20 研究项目管理
执行一个数据分析研究项目, 必须遵循一定的管理规则, 才能事半功倍。
20.1 可重复式科学研究
现代科学研究之所以能被大众接受, 成为主流世界观, 很大程度上要归功于“可重复结果的试验”。 现在生物、物理、化学等领域的科研越来越复杂, 重复试验越来越难, 但是不能重复的试验就备受争议。
数据分析项目也是这样, 你的研究结果, 一定要能够被第三方研究者所重复, 要尽可能地提供详尽的代码和数据使得别人能够重复研究。
§20.6所述的“文学式编程”是一类详尽记录操作过程和代码、结果的工具。
如果使用R作为计算工具,
为了结果可重复,
还应该记录下研究所用的操作系统、R版本、调用的扩展包版本。
devtools::session_info()可以显示这些信息:
R扩展包renv支持给每个研究项目设置私有的扩展包集合, 减轻了使用不同R扩展包版本的麻烦, 见§1.4.6的说明。
为了谨慎起见, 可以将研究项目(包括数据、代码、分析报告、计算结果)复制到一个虚拟机中, 在虚拟机中重复整个计算过程, 然后将虚拟机整体备份。 这样可以保证在操作系统、R软件、R扩展包升级或迁移后, 仍可以重现原来的研究结果。
20.2 备份
数据科学研究人员的工作成果就保存在源程序代码、整理好的数据、研究报告中。 如果不注意对这些成果定期备份, 一旦发生硬件故障、软件崩溃, 就不得不依赖于一些数据恢复工具, 而这不一定有效。
现在存储资源十分便宜, 所以备份只是一个好的习惯, 没有实际操作的困难。 常用的备份方式如:
- 使用闪存盘或者移动硬盘定期复制;
- 使用公开或私有的网盘服务,如百度网盘;
- 使用网络存储装置,或者自己架设FTP服务器用来上传备份;
- 使用github、git等源代码控制软件对源文件进行增量备份,等等。
如果使用MS Windows系统, 备份某个子目录到闪存盘的典型命令行命令如:
xcopy d:\proj G:\proj /E/D/R/Y其中d:\proj是要备份的子目录,
G:是闪存盘的驱动器。
xcopy命令的好处是可以备份下级子目录,
而且可以要求仅复制有更新的文件而自动跳过没有变化的文件。
可以将这样的命令保存为一个backup.bat文件,
放在桌面上双击就可以执行备份任务。
20.3 源代码管理
源代码管理软件可以跟踪记录源文件的每一个更改, 必要时回退到某一个时间节点的状态, 在开发的软件系统达到一定成熟度后进行“快照”, 发布一个可用的软件, 然后再继续改进。 另一个主要功能时在软件开发团队内进行协作, 允许将不同程序员独立进行某个模块的开发并上传到团队公共空间, 也可以让不同程序员对同一源文件进行更改。 还有一些错误列表、待完成工作等功能。
一个有代表性的源代码管理软件是github网站服务。 用户或者企业也可以架设内部的git服务器。
对于只有一个人的小规模开发项目,
也可以不使用这些专用软件,
而是定期将源文件复制为加日期标签的备份,
如mysrc-2023-04-14.R。
20.4 单元测试
数据科学研究项目会涉及大量代码编程, 如果使用了特殊的新算法, 就需要确保新算法的程序实现能在各种情况下正常工作。 应采用模块化程序设计思想, 将复杂任务分解为许多较简单的模块, 以R函数的形式实现。 为了保证结果正确, 应对每个模块进行多种测试, 确保各种输入产生的输出符合该模块的目标要求。 R的testthat扩展包和RUnit扩展包可以帮助管理这些测试代码, 可以批量执行测试并汇总测试结果。
20.5 阶段任务管理
一个研究任务通常可以分解为若干个步骤, 这些步骤有的有依赖关系, 需要按一定次序执行, 有的则可以并行执行。 例如, 步骤A是数据输入和清理, 步骤B是数据筛选和变换, 步骤C1是用逻辑斯谛回归建模, 步骤C2是用随机森林建模, 步骤D是比较两种建模结果并做出生成结果报告。 这些步骤都应该写成R函数形式。 对于较大规模的数据或者比较复杂的计算密集型算法, 每个步骤的计算运行时间可能会很长, 比如, 几分钟、几小时甚至几天。 需要进行适当的管理, 避免不必要的重复运行。 但是, 如果某个数据或程序的修改使得后续步骤结果过时, 就必须重新执行后续步骤, 否则整个项目结果就处于错误的状态, 称为不同步的状态。 比如, 步骤C2的参数进行了调整, 则步骤A、B、C1不需要重复执行, 但是步骤D就需要重新执行。
对于比较简单的研究任务, 代码和研究笔记(或研究报告)都可以写在一个Quarto文件中, Quarto支持代码段执行结果的缓存, 使得已经运行过的程序段除非程序被修改或者依赖的输入被修改都不必重复运行, 也能够规定不同步骤之间的依赖关系,见22.14。
对于更一般的研究任务, 应该使用一个依赖关系分析和控制执行软件来管理各个步骤的执行, 使得整个项目处于同步状态。 这样软件的典型代表是用于软件编译管理的make软件, make软件根据软件开发项目规定的目标和源文件的依赖关系, 有选择地仅编译有更新的源文件。 R的targets扩展包可以很好地管理用R作为主要计算软件的数据分析项目的各个步骤的同步执行。
下面举一个简单例子演示target的使用。
设输入数据文件为heart.csv,
包含了若干病人的一些指标和有误心脏病(AHD)的标签。
要分别用逻辑斯谛回归和随机森林方法进行拟合比较。
设项目的R/目录中包含如下的各个步骤的函数:
get_data <- function(infile){
read_csv(infile) |>
select(-`...1`) |>
mutate(
AHD = ifelse(AHD == "Yes", 1, 0) ) |>
na.omit()
}
fit_logistic_model <- function(data){
glm(AHD ~ .,
family = binomial,
data = data) |>
fitted() |>
(\(prob) ifelse(prob > 0.5, 1, 0))()
}
fit_rf_model <- function(data){
data |>
mutate(AHD = factor(AHD)) |>
randomForest(
AHD ~ .,
data = _) |> predict()
}
show_summary <- function(
data, logistic_model, rf_model){
cat("Logistic回归结果:\n")
table(data$AHD, logistic_model)
cat("随机森林结果:\n")
table(data$AHD, rf_model)
}注意这些函数都是指定输入, 以函数的返回值为输出, 不需要人为地调用并保存函数结果, targets包会管理这些调用和结果存储问题。
在项目目录中包含如下的_targets.R文件用于管理设置:
# _targets.R
library(targets)
source("R/functions.R")
tar_option_set(packages = c(
"tidyverse", "randomForest"))
list(
tar_target(file, "heart.csv", format = "file"),
tar_target(data, get_data(file)),
tar_target(logistic_model, fit_logistic_model(data)),
tar_target(rf_model, fit_rf_model(data)),
tar_target(summary, show_summary(
data, logistic_model, rf_model))
)在_targets.R文件中用source()载入了各个数据分析步骤对应的函数的源程序文件,
用tar_option_set()设置了一些选项,
比如要提前载入的R扩展包。
在这个文件末尾,
用tar_target()设置了每一个步骤(目标,target)。
比如,
名称为file的目标,
仅仅是说明了file目标依赖于heart.csv这个文件,
如果这个文件更改了,
则依赖于file目标的其它步骤也需要重新运行。
名为data的目标,则需要针对file目标调用get_data()函数,
结果自动保存,
并可以作为logistic_model步骤和rf_model步骤的输入。
最后一个目标名为summary。
用tar_manifest()可以在实际执行这些分析步骤之前,
罗列出各个目标(步骤):
> tar_manifest(fields = all_of("command"))
# A tibble: 5 × 2
name command
<chr> <chr>
1 file "\"heart.csv\""
2 data "get_data(file)"
3 logistic_model "fit_logistic_model(data)"
4 rf_model "fit_rf_model(data)"
5 summary "show_summary(data, logistic_model, rf_model)"用tar_visnetwork()可以用图形显示各个目标之间的关系,
见图20.1。
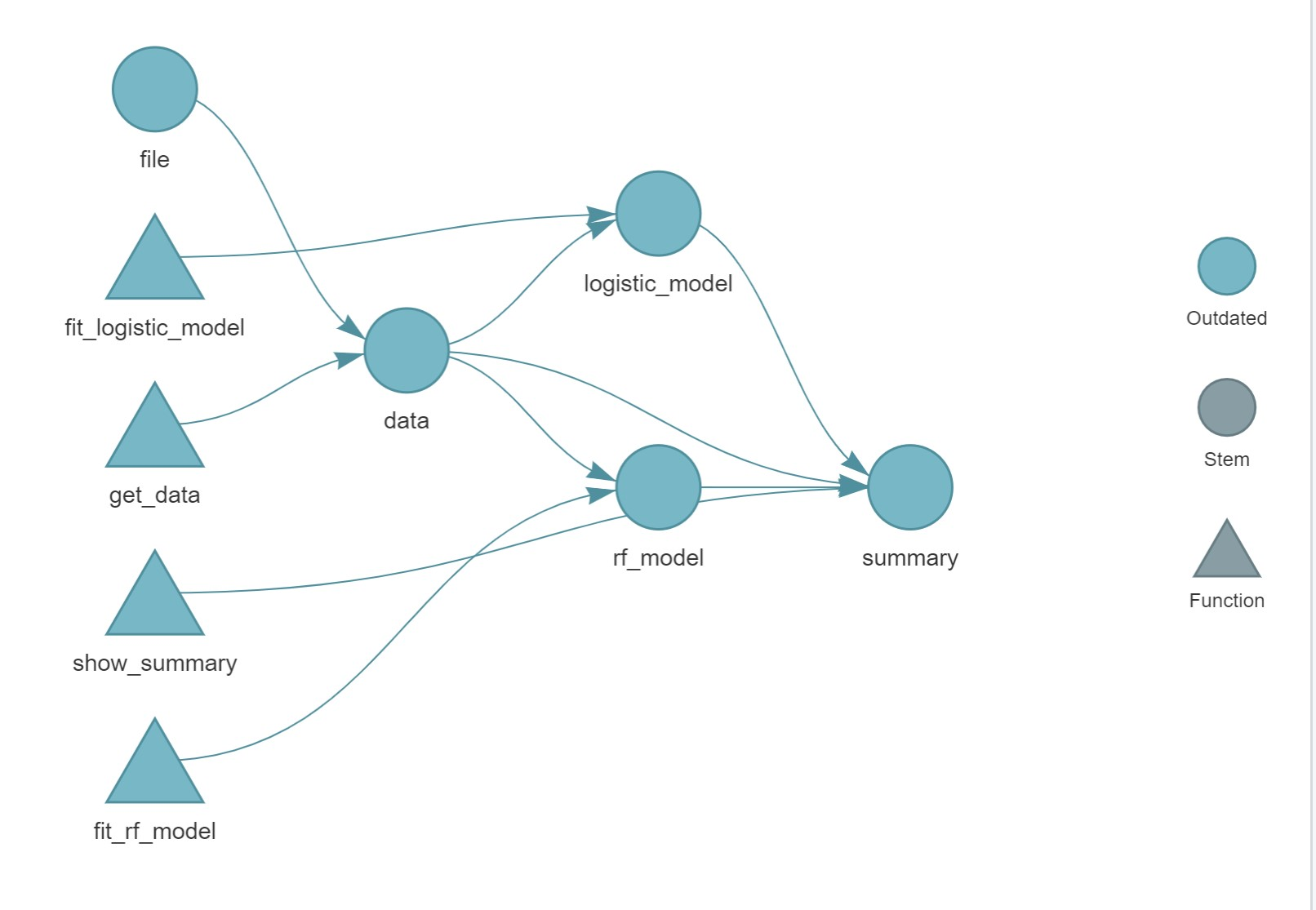
图20.1: 各个步骤之间的关系,未执行时
在图20.1中, 圆形代表一个节点(目标), 三角形代表一个处理步骤(Function), 用Outdated对应的颜色, 代表某一个目标尚未生成或者生成后其依赖的目标或函数已经更新, 需要重新生成。
用tar_make()执行所有步骤。
如果某些目标已经是最新的,
则相应的步骤不会执行。
如(输出信息有删减):
• start target file
• built target file [0.9 seconds]
• start target data
• built target data [0.25 seconds]
• start target logistic_model
• built target logistic_model [0.01 seconds]
• start target rf_model
Logistic回归结果:
• built target rf_model [0.12 seconds]
随机森林结果:
• start target summary
• built target summary [0 seconds]
• end pipeline [1.44 seconds]这时发现show_summary()函数定义有小错误,
不能显示两个模型的结果。
将该函数修改如下:
show_summary <- function(
data, logistic_model, rf_model){
cat("Logistic回归结果:\n")
table(data$AHD, logistic_model) |>
print()
cat("随机森林结果:\n")
table(data$AHD, rf_model) |>
print()
}再用tar_visnetwork()作网络图显示,
见图20.2。
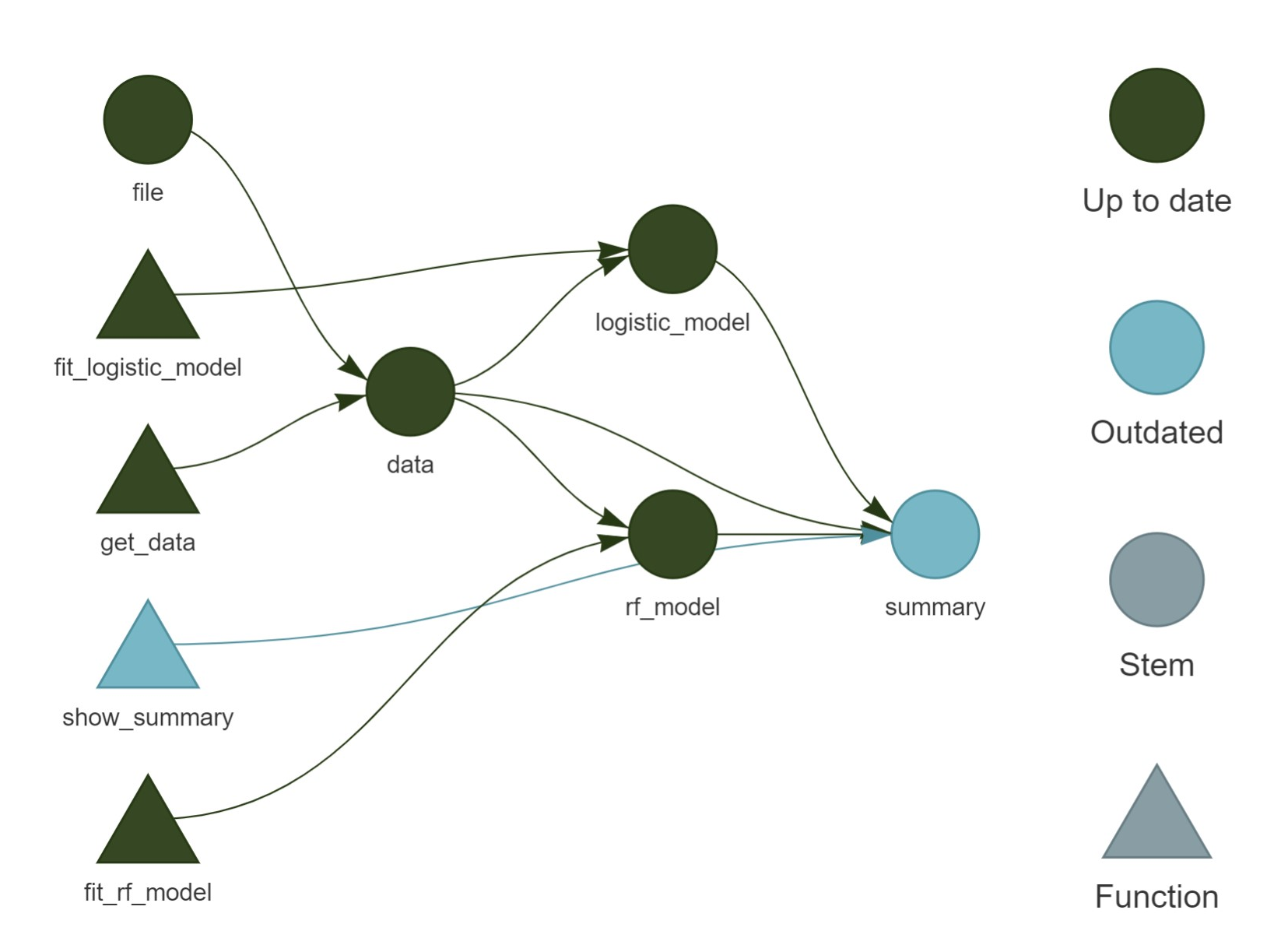
图20.2: 各个步骤之间的关系,仅summary目标过时
图20.2,
多个节点和函数已经是“Up to date”状态,
只有节点summary因为其依赖的函数show_summary被修改而呈现出过时状态。
重新运行tar_make(),
这时将仅运行show_summary函数:
✔ skip target file
✔ skip target data
✔ skip target logistic_model
✔ skip target rf_model
• start target summary
Logistic回归结果:
logistic_model
0 1
0 146 14
1 27 110
随机森林结果:
rf_model
0 1
0 138 22
1 29 108
• built target summary [0 seconds]
• end pipeline [1.01 seconds]这时再显示各步骤的网络图, 就都是“Up to date”状态了, 见图20.3。
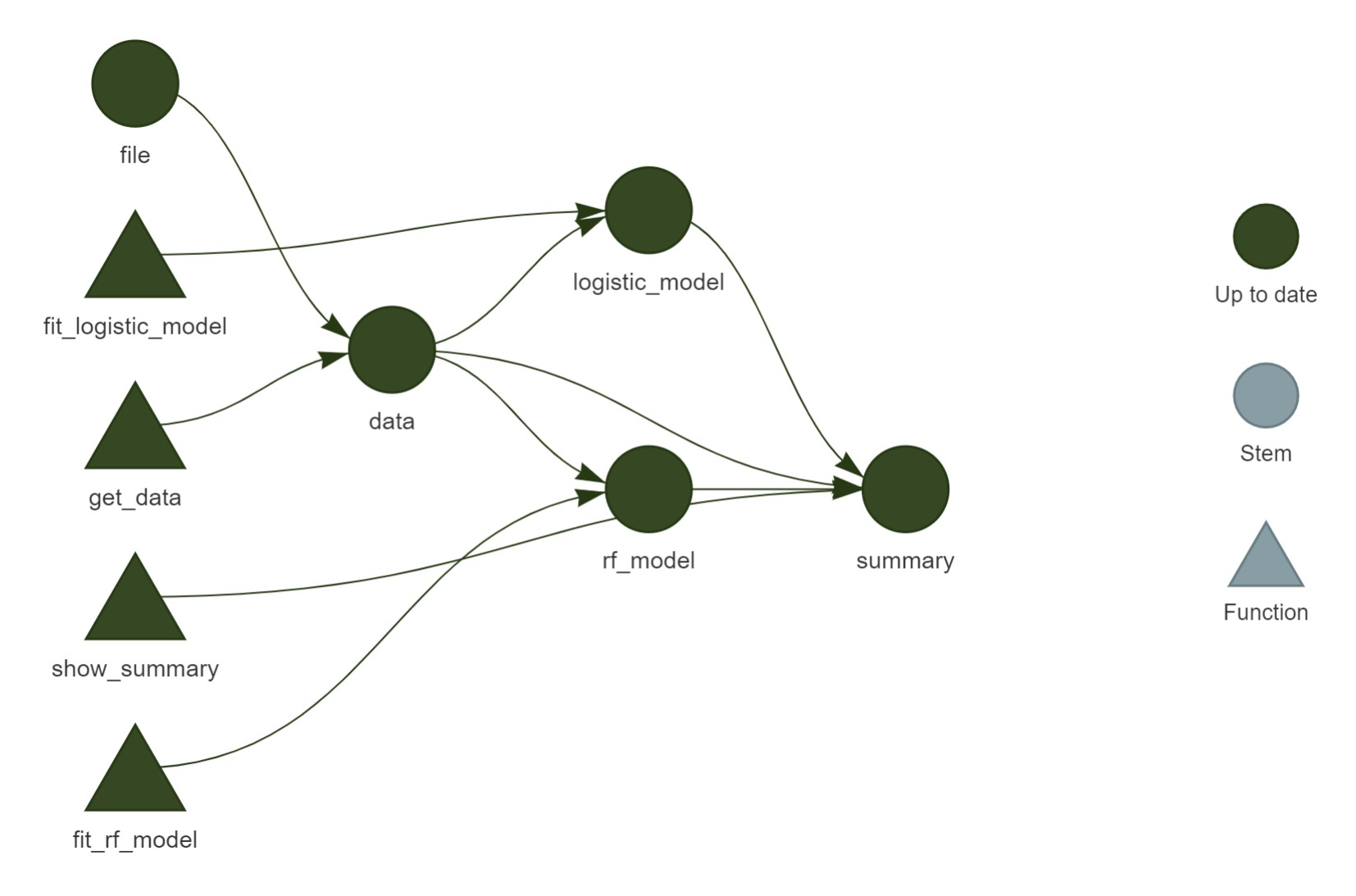
图20.3: 各个步骤之间的关系,全都同步
如果原始数据文件被修改了, targets也能发现这些修改, 这时所有的目标都需要重新计算。
20.6 文学式编程
一个统计或数据分析的科研项目, 都会产生一个或多个研究报告。 因为使用统计与数据分析不可避免地有很多计算涉及在内, 这里假设使用R软件做了计算。 科研是一个不断改进的过程, 所以每一次重新做了计算, 研究报告中的汇总表格、图形都要更新。 这样的任务比较繁琐, 也容易出错。
“文学式编程”(literate programming, (Knuth 1984))是这样一种思想, 把撰写报告与计算程序有机地结合在一起, 用一个源文件既包含报告内容, 又包含计算程序。 每次产生研究报告时, 先运行源文件中的计算程序得到计算结果, 这些结果包括文字性内容与图形, 然后利用适当软件自动地把这些原始文字、计算结果组合成最终的报告。 利用这样的思想, 可以自动生成重复的例行报告, 还可以作为“可重复科学研究”的载体。
这种做法也适用于将自己的科学研究过程保存并记录下来。 可以在这样的源文件中记录自己的想法, 将测试用的源程序保存在内, 可以记录成功的试验和失败的试验, 逐步地改进, 起到一个能进行科学计算的笔记本的功能。 将这样的思考过程记录下来并分享给别人, 也能帮助别人了解你的研究过程。 注意, 失败的研究过程也不要从中删除, 而是说明失败的原因, 这可以让自己和别的读者避免类似的错误。
上述的源文件一般是文本文件, 格式可以是Markdown格式, 也可以是LaTeX、Jupyter笔记本等许多格式。 R的knitr、rmarkdown、bookdown等扩展包就是用来支持这样的编程思想。 因为这些包主要与R挂钩, 不利用推广到其它程序语言用户, 所以RStudio的团队开发了开源软件Quarto, 可以将含有源程序的Markdown格式转换为各种包含程序和结果的各种输出格式。
Markdown是一种很简单的文本文件格式, 通常保存为.md扩展名, 利用Quarto支持的版本保存为.qmd扩展名。
Markdown文件里面有一些简单的格式标注方法, 比如两个星号之间的文字会转化为斜体, 缩进四个空格或一个制表符的内容会看成代码。 从markdown格式比较适合转换为html(网页)格式, 也可以转换为MS Word的docx格式, 通过LaTeX编译器可以转换为PDF格式, 也可以将docx转存为PDF格式, 或者用输出到PDF文件的打印机将网页格式转换为PDF格式。
Jupyter笔记本也是当前使用很多的一种包含文字说明、程序、结果的文件格式,
扩展名为.ipynb,
其主要格式也是markdown,
目前支持Python、Julia、R等程序语言。
Quarto软件可以将这样的笔记本文件转换为各种输出格式。
LaTeX是一个文档排版系统, 功能强大,结果美观, 设计合理。 缺点是需要学习类似于HTML的另一种语言。 LaTeX源文件主要是编译为PDF。
R扩展包knitr支持在Markdown格式、LaTeX格式等类型的文件中插入R代码, 经过转换, 文中的R代码可以变成代码的结果文字、表格、图形, 与原有报告文字有机地结合在一起。 Jupyter笔记本软件与Quarto软件配合也能实现类似功能。
插入了R代码的markdowng格式的文件一般以.qmd为扩展名,
R的knitr包与Quarto软件一起为.qmd提供了支持。
在RStudio中对编辑、转换quarto格式有很好的支持。
Quarto软件也支持生成学术类型的图书、论文, 公式、定理可以自动编号并支持文献、公式、定理、图表、章节的引用和链接, 支持生成PDF、多文件互相链接的HTML、Word等输出。
统计数据分析、数据科学的研究报告和论文,通常含有如下的内容:
- 说明文字;
- 表格、图形;
- 分析源代码,以及运行结果;
- 数学公式。
虽然我们可以用Word、LaTeX、Jupyter笔记本完成这些功能, 但各自有其缺点:
- Word有很好的排版功能, 容易学习和使用, 但是数学公式的输入依靠鼠标菜单, 速度比较慢, 程序结果只能复制粘贴到文档内, 重新运行程序后必须重新复制粘贴结果;
- LaTeX学习起来比较困难, 数学公式能力强, 特别适用于科技论文、报告、书籍, 但是程序结果的使用比Word还麻烦;
- Jupyter笔记本对源程序和程序结果支持很好, 可以使用LaTeX格式的数学公式, 但是对写作科学论文用的公式编号、图表编号、引用链接等支持不够好。 与Quarto软件配合可以弥补这些缺点。
所以, 有写科技论文、报告要求的读者, 应该学习使用Quarto软件。
下面两章先介绍基础的markdown格式, 这是在.qmd文件和Jupyter笔记本文件中文字部分使用的基本格式, 然后介绍Quarto对markdown的补充。 参考:
利用.qmd格式、Jupyter笔记本格式和Quarto软件可以执行如下的任务:
- 将单一的
.qmd文件或者.ipynb文件编译为不同的格式,如:- HTML;
- PDF;
- MS Word。
- 在RStudio软件内制作笔记本文档,可以在其中包含说明文字与R代码, 可以在笔记本文档内交互地运行R代码并能将结果交互地显示在笔记本内。
- 生成演示幻灯片,可以是基于HTML5的,也可以是基于LaTeX beamer扩展包的, 或者MS Powerpoint。
- 编写多章节组成的书籍。
- 编写期刊论文。
- 制作网站或者博客。
- 制作商业智能仪表盘(dashboards),即数据可视化展示。