11 degrees of freedom
## Multiple R-squared: 0.689, Adjusted R-squared: 0.6607
## F-statistic: 24.37 on 1 and 11 DF, p-value: 0.000445结果显著。 \(R^2=0.69\)。 拟合图:
残差诊断:
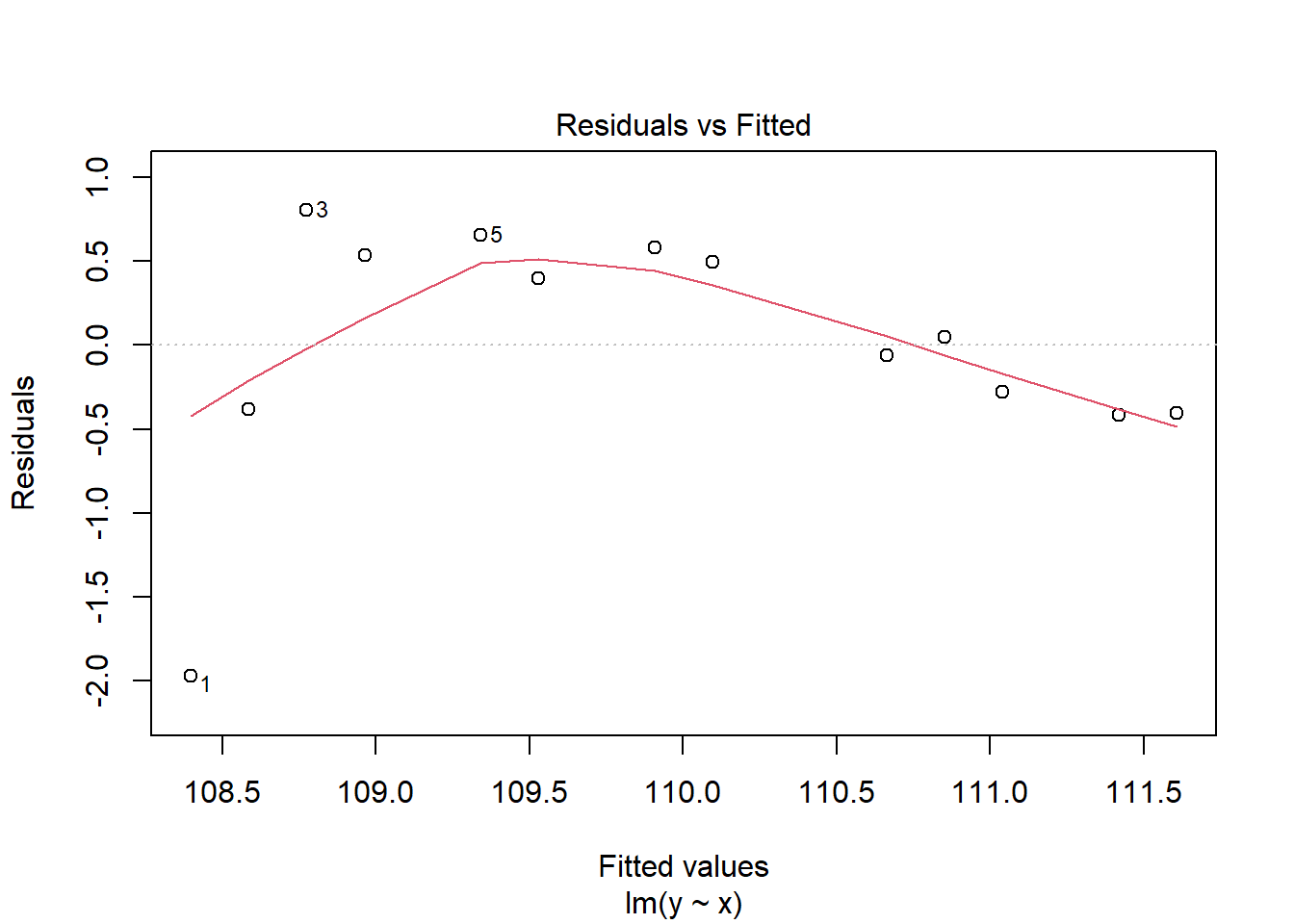
残差图呈现非线性。
用双曲线模型: \[ \frac{1}{y} \approx a + b \frac{1}{x} \]
令\(x^* = 1/x, y^* = 1/y\),化为线性模型 \[y^* \approx a + b x^*\]
\((x^*, y^*)\)的散点图:
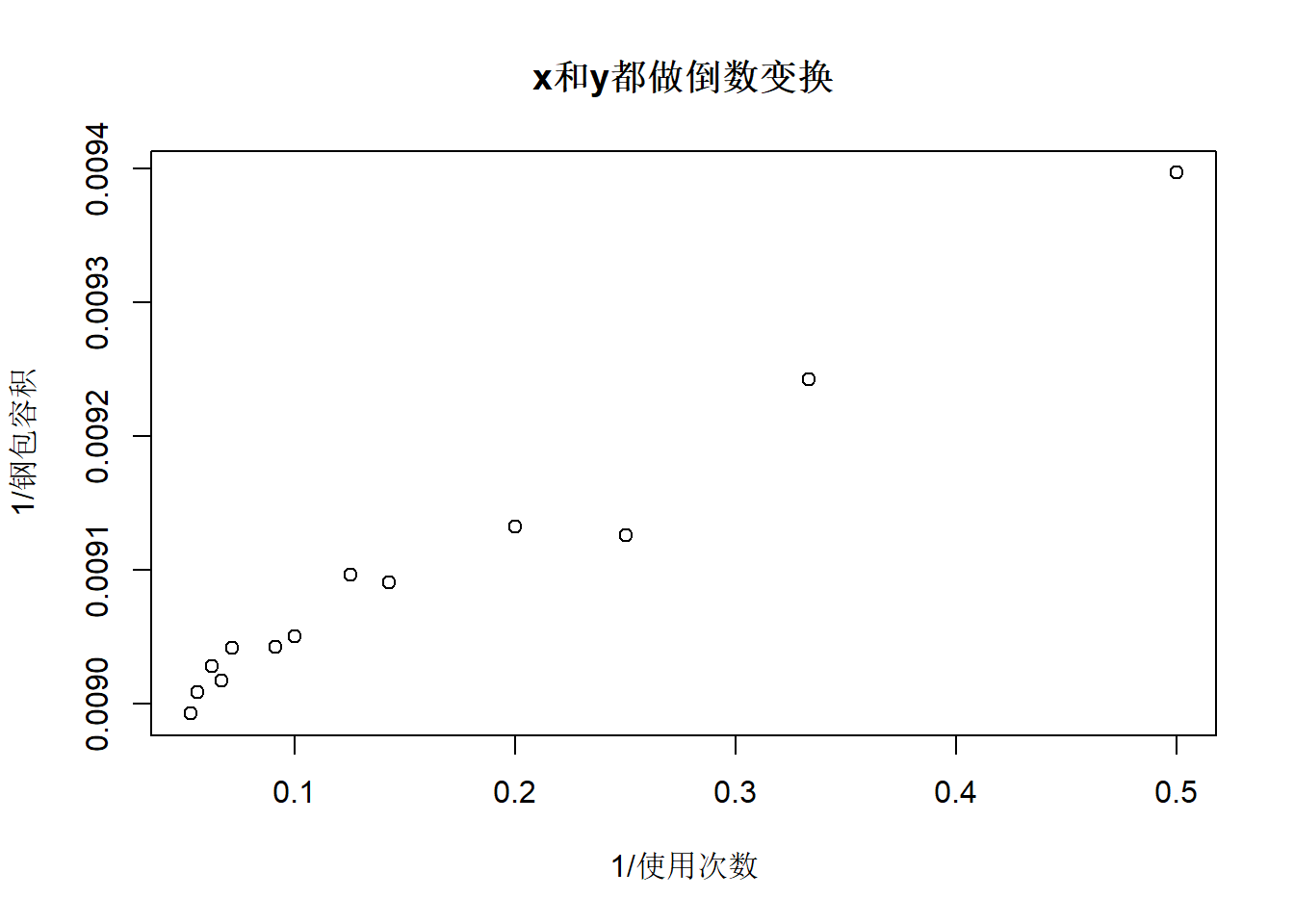
\(y^*\)对\(x^*\)的回归:
##
## Call:
## lm(formula = I(1/y) ~ I(1/x), data = SteelBag)
##
## Residuals:
## Min 1Q Median 3Q Max
## -4.817e-05 -3.686e-06 4.000e-07 1.008e-05 2.642e-05
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 8.967e-03 8.371e-06 1071.14 < 2e-16 ***
## I(1/x) 8.292e-04 4.118e-05 20.14 4.97e-10 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.903e-05 on 11 degrees of freedom
## Multiple R-squared: 0.9736, Adjusted R-squared: 0.9712
## F-statistic: 405.4 on 1 and 11 DF, p-value: 4.97e-10结果显著。 解得\(\hat a = 0.008967\), \(\hat b = 0.0008292\), 经验公式为 \[ \frac{1}{\hat y} = 0.008967 + 0.0008292 \frac{1}{x} \] \(R^2\)从线性近似的0.69提高到了0.97。
拟合图:
with(SteelBag, plot(
x, y, xlab="使用次数", ylab="钢包容积",
main="线性和非线性回归"
))
abline(lmsb1, col="red", lwd=2)
curve(1/(0.008967 + 0.0008292/x), 1, 20,
col="green", lwd=2, add=TRUE)
legend("bottomright", lty=1, lwd=2,
col=c("red", "green"),
legend=c("线性回归", "曲线回归"))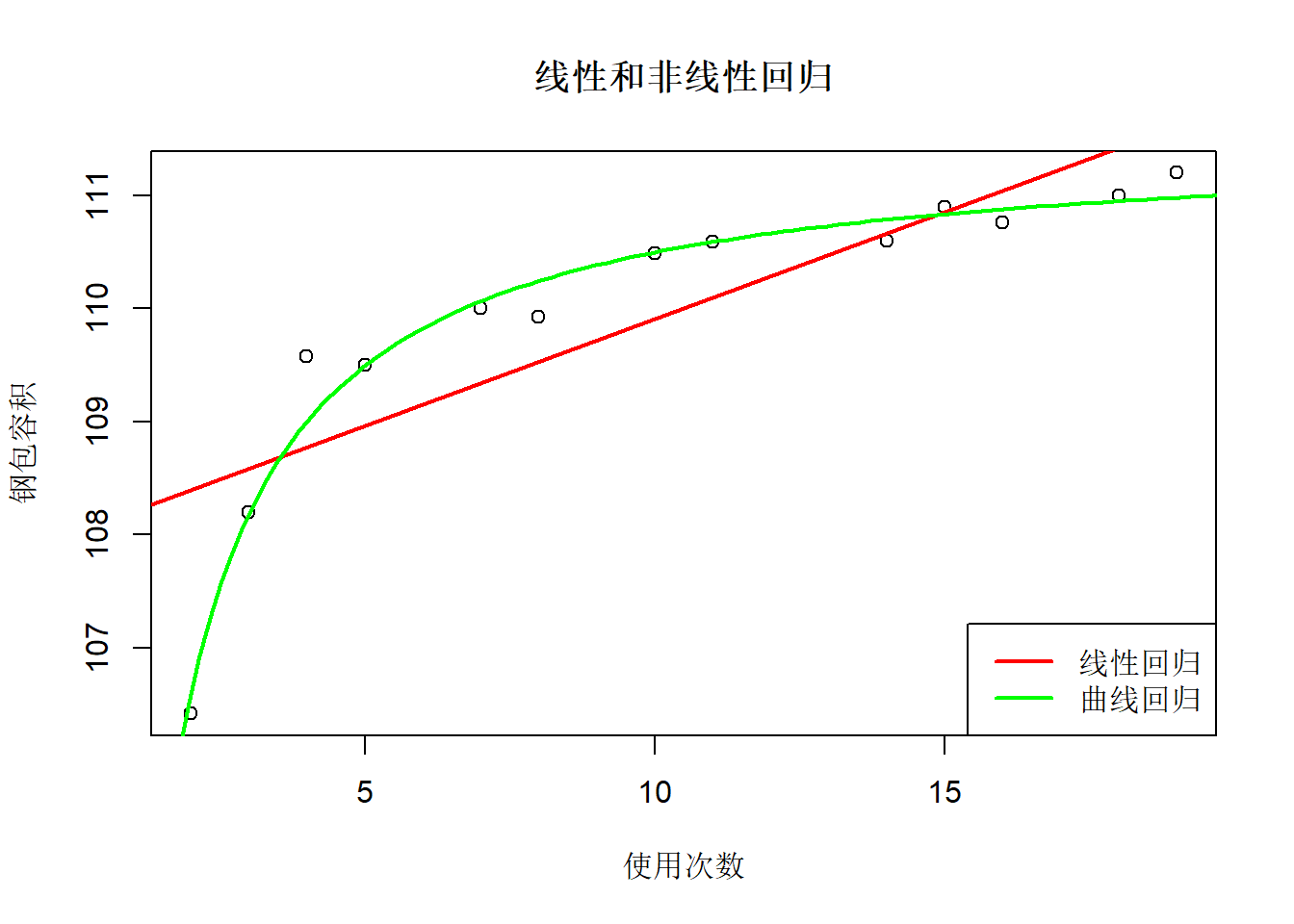
○○○○○○
例33.13 考虑Reynolds, Inc.销售业绩数据分析问题。
Reynolds, Inc.是一个工业和试验室量具厂商。 为研究销售业务员的业绩, 考察业务员从业年限(Months, 单位:月)与其销售的电子量具数量(Sales)的关系。 随机抽查了15名业务员。
| Months | Sales |
|---|---|
| 41 | 275 |
| 106 | 296 |
| 76 | 317 |
| 104 | 376 |
| 22 | 162 |
| 12 | 150 |
| 85 | 367 |
| 111 | 308 |
| 40 | 189 |
| 51 | 235 |
| 9 | 83 |
| 12 | 112 |
| 6 | 67 |
| 56 | 325 |
| 19 | 189 |
散点图:
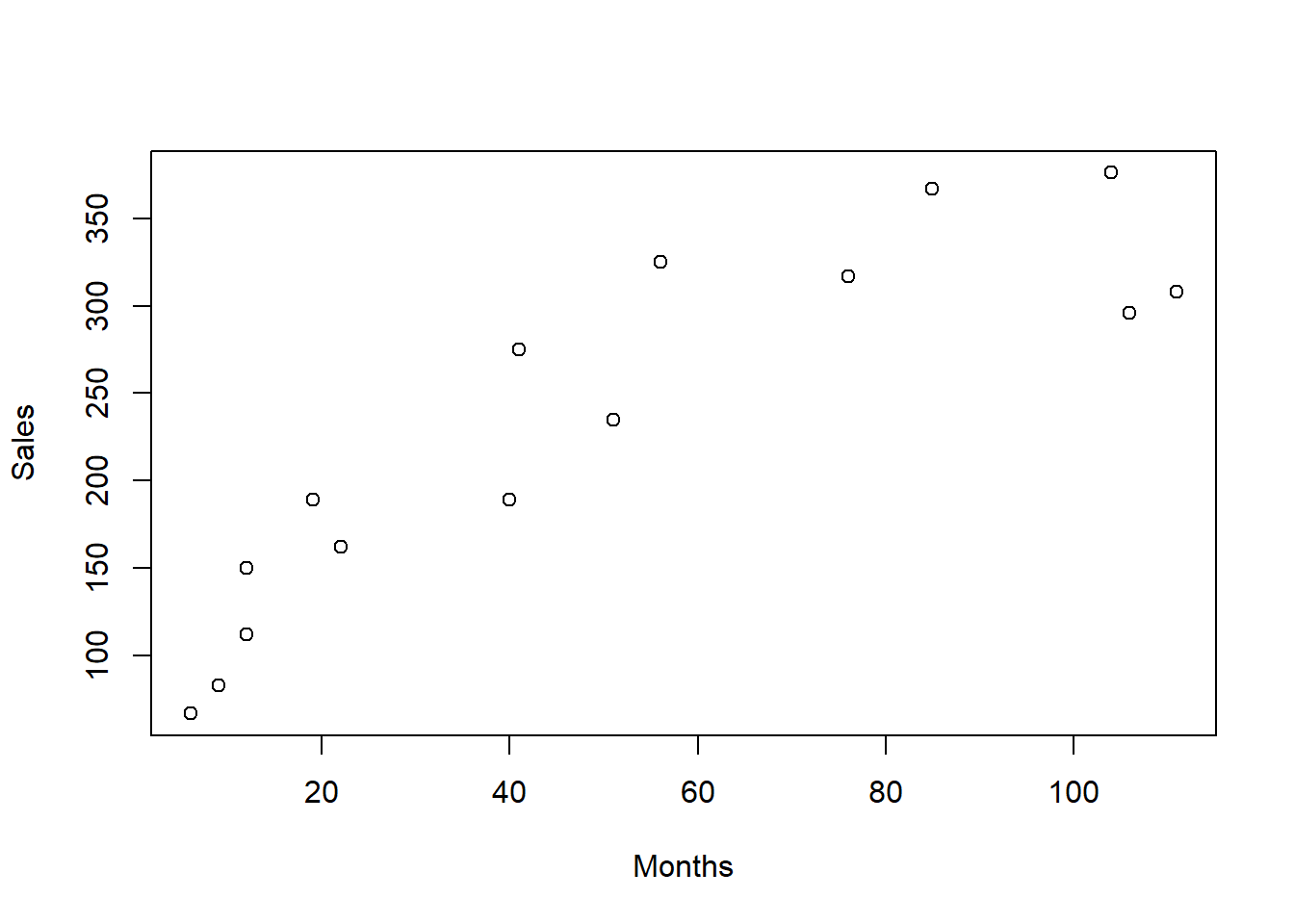
散点图呈现非线性。
用线性近似:
##
## Call:
## lm(formula = Sales ~ Months, data = Reynolds)
##
## Residuals:
## Min 1Q Median 3Q Max
## -67.166 -38.684 2.557 28.875 80.673
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 111.2279 21.6280 5.143 0.000189 ***
## Months 2.3768 0.3489 6.812 1.24e-05 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 49.52 on 13 degrees of freedom
## Multiple R-squared: 0.7812, Adjusted R-squared: 0.7643
## F-statistic: 46.41 on 1 and 13 DF, p-value: 1.239e-05结果显著。 \(R^2=0.78\)。 拟合图:
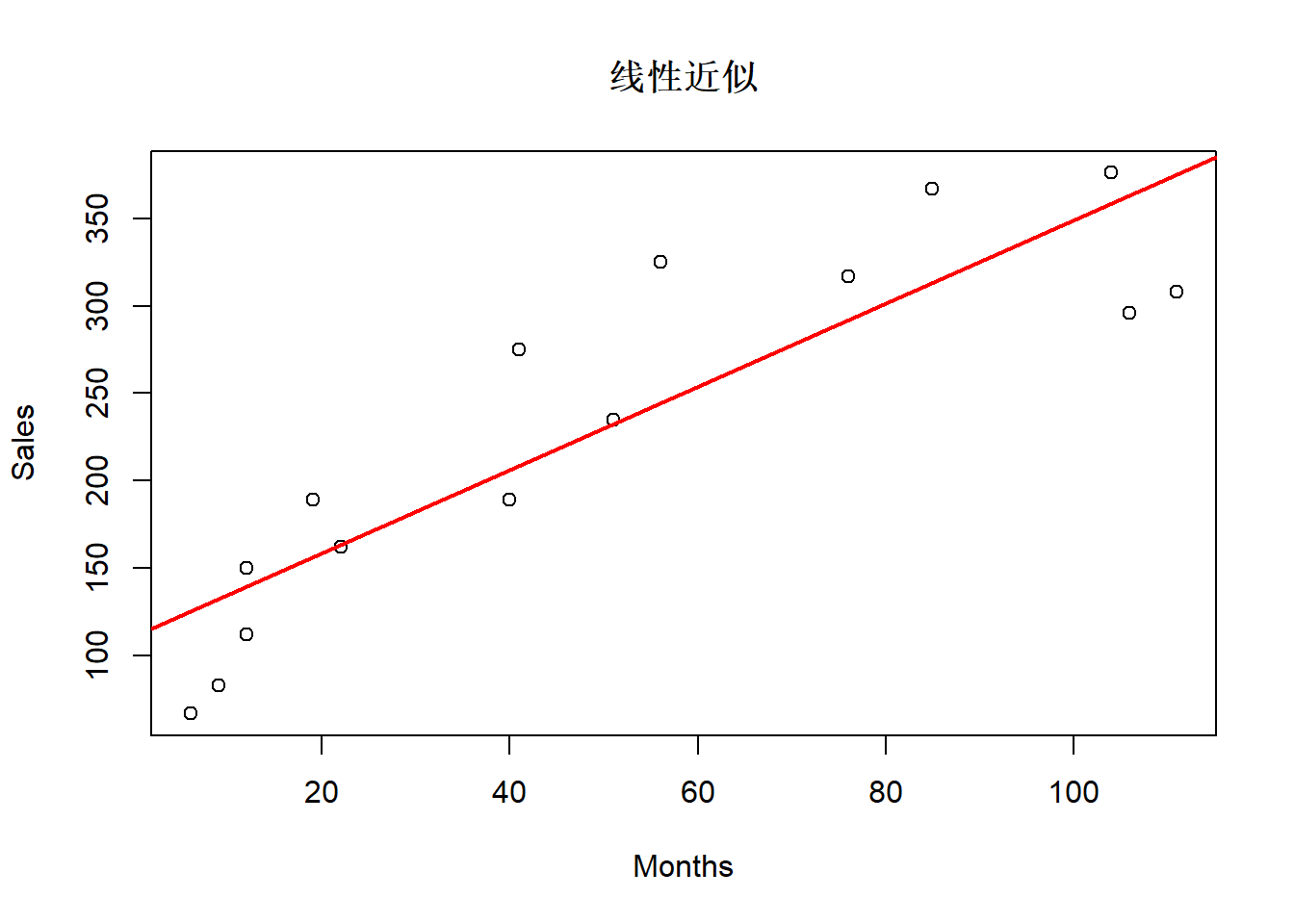
残差诊断:
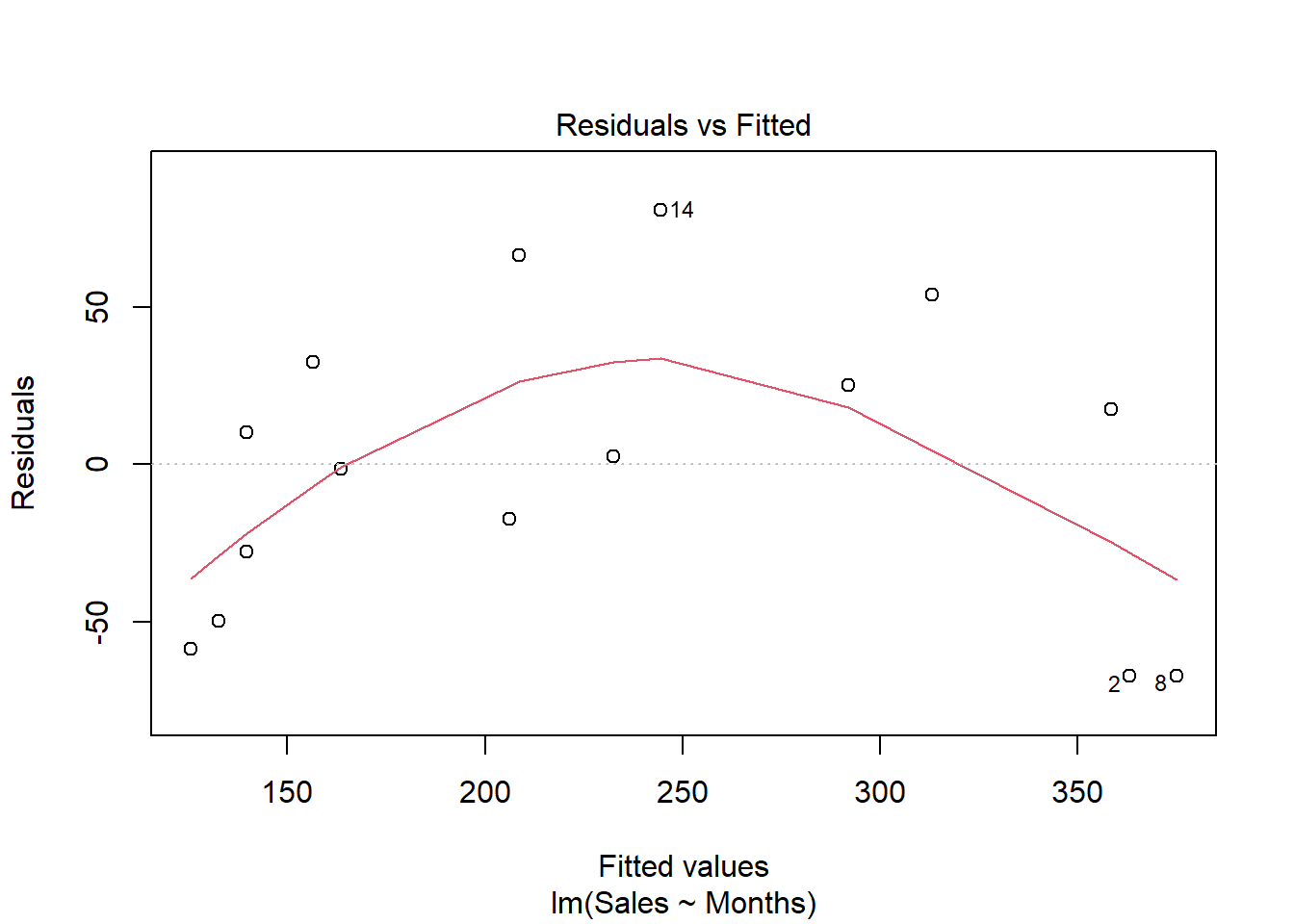
残差图有明显的非线性。
考虑最简单的非线性模型: \[ y = \beta_0 + \beta_1 x + \beta_2 x^2 + \varepsilon \] 令\(x_1 = x\), \(x_2=x^2\),有 \[ y = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \varepsilon \] 是二元线性回归模型。 作二次多项式回归:
##
## Call:
## lm(formula = Sales ~ Months + I(Months^2), data = Reynolds)
##
## Residuals:
## Min 1Q Median 3Q Max
## -54.963 -16.691 -6.242 31.996 43.789
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 45.347579 22.774654 1.991 0.06973 .
## Months 6.344807 1.057851 5.998 6.24e-05 ***
## I(Months^2) -0.034486 0.008948 -3.854 0.00229 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 34.45 on 12 degrees of freedom
## Multiple R-squared: 0.9022, Adjusted R-squared: 0.8859
## F-statistic: 55.36 on 2 and 12 DF, p-value: 8.746e-07模型显著。 \(R^2\)从线性近似的0.78提高到0.90。 \(x^2\)项的系数的显著性检验p值为0.002,显著不等于零, 说明二次项是必要的。
这样添加二次项容易造成\(x\)与\(x^2\)之间的共线性, 所以添加中心化的二次项: \[x_2 = (x - 60)^2\]
##
## Call:
## lm(formula = Sales ~ Months + I((Months - 60)^2), data = Reynolds)
##
## Residuals:
## Min 1Q Median 3Q Max
## -54.963 -16.691 -6.242 31.996 43.789
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 169.495742 21.331978 7.946 4.03e-06 ***
## Months 2.206535 0.246744 8.943 1.18e-06 ***
## I((Months - 60)^2) -0.034486 0.008948 -3.854 0.00229 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 34.45 on 12 degrees of freedom
## Multiple R-squared: 0.9022, Adjusted R-squared: 0.8859
## F-statistic: 55.36 on 2 and 12 DF, p-value: 8.746e-07with(Reynolds, plot(Months, Sales, main="线性和非线性回归"))
abline(lmre1, col="red", lwd=2)
curve(196.50 + 2.2065*x - 0.03449*(x-60)^2, 5, 110,
col="green", lwd=2, add=TRUE)
legend("bottomright", lty=1, lwd=2,
col=c("red", "green"),
legend=c("线性回归", "曲线回归"))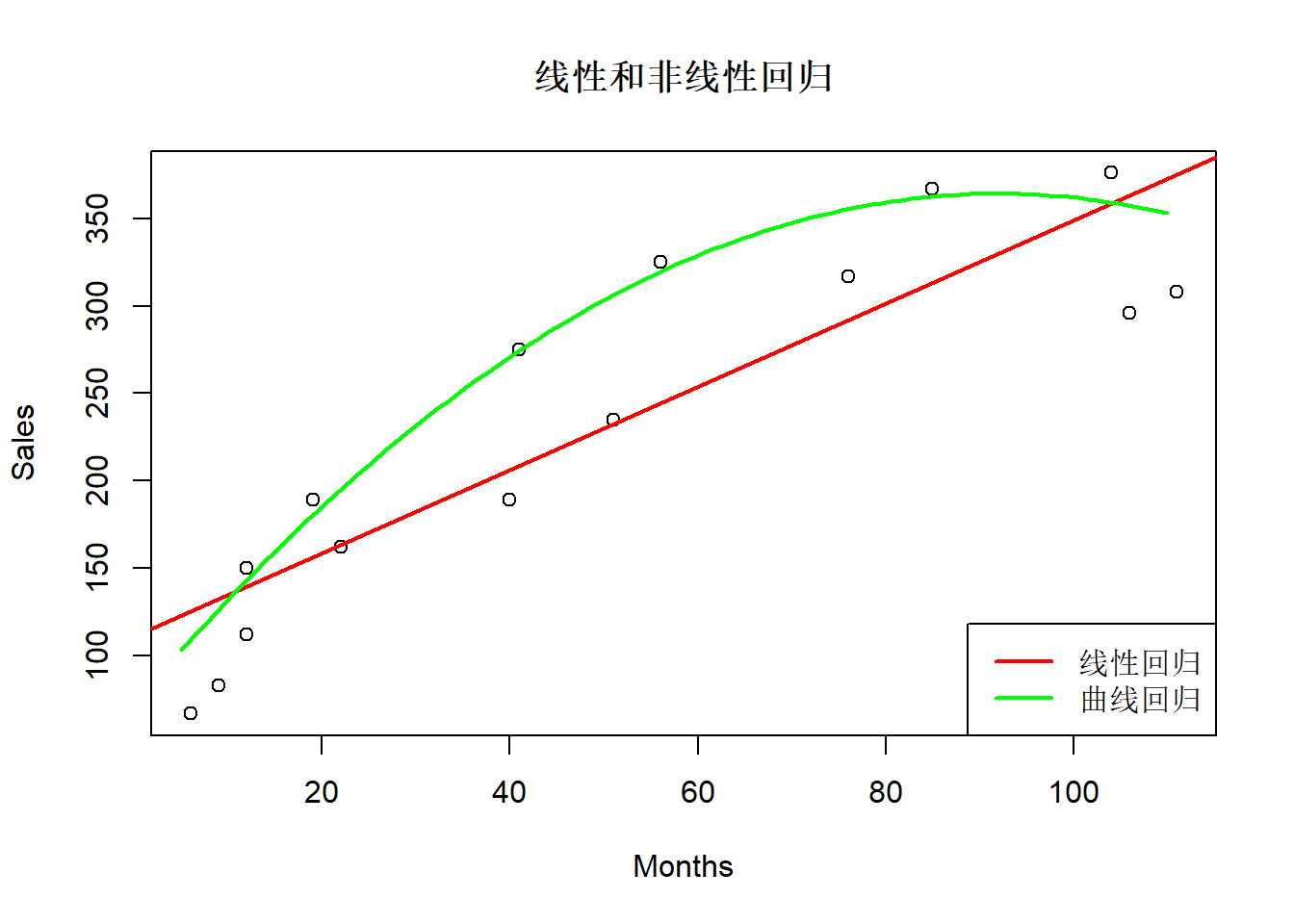
33.16 分组建立多个模型
有时希望将数据按照一个或者几个分类变量分组,
每一组分别建立模型,
并将模型结果统一列表比较。
broom包可以用来将模型结果转换成规范的数据框格式。
以肺癌病人数据为例,
建立v1对v0和age的多元线性回归模型:
## # A tibble: 34 × 6
## id age sex type v0 v1
## <dbl> <dbl> <chr> <chr> <dbl> <dbl>
## 1 1 70 F 腺癌 26.5 2.91
## 2 2 70 F 腺癌 135. 35.1
## 3 3 69 F 腺癌 210. 74.4
## 4 4 68 M 腺癌 61 35.0
## 5 5 67 M 鳞癌 238. 128.
## 6 6 75 F 腺癌 330. 112.
## 7 7 52 M 鳞癌 105. 32.1
## 8 8 71 M 鳞癌 85.2 29.2
## 9 9 68 M 鳞癌 102. 22.2
## 10 10 79 M 鳞癌 65.5 21.9
## # ℹ 24 more rows##
## Call:
## lm(formula = v1 ~ v0 + age, data = d.cancer)
##
## Residuals:
## Min 1Q Median 3Q Max
## -42.757 -11.010 -2.475 11.907 52.941
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 7.90818 33.14895 0.239 0.814
## v0 0.43288 0.05564 7.780 1.79e-07 ***
## age -0.12846 0.53511 -0.240 0.813
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 21.76 on 20 degrees of freedom
## (11 observations deleted due to missingness)
## Multiple R-squared: 0.7683, Adjusted R-squared: 0.7451
## F-statistic: 33.16 on 2 and 20 DF, p-value: 4.463e-07用broom包的tidy()函数可以将系数估计结果转换成合适的tibble数据框格式:
## # A tibble: 3 × 5
## term estimate std.error statistic p.value
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 (Intercept) 7.91 33.1 0.239 0.814
## 2 v0 0.433 0.0556 7.78 0.000000179
## 3 age -0.128 0.535 -0.240 0.813用broom包的augment()函数可以获得拟合值、残差等每个观测的回归结果:
| .rownames | v1 | v0 | age | .fitted | .resid | .hat | .sigma | .cooksd | .std.resid |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2.91 | 26.51 | 70 | 10.39 | -7.48 | 0.13 | 22.25 | 0.01 | -0.37 |
| 2 | 35.08 | 135.48 | 70 | 57.56 | -22.48 | 0.06 | 21.68 | 0.03 | -1.07 |
| 3 | 74.44 | 209.74 | 69 | 89.84 | -15.40 | 0.10 | 22.01 | 0.02 | -0.75 |
| 4 | 34.97 | 61.00 | 68 | 25.58 | 9.39 | 0.08 | 22.21 | 0.01 | 0.45 |
| 5 | 128.34 | 237.75 | 67 | 102.22 | 26.12 | 0.14 | 21.37 | 0.09 | 1.29 |
| 6 | 112.34 | 330.24 | 75 | 141.23 | -28.89 | 0.33 | 20.81 | 0.43 | -1.62 |
| 7 | 32.10 | 104.90 | 52 | 46.64 | -14.54 | 0.13 | 22.04 | 0.03 | -0.72 |
| 8 | 29.15 | 85.15 | 71 | 35.65 | -6.50 | 0.08 | 22.27 | 0.00 | -0.31 |
| 9 | 22.15 | 101.65 | 68 | 43.18 | -21.03 | 0.05 | 21.77 | 0.02 | -0.99 |
| 10 | 21.94 | 65.54 | 79 | 26.13 | -4.19 | 0.22 | 22.30 | 0.00 | -0.22 |
| 11 | 12.33 | 125.31 | 55 | 55.09 | -42.76 | 0.10 | 19.79 | 0.16 | -2.07 |
| 12 | 99.44 | 224.36 | 54 | 98.09 | 1.35 | 0.23 | 22.32 | 0.00 | 0.07 |
| 13 | 2.30 | 12.93 | 55 | 6.44 | -4.14 | 0.12 | 22.30 | 0.00 | -0.20 |
| 14 | 23.96 | 40.21 | 75 | 15.68 | 8.28 | 0.18 | 22.23 | 0.01 | 0.42 |
| 15 | 7.39 | 12.58 | 61 | 5.52 | 1.87 | 0.10 | 22.32 | 0.00 | 0.09 |
| 16 | 112.58 | 231.04 | 76 | 98.16 | 14.42 | 0.16 | 22.03 | 0.03 | 0.72 |
| 17 | 91.62 | 172.13 | 65 | 74.07 | 17.55 | 0.07 | 21.93 | 0.02 | 0.83 |
| 18 | 13.95 | 39.26 | 66 | 16.42 | -2.47 | 0.09 | 22.32 | 0.00 | -0.12 |
| 20 | 122.45 | 161.00 | 63 | 69.51 | 52.94 | 0.06 | 18.47 | 0.14 | 2.51 |
| 21 | 68.35 | 105.26 | 67 | 44.87 | 23.48 | 0.05 | 21.63 | 0.02 | 1.11 |
| 22 | 5.25 | 13.25 | 51 | 7.09 | -1.84 | 0.16 | 22.32 | 0.00 | -0.09 |
| 23 | 3.34 | 18.70 | 49 | 9.71 | -6.37 | 0.18 | 22.27 | 0.01 | -0.32 |
| 24 | 50.36 | 60.23 | 49 | 27.69 | 22.67 | 0.17 | 21.59 | 0.09 | 1.14 |
用broom包的glance()函数可以将回归的复相关系数平方、F检验p值等整体结果做成一行的数据框:
| r.squared | adj.r.squared | sigma | statistic | p.value | df | logLik | AIC | BIC | deviance | df.residual | nobs |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.77 | 0.75 | 21.76 | 33.16 | 0 | 2 | -101.87 | 211.74 | 216.28 | 9470.34 | 20 | 23 |
下面将男病人与女病人分别建模,
并以表格形式合并分组的建模结果。
用dplyr包的group_by()函数分组,
用tidyr包的nest()函数可以将分组后的数据框转换成一个新的数据框,
新数据框中有一列是列表类型,
每个元素是一个子数据框:
## # A tibble: 2 × 2
## # Groups: sex [2]
## sex data
## <chr> <list>
## 1 F <tibble [13 × 5]>
## 2 M <tibble [21 × 5]>这样,
可以用purr::map()函数对每一组分别建模,
建模结果可以借助broom包制作成合适的数据框格式,
然后用unnest()函数将不同组的结果合并成一个大数据框,如:
d.cancer %>%
group_by(sex) %>%
nest() %>%
mutate(model = map(data, function(df)
summary(lm(v1 ~ v0 + age, data=df)))) %>%
mutate(tidyr = map(model, tidy)) %>%
ungroup() %>%
dplyr::select(sex, tidyr) %>%
unnest(tidyr)## # A tibble: 6 × 6
## sex term estimate std.error statistic p.value
## <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 F (Intercept) 171. 147. 1.16 0.310
## 2 F v0 0.485 0.136 3.56 0.0235
## 3 F age -2.74 2.39 -1.15 0.316
## 4 M (Intercept) -17.2 30.5 -0.563 0.583
## 5 M v0 0.486 0.0657 7.39 0.00000528
## 6 M age 0.204 0.484 0.421 0.681当需要分组拟合许多个模型时, 这种方法比较方便。