15 统计计算
这一部分介绍如何靠自己编写Julia程序进行定制化的统计计算。 从自己编写程序作统计计算的角度简单介绍Julia中与统计计算编程有关的功能, 如向量、矩阵计算,最优化,随机模拟,并行计算等。
15.1 介绍
Julia比较适合用作数值计算, 编程既有Python、R、Matlab这样的语言的简洁, 又有C++这样的编译语言的运行效率。 统计数据分析、作图需要用到许多复杂的算法, 有些算法耗时很多, 比如MCMC等。 大量数据的分析、计算、测试都需要易用的编程和高效的运行效率, Julia在这两点都很适合。
Julia用作统计数据分析, 缺点是其问世时间还比较短, 许多统计模型还没有现成的软件包。 但是, 基本的数据管理、作图、统计分布、随机模拟、最优化等统计计算必须的功能已经很完善, 所以能够自己编写的统计计算任务很适合用Julia编写。
Julia目前的版本是1.7.3。
15.2 向量和矩阵
Julia的统计功能还不够丰富, 许多统计任务可以通过R语言来完成。 Julia的优点是其运算速度快, 特别是在对向量和矩阵循环时效率很高, 这正是R语言和Python语言的弱项。 所以不需要调用很多现成的统计方法软件包的统计计算编程任务可以用Julia语言完成。
这里讲一些统计计算中常用的编程技巧, 统计计算中常用的一些功能, 提高运行效率的方法等。 首先介绍一些向量和矩阵计算有关知识。
15.2.1 向量和矩阵计算
向量是一维数组,
矩阵是二维数组。
数组元素之间的四则运算,
只要使用加点格式,
如x ./ y表示两个数组对应元素之间的除法。
如果函数f(x)可以用于标量,
则f.(x)可以用于数组每个元素。
但是,目前用显式循环而不是向量化写法的程序效率更高。
向量和矩阵运算的许多函数由标准库中的LinearAlgebra包提供。
两个向量x和y的内积用dot(x,y)计算。
两个矩阵A和B的矩阵乘法用A * B表示,
矩阵A的共轭转置用A'表示,
转置用A.'表示。
[A B C]表示三个矩阵横向合并,
[A;B;C]表示三个矩阵纵向合并。
若x是向量,
diagm(x)返回以x为主对角线元素的对角阵,
而Diagonal(x)返回带有特殊标志的对角阵。
inv(A)表示\(A^{-1}\)。
A \ B表示求解线性方程组A x = B。
当\(A\)的行数超过列数时,
求最小二乘解。
当\(A\)的列数超过行数时,
可能有无穷多解,
这时返回其中长度最小的解。
统计计算中用到许多矩阵计算,
高效、精确的矩阵计算常常需要通过矩阵的三角分解、正交-三角分解等实现。
当\(A\)为方阵时,
lu(A)将矩阵\(A\)分解成\(A = PLU\)形式,
其中\(P\)是置换阵(permutation matrix),
\(L\)是下三角阵,
\(U\)是上三角阵。
设结果为res,
则三个部分分别用res.P, res.L, res.U访问。
置换阵res.P还可以用一维数组res.p表示。
如
A1 = [1 -2 2; 1 -1 2; -1 1 1]3×3 Array{Int64,2}:
1 -2 2
1 -1 2
-1 1 1using LinearAlgebra
res1 = LinearAlgebra.lu(A1)
res1.L3×3 Array{Float64,2}:
1.0 0.0 0.0
1.0 1.0 0.0
-1.0 -1.0 1.0res1.U3×3 Array{Float64,2}:
1.0 -2.0 2.0
0.0 1.0 0.0
0.0 0.0 3.0res1.P3×3 Array{Float64,2}:
1.0 0.0 0.0
0.0 1.0 0.0
0.0 0.0 1.0res1.p 3-element Array{Int64,1}:
1
2
3对矩阵\(A\),
qr(A)可以做QR分解\(A=QR\),
qr(A, true)可以做带枢轴量的QR分解\(A=PQR\),
如果结果为res,
则各个部分用res.P, res.Q, res.R访问,
置换阵res.P还可以用res.p,一个一维向量表示。
用eigen(A)可以求方阵A的特征值分解,
如果结果为res,则res.values为特征值,是复数向量;
res.vectors返回各列为特征向量的矩阵,
inv(res), det(res), isposdef(res)可以从分解结果中提取信息。
如
res2 = eigen(A1)
res2.values3-element Array{Complex{Float64},1}:
-0.2873715369435107 - 1.3499963980036567im
-0.2873715369435107 + 1.3499963980036567im
1.5747430738870216 + 0.0imres2.vectors3×3 Array{Complex{Float64},2}:
0.783249-0.0im 0.783249+0.0im 0.237883+0.0im
0.493483+0.303862im 0.493483-0.303862im 0.651777+0.0im
-0.0106833-0.22483im -0.0106833+0.22483im 0.720138+0.0im对称阵(或厄米特阵)的特征值都是实数,
其计算更快。
因为数值误差的关系,
有些对称阵可能保存起来已经不对称,
这时可以用Symmetric(A)将A转换为对称阵,
用Hermitian(A)将A转换为厄米特阵。
15.2.2 向量化与循环
Julia中, 显式循环一般比用向量化的计算效率更高。 这是因为向量化运算需要考虑到动态类型问题, 而显示循环则直接访问元素。
考虑下面的例子:
function vecadd1(a,b,c,N)
for i = 1:N
c = a + b
end
end
function vecadd2(a,b,c,N)
for i = 1:N
c .= a .+ b
end
end
function vecadd3(a,b,c,N)
for i = 1:N, j = 1:length(c)
c[j] = a[j] + b[j]
end
end以上的三个函数都是将向量a与向量b相加赋给向量c, 并重复N次。 第一个版本用了向量化的做法, 第二个版本用了加点格式的向量化做法, 第三个版本是显式循环。 下面比较这三个版本的运行效率:
A = rand(2); B = rand(2); C = zeros(2);
vecadd1(A,B,C,10);
vecadd2(A,B,C,10);
vecadd3(A,B,C,10);using BenchmarkTools
@btime vecadd1(A,B,C,10);
@btime vecadd2(A,B,C,10);
@btime vecadd3(A,B,C,10);
## 293.798 ns (10 allocations: 800 bytes)
## 50.663 ns (0 allocations: 0 bytes)
## 34.340 ns (0 allocations: 0 bytes)在上述演示程序中, 为了避免函数编译的影响, 先用较小的N将三个函数运行了一遍。
可以看出,
第一个版本效率最差,
这是因为计算a + b时需要动态分配结果的内存,
赋值给c也不是存入到c的已有内存而是重新绑定c。
第二个版本用了加点形式,
比第一个版本效率要高,
但是也有动态数据类型的开销。
第三个版本则完全是在访问a, b, c已有内存,
没有做任何的内存重分配或者重绑定,
所以效率最高。
15.3 高精度浮点数和整数
科学计算使用的浮点数一般是双精度浮点数, 在Julia语言中为Float64类型, 一般有16-17位有效数字。 许多科学计算需要更多的有效位, 否则会有较大的精度损失, 比如, 计算圆周率到40位有效数字。
在Julia中用big(x)将浮点数x转换为BigFloat类型后返回,
将整数x转换为BigInt后返回。
BigFloat默认有256个二进制位有效数字,
约位77个十进制有效数字,
可以设定存储的有效数字位数。
BigInt和BigFloat实现了任意精度数字存储和计算功能,
这些类型参与的运算结果也会变成任意精度结果,
所有的数学函数也支持这两个类型。
BigFloat(x; precision=p)指定以二进制位数为单位的存储精度,
默认有256个二进制有效数字。
也可以写成big"123.456"这样的格式。
BigInt(x)将整数x转换为高精度整数类型返回,
也可以写成如big"123"这样的格式。
BigInt可以存储任意多位数的整数,
没有位数限制。
要从基础的地方使用big()转换,或使用big"..."格式,
如:
big(0.1)
## 0.1000000000000000055511151231257827021181583404541015625
big(1)/10
## 0.1000000000000000000000000000000000000000000000000000000000000000000000000000002
big"0.1"
## 0.1000000000000000000000000000000000000000000000000000000000000000000000000000002可见big(0.1)有很大误差,
这是因为浮点数0.1原来是Float64类型,
在存储时仅有约16位有效数字,
所以转换为高精度浮点数后仍有很大误差;
而big(1)/10则可以存储\(0.1\)的更精确的值。
big"0.1"则不是将Float64类型的0.1转换为高精度,
而是直接用高精度储存0.1。
15.4 计算函数
15.4.1 排列组合
Base库和Julia扩展包Combinatorics提供了排列组合有关的函数。
factorial(n)计算\(n!\),factorial(big(n))以BigInt格式返回\(n!\)的值。factorial(n, k)计算\(\frac{n!}{k!}\), 这是从\(n\)个编码元素中有序无放回地取出\(n-k\)个的所有取法的数值。 用`factorial(big(n), k)$避免溢出。binomial(n,k)计算组合数\(\binom{n}{k} = \frac{n!}{k!(n-k)!}\)。 用`binomial(big(n), k)$避免溢出。Combinatorics.multinomial(k...)计算多项组合数, 如multinomial(k1, k2, k3)计算\(\frac{(k_1 + k_2 + k_3)!}{k_1! k_2! k_3!}\)。Combinatorics.combinations(a, n)穷举序列a中无放回取出n个的所有不计次序的组合, 结果为一个迭代器。Combinatorics.combinations(a)则对所有的取出个数n都列出组合。Combinatorics.permutations(a)返回序列a的所有的排列, 按字典序排序。
15.5 随机数发生器
15.5.1 标准库的随机数
using Random在统计建模中经常需要用到各种概率分布, Julia的Distributions包提供了常见的概率分布的有关的函数, 包括各种分布的随机数发生器。
Julia语言的标准库Random包提供了rand函数和randn等随机数函数。
Julia语言默认的随机数发生器是Matsumoto和Nishimura开发的Mersenne Twister发生器, 有一个全局的状态; 可以从不同种子出发制作多个发生器, 产生多个随机数流, 但是文档中没有明确如何设置种子使得同一类发生器的不同流如何避免产生有重叠的序列。
Random.seed!(seed)或Random.seed!(rng, seed)可以设置种子。
为了能够保证模拟的结果可重复,
需要在模拟开始之前设置种子。
但是,随着Julia版本的升级,
随机数种子和随机数生成器可能会改变,
如果特别需要模拟研究结果完全可重复,
可以将生成的模拟样本都备份保存下来。
无自变量的rand()返回一个\([0,1]\)均匀分布随机数:
Random.seed!(101)
rand(), rand()
## (0.7168598128347071, 0.17802810731801244)rand(n)返回n个标准均匀分布U(0,1)随机数,
类型是Float64的一维数组:
Random.seed!(101)
rand(5)5-element Vector{Float64}:
0.7168598128347071
0.17802810731801244
0.30804490514713656
0.5374016335104801
0.9344914085792877可以看出,因为使用了Random.seed!设置相同的种子,
所以获得的5个随机数中的前两个与前面例子两次rand()调用获得的两个数是相同的。
从同一种子出发产生的同类随机数称为一个“流”(stream)。
也可以直接生成随机数组成的矩阵,称为随机矩阵, 如:
Random.seed!(101)
rand(2, 3)2×3 Matrix{Float64}:
0.71686 0.308045 0.934491
0.178028 0.537402 0.782002randn(n)和randn()产生标准正态分布的随机数:
Random.seed!(102)
randn(), randn()
## (0.9369520636583538, 0.9991544105213579)Random.seed!(102)
randn(5)5-element Vector{Float64}:
0.9369520636583538
0.9991544105213579
-0.23554568311345525
-0.8649103565808351
-1.1206130574218711randn(2, 3)2×3 Matrix{Float64}:
-0.676811 -0.140055 1.31825
2.28594 0.437692 -1.3841215.5.2 Distributions库提供的随机数发生器
加载Distributions包后可以生成其它分布的随机数,
为Base的rand函数增加了方法,
还提供了各种与分布的有关函数。
产生随机数的函数调用格式为
rand(distribution, n)或rand(distribution),
其中distribution是一个分布,用函数调用表示,
比如标准正态分布用Normal()表示,\(\text{N}(10, 2^2)\)用Normal(10,2)表示。
用Random.seed!(k)或Random.seed!(rng, k)设定一个随机数种子序号,
这样可以在模拟时获得可重复的结果。
比如,生成100个Possion(2)分布随机数:
using Random, Distributions
using StatsBase, DataFrames
Random.seed!(101)
y = rand(Poisson(2), 100);结果是Int64型的一维数组。样本的频数统计:
tab11 = DataFrame(
y = minimum(y):maximum(y),
count = StatsBase.counts(y))6×2 DataFrame
Row │ y count
│ Int64 Int64
─────┼──────────────
1 │ 0 10
2 │ 1 30
3 │ 2 28
4 │ 3 25
5 │ 4 5
6 │ 5 2作其离散分布条形图:
using CairoMakie
CairoMakie.activate!()
using AlgebraOfGraphicsplt = data((;y=y)) * mapping(:y) * frequency()
draw(plt)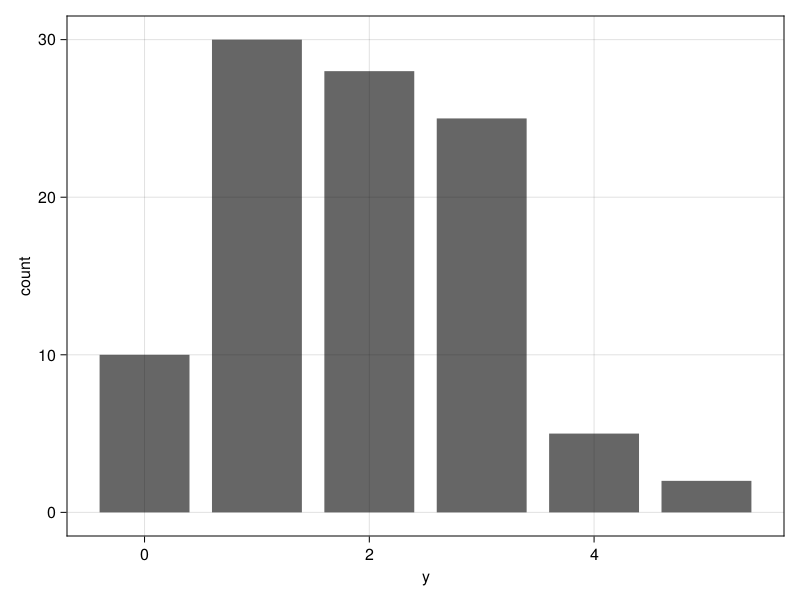
也可以从已有的汇总表格作图:
plt = data(tab11) * mapping(:y, :count) * visual(BarPlot)
draw(plt)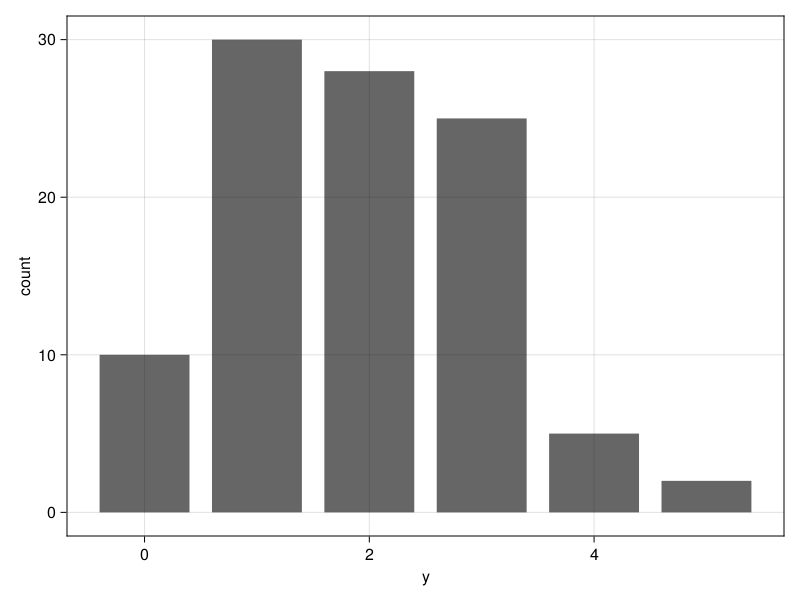
如下程序生成1000个N(\(10, 2^2\))随机数, 并作分布直方图:
Random.seed!(101)
y = rand(Normal(10, 2), 1000);
plt = data((; y=y)) * mapping(:y) * histogram(bins=30)
draw(plt)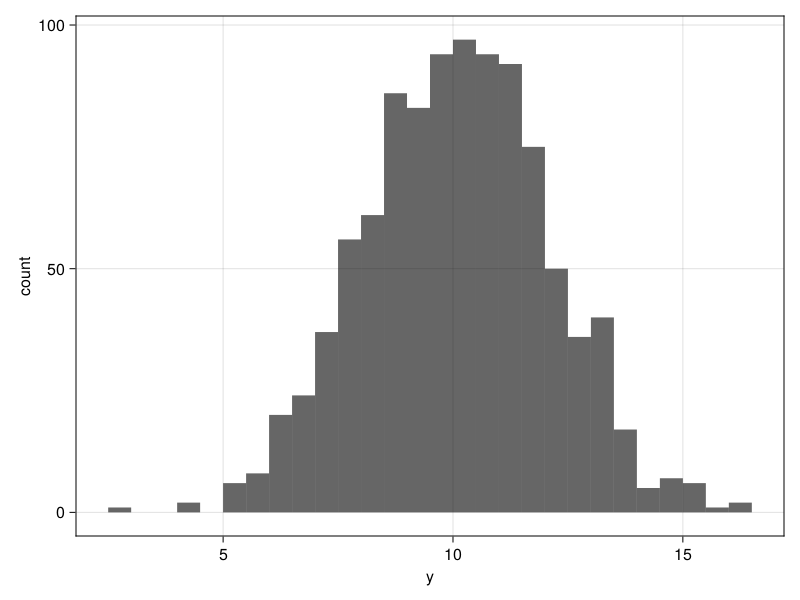
15.5.3 随机抽样
Base.rand(collection)函数可以从一个收集容器(collection)中等概率地随机抽取一个,如:
Random.seed!(101)
rand(1:5), rand(1:5)
## (4, 1)rand([2, 3, 5, 7]), rand([2, 3, 5, 7])
## (3, 5)rand("distibutions"), rand("distibutions")
## ('s', 'o')有放回等概重复抽样:
rand(1:5, 3)3-element Vector{Int64}:
2
4
1rand([2, 3, 5, 7], 3)3-element Vector{Int64}:
2
7
7string(rand("distibutions", 3)...)
## "oti"StatsBase.sample(x,n)函数可以从一列值x中随机有放回抽取n个值。
加replace=false作无放回抽样。
如
StatsBase.sample(1:10, 5, replace=false) |> show
## [7, 10, 2, 8, 4]在社会调查抽样中,
经常需要按不等权重抽样。
这时,可以增加一个权重向量。
权重向量的数据类型是AbstractWeights,
不需要总和等于1,
其总和会保存在变量中。
用Weights()函数将普通向量转换成权重向量。
如
StatsBase.sample(1:10,
StatsBase.Weights([ones(5); 4 .* ones(5)]),
5; replace=true) |> show
## [10, 9, 8, 6, 10]StatsBase中还有一些抽样函数,
包括sample, sample!, wsample, wsample!,
参见:
15.5.4 随机排列
Random.randperm(n)可以生成\(1:n\)的一个随机排列。
如:
using Random
Random.seed!(101)
randperm(4) |> show
## [2, 1, 4, 3]在试验设计中, 设因素A, B都有\(m\)个水平, 要进行完全试验, 要有\(m^2\)个组合。 如果希望仅进行\(m\)个试验, 但是A的所有水平都进行试验, B的所有水平都进行试验, 可以取\(1:m\)的一个随机排列作为要试验的\(m\)个方案的A水平号, 另外取\(1:m\)的一个随机排列作为要试验的\(m\)个方案的B水平号, 这样就达到了要求。 这个问题可以推广到\(n\)个因素的情形, 函数为:
function uniform_projection_plan(m=4, n=2)
perms = [randperm(m) for i=1:n]
[ [perms[i][j] for i=1:n] for j=1:m]
end
Random.seed!(101)
inds = uniform_projection_plan(4,2)4-element Vector{Vector{Int64}}:
[2, 2]
[1, 4]
[4, 3]
[3, 1]实际的设计方案也可以显示为:
A = zeros(Int, 4, 4)
for (i,j) in inds
A[i,j] = 1
end
A4×4 Matrix{Int64}:
0 0 0 1
0 1 0 0
1 0 0 0
0 0 1 0其中1表示有试验,0表示没有试验。
15.5.5 非均匀分布随机数生成
Distributions包提供了许多常见分布的随机变量的随机数函数。 如何生成一般的分布的随机变量?
如果\(X\)为连续型分布,分布函数为\(F(x)\), 则取\(U \sim \text{U}(0,1)\), \(X = F^{-1}(U)\)服从\(F(x)\)。 这种生成非均匀分布随机数的方法称为逆变换法。
例如,对\(0 \leq m \leq 1\), 三角形分布Tri(0,1,\(m\))的密度函数为 \[\begin{aligned} p(x) =& \begin{cases} \frac{2}{m} x, & 0<x \leq m \\ \frac{2}{1-m} (1-x), & m < x < 1 . \end{cases} \end{aligned}\] 密度函数的图像是以\([0,1]\)为底边, 以\((m, 2)\)为顶点的三角形。 分布函数为 \[\begin{aligned} F(x) =& \begin{cases} \frac{x^2}{m}, & 0<x \leq m \\ 1 - \frac{(1-x)^2}{1-m}, & m < x < 1 . \end{cases} \end{aligned}\] 分布函数的反函数为 \[\begin{aligned} F^{-1}(u) = \begin{cases} \sqrt{mu}, & 0< u \leq m \\ 1 - \sqrt{(1-m)(1-u)}, & m < u < 1 . \end{cases} \end{aligned}\] 所以若\(U \sim \text{U}(0,1)\), 则\(X = F^{-1}(U)\)服从三角形分布Tri(0,1,\(m\))。
生成三角形分布的随机数的函数如下:
function rand_tri(n, m)
Finv(u) = u < m ? sqrt(m*u) : 1 - sqrt((1-m)*(1-u))
Finv.(rand(n))
end
## 测试,估计期望
mean(rand_tri(1_000_000, 0.6))
## 0.5335009450490591期望的理论值为\(\frac{1+m}{3}=0.5333\)。
15.6 最优化与方程求根
统计计算的常用工具包括矩阵计算、随机模拟和最优化, 统计计算中许多问题都归结为一个最优化问题, 比如非线性回归、最大似然估计、惩罚最大似然估计等。 Julia提供了若干个优秀的最优化计算扩展包, 比如JuMP、 Optim、 Optimization、 NLopt、 Convex等扩展包。
JuMP是一个目标函数值域为一元的约束优化包, 实际是一个前端工具, 方便定义优化问题。
Optim是一个完全用Julia实现的无约束优化包。
Optimization也是一个前端工具,调用其它后台算法包求解。
NLopt是开源的优化包NLopt的Julia接口界面。
参考书:
Mykel J. Kochenderfer, Tim A. Wheeler(2019) Algorithms for Optimization, MIT Press.
15.6.1 Optim包
Optim包的好处是完全用Julia实现, 不像其它的最优化包那样需要依赖于其它的可能需要收费的、需要其它编译器的后端引擎。 这部分内容采用了Optim包文档中的例子。
参考:
15.6.1.1 多元函数优化
Optim包的optimize()函数类似于R的optim(),
可以用来求多元函数的无约束极值或矩形约束的极值,
一元函数区间内的极值,
复函数极值,
流形上的极值。
可用的优化方法包括:
NelderMead(),是不依赖梯度信息的单纯型方法,只需要目标函数本身;BFGS(),LBFGS(), 这是著名的拟牛顿法,LBFGS()是内存开销有限版本;ConjugateGradient(), 共轭梯度法;GradientDescent(), 最速下降法,还有MomentumGradientDescent(),AcceleratedGradientDescent();Newton(),牛顿法,需要梯度函数与海色阵函数,海色阵函数不可省略, 还有NewtonTrustRegion(),此方法克服了当函数不能用二次多项式近似时的困难;SimulatedAnnealing(),模拟退火法,用于求解全局最值, 只需要目标函数本身,速度慢。SAMIN(),ParticleSwarm()是类似方法;Fminbox(),矩形约束的优化;IPNewton()为非线性约束的内点法加牛顿法;Brent()和GoldenSection()为一元函数优化;- …………
用户可以提供梯度函数以及海色阵用来加速收敛。 结果是类似R的list类型的一个结构。
举例说明。
考虑二元函数
\(f(x, y) = (x - a)^2 + b (y - x^2)^2\)的最小值问题。
显然唯一的最小值点为\((a, a^2)\)。
用Optim的optimize()函数进行数值求解。
这个二元函数的最小值点在很长、很窄、底部平坦的山谷内,
对迭代算法来说有一定困难。
取\(a=1, b=100\),
最小值点在\((1,1)\)。
取初值为\((0,0)\)。
目标函数定义:
function rb(x::Vector{Float64})
return (1.0 - x[1])^2 + 100.0 * (x[2] - x[1]^2)^2;
end使用默认的设置进行优化:
using Optim
ores1 = optimize(rb, [0.0, 0.0])* Status: success
* Candidate solution
Final objective value: 3.525527e-09
* Found with
Algorithm: Nelder-Mead
* Convergence measures
√(Σ(yᵢ-ȳ)²)/n ≤ 1.0e-08
* Work counters
Seconds run: 0 (vs limit Inf)
Iterations: 60
f(x) calls: 117可以看出在没有选用具体优化方法的情况下用了Nelder-Mead方法,
迭代了60次。
optimize()的结果如果保存在res变量中,
可以用Optim.minimizer(res)获得最小值点(总是一个向量),
用Optim.minimum(res)获得最小值。
结果中还有用于检查是否收敛的输出,
详见Optim包的文档。
最小值点:
Optim.minimizer(ores1)2-element Vector{Float64}:
0.9999634355313174
0.9999315506115275改用BFGS方法,使用普通数值微分计算梯度:
ores1b = optimize(rb, [0.0, 0.0], BFGS())* Status: success
* Candidate solution
Final objective value: 5.471433e-17
* Found with
Algorithm: BFGS
* Convergence measures
|x - x'| = 3.47e-07 ≰ 0.0e+00
|x - x'|/|x'| = 3.47e-07 ≰ 0.0e+00
|f(x) - f(x')| = 6.59e-14 ≰ 0.0e+00
|f(x) - f(x')|/|f(x')| = 1.20e+03 ≰ 0.0e+00
|g(x)| = 2.33e-09 ≤ 1.0e-08
* Work counters
Seconds run: 0 (vs limit Inf)
Iterations: 16
f(x) calls: 53
∇f(x) calls: 53Optim.minimizer(ores1b)2-element Vector{Float64}:
0.9999999926033423
0.9999999852005355只迭代了16次,但是计算数值微分也会涉及到比较多的目标函数计算。 可以人为给出梯度函数:
function rb_grad!(G::Vector{Float64}, x::Vector{Float64})
G[1] = -2.0 * (1.0 - x[1]) - 400.0 * (x[2] - x[1]^2) * x[1]
G[2] = 200.0 * (x[2] - x[1]^2)
end
ores1c = optimize(rb, rb_grad!, [0.0, 0.0], BFGS()) * Status: success
* Candidate solution
Final objective value: 7.645684e-21
* Found with
Algorithm: BFGS
* Convergence measures
|x - x'| = 3.48e-07 ≰ 0.0e+00
|x - x'|/|x'| = 3.48e-07 ≰ 0.0e+00
|f(x) - f(x')| = 6.91e-14 ≰ 0.0e+00
|f(x) - f(x')|/|f(x')| = 9.03e+06 ≰ 0.0e+00
|g(x)| = 2.32e-09 ≤ 1.0e-08
* Work counters
Seconds run: 0 (vs limit Inf)
Iterations: 16
f(x) calls: 53
∇f(x) calls: 53Optim.minimizer(ores1c)2-element Vector{Float64}:
0.9999999999373614
0.999999999868622还可以由用户提供一个海色阵函数, 这时方法为牛顿法,调用如
optimize(rb, rb_grad!, rb_Hess!, [0.0, 0.0])optimize()不会用数值微分法计算海色阵,
因为两次数值微分造成很大误差。
如果目标函数完全用Julia编写并且不调用C代码和Fortran代码,
则目标函数的梯度函数和海色阵函数可以自动微分方法获得精确函数,
这需要函数的自变量支持一般的AbstractReal类型,
不能声明为一个具体的类型。
这在背后利用了ForwardDiff包计算精确一阶和二阶微分。
如
function rbgen(x)
return (1.0 - x[1])^2 + 100.0 * (x[2] - x[1]^2)^2;
end
ores1d = optimize(rbgen, [0.0, 0.0], Newton(); autodiff = :forward)* Status: success
* Candidate solution
Final objective value: 3.081488e-31
* Found with
Algorithm: Newton's Method
* Convergence measures
|x - x'| = 3.06e-09 ≰ 0.0e+00
|x - x'|/|x'| = 3.06e-09 ≰ 0.0e+00
|f(x) - f(x')| = 9.34e-18 ≰ 0.0e+00
|f(x) - f(x')|/|f(x')| = 3.03e+13 ≰ 0.0e+00
|g(x)| = 1.11e-15 ≤ 1.0e-08
* Work counters
Seconds run: 0 (vs limit Inf)
Iterations: 14
f(x) calls: 44
∇f(x) calls: 44
∇²f(x) calls: 14Optim.minimizer(ores1d)2-element Vector{Float64}:
0.9999999999999994
0.9999999999999989optimize()支持比较简单的矩形约束优化,
所谓矩形约束(box constraint),
是指每个坐标分量属于一个区间,
可以用Inf和-Inf表示无穷区间。
这种约束优化用的是简单的内点法。
例如,上面的例子函数本来是无约束的, 但是如果我们要求解在矩形\([1.25, \infty) \times [-2.1, \infty)\)中, 这个范围已经不包含全局最小值点。 约束优化程序如下:
lower = [1.25, -2.1]
upper = [Inf, Inf]
initial_x = [2.0, 2.0]
inner_optimizer = GradientDescent()
ores2 = optimize(rb, rb_grad!, lower, upper, initial_x,
Fminbox(inner_optimizer))* Status: success
* Candidate solution
Final objective value: 6.250240e-02
* Found with
Algorithm: Fminbox with Gradient Descent
* Convergence measures
|x - x'| = 0.00e+00 ≤ 0.0e+00
|x - x'|/|x'| = 0.00e+00 ≤ 0.0e+00
|f(x) - f(x')| = 0.00e+00 ≤ 0.0e+00
|f(x) - f(x')|/|f(x')| = 0.00e+00 ≤ 0.0e+00
|g(x)| = 3.10e-02 ≰ 1.0e-08
* Work counters
Seconds run: 0 (vs limit Inf)
Iterations: 12
f(x) calls: 258719
∇f(x) calls: 258719Optim.minimizer(ores2)2-element Vector{Float64}:
1.2500000000000002
1.5626548683420372可见结果在约束的左边界处达到。
控制迭代精度等选项,
可以使用optimize()的控制选项,如
optimize(rb, rb_grad!, [0.0, 0.0],
GradientDescent(),
Optim.Options(g_tol = 1e-12,
iterations = 10,
store_trace = true,
show_trace = false))* Status: failure (reached maximum number of iterations)
* Candidate solution
Final objective value: 3.959488e-01
* Found with
Algorithm: Gradient Descent
* Convergence measures
|x - x'| = 7.94e-03 ≰ 0.0e+00
|x - x'|/|x'| = 2.13e-02 ≰ 0.0e+00
|f(x) - f(x')| = 7.27e-03 ≰ 0.0e+00
|f(x) - f(x')|/|f(x')| = 1.84e-02 ≰ 0.0e+00
|g(x)| = 1.16e+00 ≰ 1.0e-12
* Work counters
Seconds run: 0 (vs limit Inf)
Iterations: 10
f(x) calls: 34
∇f(x) calls: 34此例因为设置了太小的迭代次数限制导致没有收敛。 实际上, 最速下降法迭代一万次也没有收敛。 这是因为最速下降法收敛速度慢, 而且目标函数也比较复杂。
15.6.1.2 一元函数优化
optimize()也可以对一个一元函数在给定的区间内求极值,
可用方法有Brent()和GoldenSection()。
比如函数 \[f(x) = 2x^2+3x+1 = 2 (x + \frac34)^2 - \frac18,\] 显然最小值点为\(-\frac34\), 最小值为\(-\frac18\)。 在区间\([-10, 10]\)内求最小值:
funi(x) = 2x^2 + 3x + 1
optimize(funi, -10, 10)Results of Optimization Algorithm
* Algorithm: Brent's Method
* Search Interval: [-10.000000, 10.000000]
* Minimizer: -7.500000e-01
* Minimum: -1.250000e-01
* Iterations: 5
* Convergence: max(|x - x_upper|, |x - x_lower|) <= 2*(1.5e-08*|x|+2.2e-16): true
* Objective Function Calls: 615.6.2 JuMP包
Optim包好处是没有对其它库的依赖, 缺点是能解决的优化问题的类型很少, 主要是无约束优化与最简单的约束优化。
JuMP包是Julia中优化问题建模的一个软件包, 调用一些开源或者商业化的最优化程序包的功能来求解, 所以能解决的优化问题类型很多, 但是其安装设置比较困难, 有些后端软件是收费软件。 涉及的优化问题类型包括线性规划, (混合)整数规划, 二阶锥规划, 半定规划, 非线性规划。
JuMP使用自动微分功能, 自动微分功能要求目标函数为Julia编写且不要求自变量为特定实数类型。 除非用户自己提供导数函数, 不能使用自动微分就不能使用JuMP。 JuMP主要针对值域为一元的目标函数的约束优化问题, 无约束优化使用JuMP没有优势。
JuMP可以看成是一个前端工具, 为了使用JuMP包, 需要安装JuMP包, 还要单独安装所需要用的求解包, 这些包有的需要调用二进制代码库, 好在Windows和OS X上有的库已经提供了编译好的包下载, Linux可以从源程序编译。
比如,GLPK提供了线性规划(LP)和混合整数线性规划(MILP)功能, 用
Pkg.add("GLPK")安装。
参考:
15.6.2.1 线性规划
这里举例说明用JuMP调用GLPK求解线性规划问题。 例子来自JuMP的文档。 考虑如下的线性规划问题: \[ \begin{aligned} & \max 5x + 3y \quad \text{s.t.}\\ & 0 \leq x \leq 2 \\ & 0 \leq y \leq 30 \\ & x + 5y \leq 3.0 \end{aligned} \]
调用JuMP包和GLPK包:
using JuMP
using GLPK用Model()函数生成一个优化问题模型,
其中with_optimizer()中选择后端的优化库:
omod21 = Model(GLPK.Optimizer)A JuMP Model
Feasibility problem with:
Variables: 0
Model mode: AUTOMATIC
CachingOptimizer state: EMPTY_OPTIMIZER
Solver name: GLPK下面指定自变量以及自变量取值区间:
@variable(omod21, 0 <= x <= 2 );
@variable(omod21, 0 <= y <= 30 );指定目标函数以及要求最大化还是最小化:
@objective(omod21, Max, 5x + 3*y )\[ 5 x + 3 y \]
注意Julia中5*x可以写成5x但是不要写成5 x。
指定一个线性约束:
@constraint(omod21, con, 1x + 5y <= 3.0 )con : \(x + 5 y \leq 3.0\)
显示目前的模型:
print(omod21)\[ \begin{aligned} \max\quad & 5 x + 3 y\\ \text{Subject to} \quad & x + 5 y \leq 3.0\\ & x \geq 0.0\\ & y \geq 0.0\\ & x \leq 2.0\\ & y \leq 30.0\\ \end{aligned} \]
以上完成了对一个优化问题的描述,
保存在变量omod21中。
用JuMP.optimize!(model)函数调用后端的优化程序库求解:
JuMP.optimize!(omod21)求解结束后,结果也保存在模型变量omod21中。
求解结束可能处于如下状态:
- 求出最优解,或者证明无解;
- 因数值计算问题不能继续,或者迭代次数超界或者运算时间超界而停止。
用JuMP.termination_status(model)查询求解的结束原因:
println(termination_status(omod21))
## OPTIMAL这个状态的表示找到了最优解。 对线性规划问题, 还可以检查是否找到了primal-dual对, 即可行解集与对偶的零对偶间隙(zero duality gap):
println(primal_status(omod21))
println(dual_status(omod21))
## FEASIBLE_POINT
## FEASIBLE_POINT上面两个结果表示primal-dual对都是可行的。 因为求解停止状态是OPTIMAL(最优), 所以解是最优。
显示最优的目标函数值:
println("最大目标函数值:", objective_value(omod21))
## 最大目标函数值:10.6显示最大值点,保存在模型指定的自变量名:
println("最大值点:x=", value(x), " y=", value(y))
## 最大值点:x=2.0 y=0.215.6.2.2 非线性规划
这里给一个利用JuMP调用Ipopt后端的例子。 Ipopt是一个开源的C++非线性最优化库。
考虑二元函数\(\,(1 - x)^2 + 100 (y - x^2)^2\)的无约束最小值问题。 程序如下:
using JuMP
using Ipopt建立模型:
omod22 = Model(Ipopt.Optimizer)A JuMP Model
Feasibility problem with:
Variables: 0
Model mode: AUTOMATIC
CachingOptimizer state: EMPTY_OPTIMIZER
Solver name: Ipopt定义变量:
@variable(omod22, x, start = 0.0);
@variable(omod22, y, start = 0.0);定义目标函数,选择最小化:
@NLobjective(omod22, Min, (1 - x)^2 + 100 * (y - x^2)^2)求解:
optimize!(omod22)******************************************************************************
This program contains Ipopt, a library for large-scale nonlinear optimization.
Ipopt is released as open source code under the Eclipse Public License (EPL).
For more information visit https://github.com/coin-or/Ipopt
******************************************************************************
This is Ipopt version 3.14.4, running with linear solver MUMPS 5.4.1.
Number of nonzeros in equality constraint Jacobian...: 0
Number of nonzeros in inequality constraint Jacobian.: 0
Number of nonzeros in Lagrangian Hessian.............: 3
Total number of variables............................: 2
variables with only lower bounds: 0
variables with lower and upper bounds: 0
variables with only upper bounds: 0
Total number of equality constraints.................: 0
Total number of inequality constraints...............: 0
inequality constraints with only lower bounds: 0
inequality constraints with lower and upper bounds: 0
inequality constraints with only upper bounds: 0
iter objective inf_pr inf_du lg(mu) ||d|| lg(rg) alpha_du alpha_pr ls
0 1.0000000e+00 0.00e+00 2.00e+00 -1.0 0.00e+00 - 0.00e+00 0.00e+00 0
1 9.5312500e-01 0.00e+00 1.25e+01 -1.0 1.00e+00 - 1.00e+00 2.50e-01f 3
2 4.8320569e-01 0.00e+00 1.01e+00 -1.0 9.03e-02 - 1.00e+00 1.00e+00f 1
3 4.5708829e-01 0.00e+00 9.53e+00 -1.0 4.29e-01 - 1.00e+00 5.00e-01f 2
4 1.8894205e-01 0.00e+00 4.15e-01 -1.0 9.51e-02 - 1.00e+00 1.00e+00f 1
5 1.3918726e-01 0.00e+00 6.51e+00 -1.7 3.49e-01 - 1.00e+00 5.00e-01f 2
6 5.4940990e-02 0.00e+00 4.51e-01 -1.7 9.29e-02 - 1.00e+00 1.00e+00f 1
7 2.9144630e-02 0.00e+00 2.27e+00 -1.7 2.49e-01 - 1.00e+00 5.00e-01f 2
8 9.8586451e-03 0.00e+00 1.15e+00 -1.7 1.10e-01 - 1.00e+00 1.00e+00f 1
9 2.3237475e-03 0.00e+00 1.00e+00 -1.7 1.00e-01 - 1.00e+00 1.00e+00f 1
iter objective inf_pr inf_du lg(mu) ||d|| lg(rg) alpha_du alpha_pr ls
10 2.3797236e-04 0.00e+00 2.19e-01 -1.7 5.09e-02 - 1.00e+00 1.00e+00f 1
11 4.9267371e-06 0.00e+00 5.95e-02 -1.7 2.53e-02 - 1.00e+00 1.00e+00f 1
12 2.8189505e-09 0.00e+00 8.31e-04 -2.5 3.20e-03 - 1.00e+00 1.00e+00f 1
13 1.0095040e-15 0.00e+00 8.68e-07 -5.7 9.78e-05 - 1.00e+00 1.00e+00f 1
14 1.3288608e-28 0.00e+00 2.02e-13 -8.6 4.65e-08 - 1.00e+00 1.00e+00f 1
Number of Iterations....: 14
(scaled) (unscaled)
Objective...............: 1.3288608467480825e-28 1.3288608467480825e-28
Dual infeasibility......: 2.0183854587685121e-13 2.0183854587685121e-13
Constraint violation....: 0.0000000000000000e+00 0.0000000000000000e+00
Variable bound violation: 0.0000000000000000e+00 0.0000000000000000e+00
Complementarity.........: 0.0000000000000000e+00 0.0000000000000000e+00
Overall NLP error.......: 2.0183854587685121e-13 2.0183854587685121e-13
Number of objective function evaluations = 36
Number of objective gradient evaluations = 15
Number of equality constraint evaluations = 0
Number of inequality constraint evaluations = 0
Number of equality constraint Jacobian evaluations = 0
Number of inequality constraint Jacobian evaluations = 0
Number of Lagrangian Hessian evaluations = 14
Total seconds in IPOPT = 1.542
EXIT: Optimal Solution Found.上面的显示已经表明找到了最优解。
用termination_status(omod21)查询算法退出状态:
println(termination_status(omod22))
## LOCALLY_SOLVED结果显示得到局部最优, 因为大多数算法只能保证局部最优, 所以没有问题。
显示目标函数值和最小值点:
println("最小化目标函数值 = ", objective_value(omod22))
println("最小值点:x = ", value(x), " y = ", value(y))
## 最小化目标函数值 = 1.3288608467480825e-28
## 最小值点:x = 0.9999999999999899 y = 0.9999999999999792增加一个简单的线性约束\(x+y=10\), 重新求解:
@constraint(omod22, x + y == 10)
optimize!(omod22);This is Ipopt version 3.14.4, running with linear solver MUMPS 5.4.1.
Number of nonzeros in equality constraint Jacobian...: 2
Number of nonzeros in inequality constraint Jacobian.: 0
Number of nonzeros in Lagrangian Hessian.............: 3
Total number of variables............................: 2
variables with only lower bounds: 0
variables with lower and upper bounds: 0
variables with only upper bounds: 0
Total number of equality constraints.................: 1
Total number of inequality constraints...............: 0
inequality constraints with only lower bounds: 0
inequality constraints with lower and upper bounds: 0
inequality constraints with only upper bounds: 0
iter objective inf_pr inf_du lg(mu) ||d|| lg(rg) alpha_du alpha_pr ls
0 1.0000000e+00 1.00e+01 1.00e+00 -1.0 0.00e+00 - 0.00e+00 0.00e+00 0
1 9.6315968e+05 1.78e-15 3.89e+05 -1.0 9.91e+00 - 1.00e+00 1.00e+00h 1
2 1.6901461e+05 0.00e+00 1.16e+05 -1.0 3.24e+00 - 1.00e+00 1.00e+00f 1
3 2.5433173e+04 0.00e+00 3.18e+04 -1.0 2.05e+00 - 1.00e+00 1.00e+00f 1
4 2.6527756e+03 0.00e+00 7.79e+03 -1.0 1.19e+00 - 1.00e+00 1.00e+00f 1
5 1.1380324e+02 0.00e+00 1.35e+03 -1.0 5.62e-01 - 1.00e+00 1.00e+00f 1
6 3.3745506e+00 0.00e+00 8.45e+01 -1.0 1.50e-01 - 1.00e+00 1.00e+00f 1
7 2.8946196e+00 0.00e+00 4.22e-01 -1.0 1.07e-02 - 1.00e+00 1.00e+00f 1
8 2.8946076e+00 0.00e+00 1.07e-05 -1.7 5.42e-05 - 1.00e+00 1.00e+00f 1
9 2.8946076e+00 0.00e+00 5.91e-13 -8.6 1.38e-09 - 1.00e+00 1.00e+00f 1
Number of Iterations....: 9
(scaled) (unscaled)
Objective...............: 2.8946075504894599e+00 2.8946075504894599e+00
Dual infeasibility......: 5.9130478291535837e-13 5.9130478291535837e-13
Constraint violation....: 0.0000000000000000e+00 0.0000000000000000e+00
Variable bound violation: 0.0000000000000000e+00 0.0000000000000000e+00
Complementarity.........: 0.0000000000000000e+00 0.0000000000000000e+00
Overall NLP error.......: 5.9130478291535837e-13 5.9130478291535837e-13
Number of objective function evaluations = 10
Number of objective gradient evaluations = 10
Number of equality constraint evaluations = 10
Number of inequality constraint evaluations = 0
Number of equality constraint Jacobian evaluations = 1
Number of inequality constraint Jacobian evaluations = 0
Number of Lagrangian Hessian evaluations = 9
Total seconds in IPOPT = 0.081
EXIT: Optimal Solution Found.println(termination_status(omod22));
println("最小化目标函数值 = ", objective_value(omod22))
println("最小值点:x = ", value(x), " y = ", value(y))
## LOCALLY_SOLVED
## 最小化目标函数值 = 2.89460755048946
## 最小值点:x = 2.701147124098218 y = 7.2988528759017814考虑目标函数在简单约束\(x \geq 1.25\), \(y \geq -2.1\)下的优化。
using JuMP
using Ipopt
omod23 = Model(Ipopt.Optimizer);
@variable(omod23, x, start = 0.0);
@variable(omod23, y, start = 0.0);
@constraint(omod23, x >= 1.25);
@constraint(omod23, y >= -2.1);
@NLobjective(omod23, Min, (1 - x)^2 + 100 * (y - x^2)^2);
optimize!(omod23);This is Ipopt version 3.14.4, running with linear solver MUMPS 5.4.1.
Number of nonzeros in equality constraint Jacobian...: 0
Number of nonzeros in inequality constraint Jacobian.: 2
Number of nonzeros in Lagrangian Hessian.............: 3
Total number of variables............................: 2
variables with only lower bounds: 0
variables with lower and upper bounds: 0
variables with only upper bounds: 0
Total number of equality constraints.................: 0
Total number of inequality constraints...............: 2
inequality constraints with only lower bounds: 2
inequality constraints with lower and upper bounds: 0
inequality constraints with only upper bounds: 0
iter objective inf_pr inf_du lg(mu) ||d|| lg(rg) alpha_du alpha_pr ls
0 1.0000000e+00 1.25e+00 1.50e+00 -1.0 0.00e+00 - 0.00e+00 0.00e+00 0
1 3.3580384e+02 0.00e+00 9.92e+02 -1.0 1.35e+00 - 1.00e+00 1.00e+00h 1
2 1.2533591e-01 0.00e+00 2.71e-01 -1.0 1.83e+00 - 1.00e+00 1.00e+00f 1
3 9.6112888e-02 0.00e+00 1.04e+00 -1.7 1.21e-01 - 1.00e+00 1.00e+00f 1
4 8.3379322e-02 0.00e+00 2.37e-01 -1.7 5.21e-02 - 1.00e+00 1.00e+00f 1
5 8.1695749e-02 0.00e+00 4.83e-03 -1.7 7.05e-03 - 1.00e+00 1.00e+00f 1
6 6.4381341e-02 0.00e+00 5.23e-01 -3.8 8.31e-02 - 1.00e+00 1.00e+00f 1
7 6.2674893e-02 0.00e+00 6.35e-03 -3.8 6.91e-03 - 1.00e+00 1.00e+00f 1
8 6.2650298e-02 0.00e+00 1.40e-06 -3.8 1.13e-04 - 1.00e+00 1.00e+00f 1
9 6.2501984e-02 0.00e+00 4.39e-05 -5.7 7.41e-04 - 1.00e+00 1.00e+00f 1
iter objective inf_pr inf_du lg(mu) ||d|| lg(rg) alpha_du alpha_pr ls
10 6.2501839e-02 0.00e+00 5.26e-11 -5.7 6.40e-07 - 1.00e+00 1.00e+00f 1
11 6.2499996e-02 0.00e+00 6.78e-09 -8.6 9.21e-06 - 1.00e+00 1.00e+00f 1
Number of Iterations....: 11
(scaled) (unscaled)
Objective...............: 6.2499996278424341e-02 6.2499996278424341e-02
Dual infeasibility......: 6.7847379936480934e-09 6.7847379936480934e-09
Constraint violation....: 0.0000000000000000e+00 0.0000000000000000e+00
Variable bound violation: 0.0000000000000000e+00 0.0000000000000000e+00
Complementarity.........: 2.5284241638252829e-09 2.5284241638252829e-09
Overall NLP error.......: 6.7847379936480934e-09 6.7847379936480934e-09
Number of objective function evaluations = 12
Number of objective gradient evaluations = 12
Number of equality constraint evaluations = 0
Number of inequality constraint evaluations = 12
Number of equality constraint Jacobian evaluations = 0
Number of inequality constraint Jacobian evaluations = 1
Number of Lagrangian Hessian evaluations = 11
Total seconds in IPOPT = 0.002
EXIT: Optimal Solution Found.println("约束最小化目标函数值 = ", objective_value(omod22))
println("约束最小值点:x = ", value(x), " y = ", value(y))
## 约束最小化目标函数值 = 2.89460755048946
## 约束最小值点:x = 1.2499999925568486 y = 1.562499981381971815.6.3 一元方程求根的Roots包
Roots包提供了一元方程求根算法, 主要是二分法之类不依赖于导数的方法。 比如,如下的一元函数 \[ f(x) = \sin(4(x - 0.25)) + x + x^{20} - 1, \ x \in [0,1] \] 有唯一一个实根。函数图形如下:
using Plots; Plots.gr()
rf1(x) = sin(4.0*(x - 0.25)) + x + x^20 - 1.0
Plots.plot(rf1, 0.0, 1.0, linewidth=2, legend=false)
Plots.hline!([0.0], color=:black)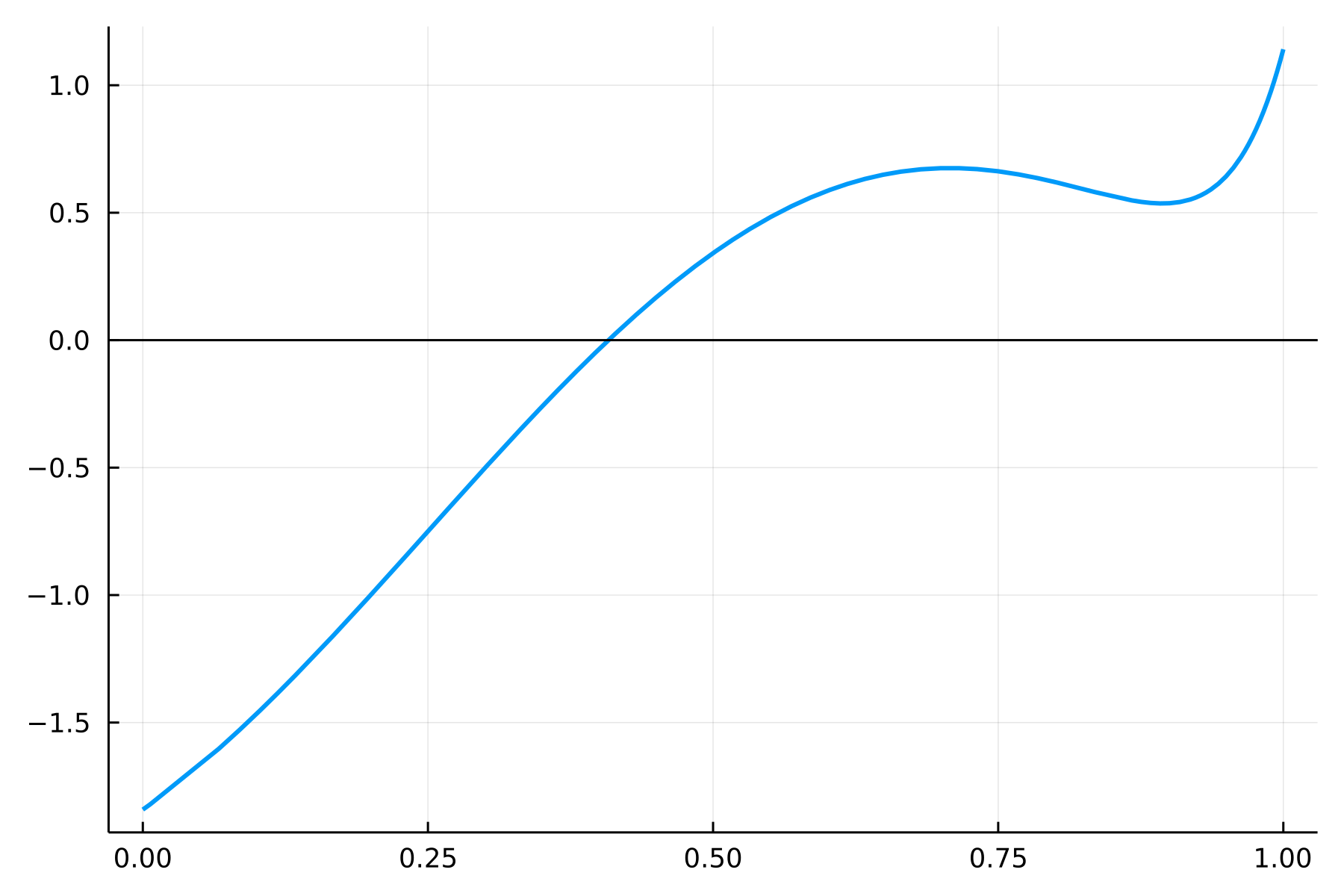
svg
Roots提供了若干种一元函数求根算法,比较基本的是二分法:
using Roots
Roots.find_zero(rf1, (0.0, 1.0), Bisection())
## 0.40829350427936706上面的方法需要输入含根区间。 不要求输入含根区间, 仅输入一个初始点的方法:
Roots.find_zero(rf1, 1.0)
## 0.40829350427936706使用割线法:
Roots.find_zero(rf1, 1.0, Order1())
## 0.40829350427936706PolynomialRoots包提供了求多项式所有复根的功能。
比如,对多项式\(f(x) = x^5 - x - 1\),
用系数升幂表示为[-1, -1, 0, 0, 0, 1],
用roots()求根:
using PolynomialRoots
PolynomialRoots.roots([-1, -1, 0, 0, 0, 1])5-element Vector{ComplexF64}:
1.1673039782614187 - 1.1102230246251565e-16im
0.18123244446987524 + 1.083954101317711im
0.18123244446987535 - 1.0839541013177107im
-0.7648844336005848 + 0.3524715460317263im
-0.7648844336005848 - 0.35247154603172626im15.7 自动微分
15.7.1 介绍
在机器学习等领域经常需要对用编程表示的复杂函数计算导数、梯度, 仅有少数情况下可以获得解析表达式, 但可以用一种“自动微分”的工具计算微分。 自动微分不是用有限差分逼近微分, 而是分析被微分的函数的Julia程序代码构成精确的(仅有数值计算误差)的微分。 ForwardDiff库实现自动微分。 Optim和JuMP包都可以利用ForwardDiff计算一阶、二阶、一元、多元的微分。 为了函数能够计算微分, 函数的自变量不能声明成Float64这样的具体类型, 可不声明, 或声明成AbstractReal。 参见:
15.7.2 示例
using ForwardDiff一元函数一阶微分例:
let
f1(x) = x^3
f1d(x) = 3 * x^2
x = [-1, 0, 1, 2]
@show f1d.(x);
@show ForwardDiff.derivative.(f1, x);
end
## f1d.(x) = [3, 0, 3, 12]
## ForwardDiff.derivative.(f1, x) = [3, 0, 3, 12]多元函数: \[ f_1(x) = \sum_i \sin(x_i) + \prod_i \sqrt{x_i} . \]
梯度:
let
f1(x) = sum(sin, x) + prod(sqrt, x)
x = [1, 2, 3]
ForwardDiff.gradient(f1, x)
end3-element Vector{Float64}:
1.765047177259729
0.19622559914865206
-0.5817442061365823还可以计算多元到多元变换函数的Jacobian, 多元函数的海色阵。
15.7.3 符号计算
借助于Symbolics包,
ForwardDiff也能进行简单的符号计算。
用@variables声明符号计算用的变量,
用通常的方式定义以符号为自变量的函数,
就可以用符号计算产生微分。如:
using ForwardDiff
using Symbolics
let
@variables x
f(x) = x^3 + sin(x)
ForwardDiff.derivative(f, x)
end\[\begin{aligned} 3 x^{2} + \cos\left( x \right) \end{aligned}\]
SymEngine包也能用来进行符号代数计算, 这是C++函数库SymEngine的接口包。 使用例子:
using SymEngine@vars x; # 将x定义为一个符号变量
f = x^3 + sin(x) # 注意没有使用Julia的函数定义,而是直接写成了符号变量的表达式
diff(f, x)
## 3*x^2 + cos(x)expand((x + 1)^2)
## 1 + 2*x + x^215.8 微分方程求解
DifferentialEquations包用来求解各种微分方程。
参见:
15.8.1 使用步骤
using DifferentialEquations先定义方程, 即 \[ \frac{d u(t)}{dt} = f(u, p, t) . \] 其中\(u = u(t, p)\)是状态,\(t\)是时间, \(p\)是参数。 要定义的是\(f\)。
比如,
方程
\[
\frac{d x(t)}{dt} = -0.5 x,
\]
则可定义方程的f为:
function odef1(x, p, t)
-0.5*x
end注意虽然f不依赖于p和t,但是定义时还是要按照u, p, t的次序输入。
其次给出初值和计算的时间区间:
x0 = 100.0
tspan = [0.0, 10.0];然后用f、初值、时间区间定义一个ODE问题:
prob = ODEProblem(odef1,x0,tspan)用solve(prob)求解。
这个函数有许多可选参数和关键字参数,
暂时用缺省值:
solu = solve(prob)retcode: Success
Interpolation: specialized 4th order "free" interpolation, specialized 2nd order "free" stiffness-aware interpolation
t: 13-element Vector{Float64}:
0.0
0.11487006523845551
0.525610320770801
1.1230965878427834
1.8167073619629848
2.659619674735995
3.606046985752032
4.664944115892504
5.810601803231108
7.036860555208579
8.327490332039291
9.67365783232293
10.0
u: 13-element Vector{Float64}:
100.0
94.41832295072311
76.88916991635023
57.03254079008166
40.31876034326017
26.452793572845508
16.480048912041266
9.705640691293844
5.4733329373288075
2.9646936121839333
1.5550085922531618
0.7932853035000473
0.6738529096715975可以用solu.u访问离散的状态值,
用solu.t访问离散的时间值。
这些离散值仅有少数几个,其它的值通过插值生成,
可以直接调用solu(t)获得t时间的解。如:
[solu.t solu.u]13×2 Matrix{Float64}:
0.0 100.0
0.11487 94.4183
0.52561 76.8892
1.1231 57.0325
1.81671 40.3188
2.65962 26.4528
3.60605 16.48
4.66494 9.70564
5.8106 5.47333
7.03686 2.96469
8.32749 1.55501
9.67366 0.793285
10.0 0.673853solu(1.5)
## 47.23660409273191可以直接用Plots包的plot函数作解的曲线图:
using Plots
Plots.plot(solu)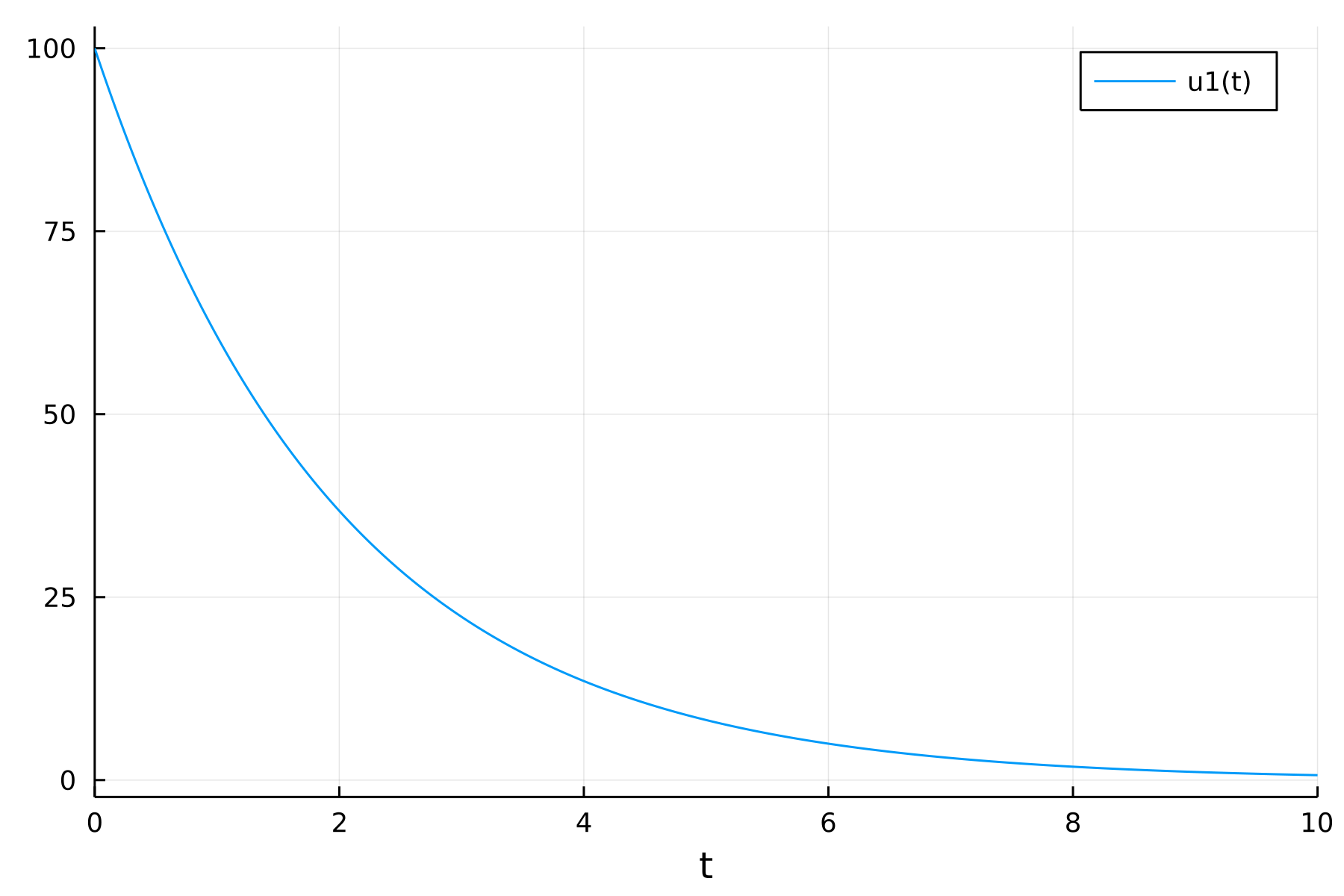
svg
15.8.2 联立常微分方程求解
考虑如下的SIR模型:
\[\begin{aligned} \frac{d s}{dt} =& - \beta s i \\ \frac{d i}{dt} =& + \beta s i & - \gamma i \\ \frac{d r}{dt} =& & + \gamma i . \end{aligned}\]
SIR是传染病模型, \(s(t)\)是\(t\)时刻的易感者比例, \(i(t)\)是传染源比例, \(r(t)\)是感染后已痊愈不再传染的人的比例。 \(\beta\)是平均每个传染源在单位时间传染任一个易感者的概率, \(\gamma\)是单位时间传每个染源痊愈的概率。
定义方程的函数:
function ode_sir(sir, params, t)
β, γ = params
s, i, r = sir
[ - β * s * i,
β * s * i - γ * i,
γ * i
]
end定义问题,注意增加了参数部分:
sir0 = [0.99, 0.01, 0.0]
tspan = [0, 1000]
params = [0.02, 0.002]
prob_sir = ODEProblem(ode_sir, sir0, tspan, params)求解,作图:
solu_sir = solve(prob_sir)retcode: Success
Interpolation: specialized 4th order "free" interpolation, specialized 2nd order "free" stiffness-aware interpolation
t: 21-element Vector{Float64}:
0.0
0.23207772976679533
2.5528550274347483
13.46304389230141
31.375640505444295
52.768275769931336
79.6250525904276
111.14900544261724
148.20542501140756
191.35309145207972
241.62126466367508
306.3185701109404
363.6999608127893
446.4163781518166
499.0148904571018
572.1049392489593
639.5590049886904
721.5830060386954
810.5482641679171
918.8188884098756
1000.0
u: 21-element Vector{Vector{Float64}}:
[0.99, 0.01, 0.0]
[0.9899539546389264, 0.010041394206335933, 4.651154737610169e-6]
[0.989483011689005, 0.010464753629545687, 5.2234681449350516e-5]
[0.986992775808718, 0.012703001885154722, 0.00030422230612722154]
[0.9817212306488418, 0.017439013942571465, 0.0008397554085867308]
[0.9728689393400854, 0.025385504025193732, 0.001745556634720722]
[0.9561161402338479, 0.04040130561197182, 0.0034825541541801024]
[0.9244706938045387, 0.06868095366459616, 0.006848352530864986]
[0.862291062336278, 0.12389776954589712, 0.013811168117824867]
[0.7432174941641816, 0.2281110204879947, 0.02867148534782361]
[0.5445497637666605, 0.3956757459628713, 0.05977449027046794]
[0.2849307214521691, 0.590528541852403, 0.12454073669542773]
[0.137325484732258, 0.6651453028877568, 0.197529212379985]
[0.04576395087579725, 0.6468196446519481, 0.30741640447225443]
[0.02369046456146529, 0.6030522545428327, 0.3732572808957017]
[0.010320788035927734, 0.5333340773018347, 0.45634513466223736]
[0.005245522054078984, 0.4707307062766806, 0.5240237716692402]
[0.002567162810510522, 0.4019508287381813, 0.595482008451308]
[0.0013317036383725283, 0.3375510678200112, 0.6611172285416161]
[0.0006897176333784173, 0.2723979074689781, 0.7269123748976434]
[0.0004584518475381731, 0.23178633900833134, 0.7677552091441303]Plots.plot(solu_sir)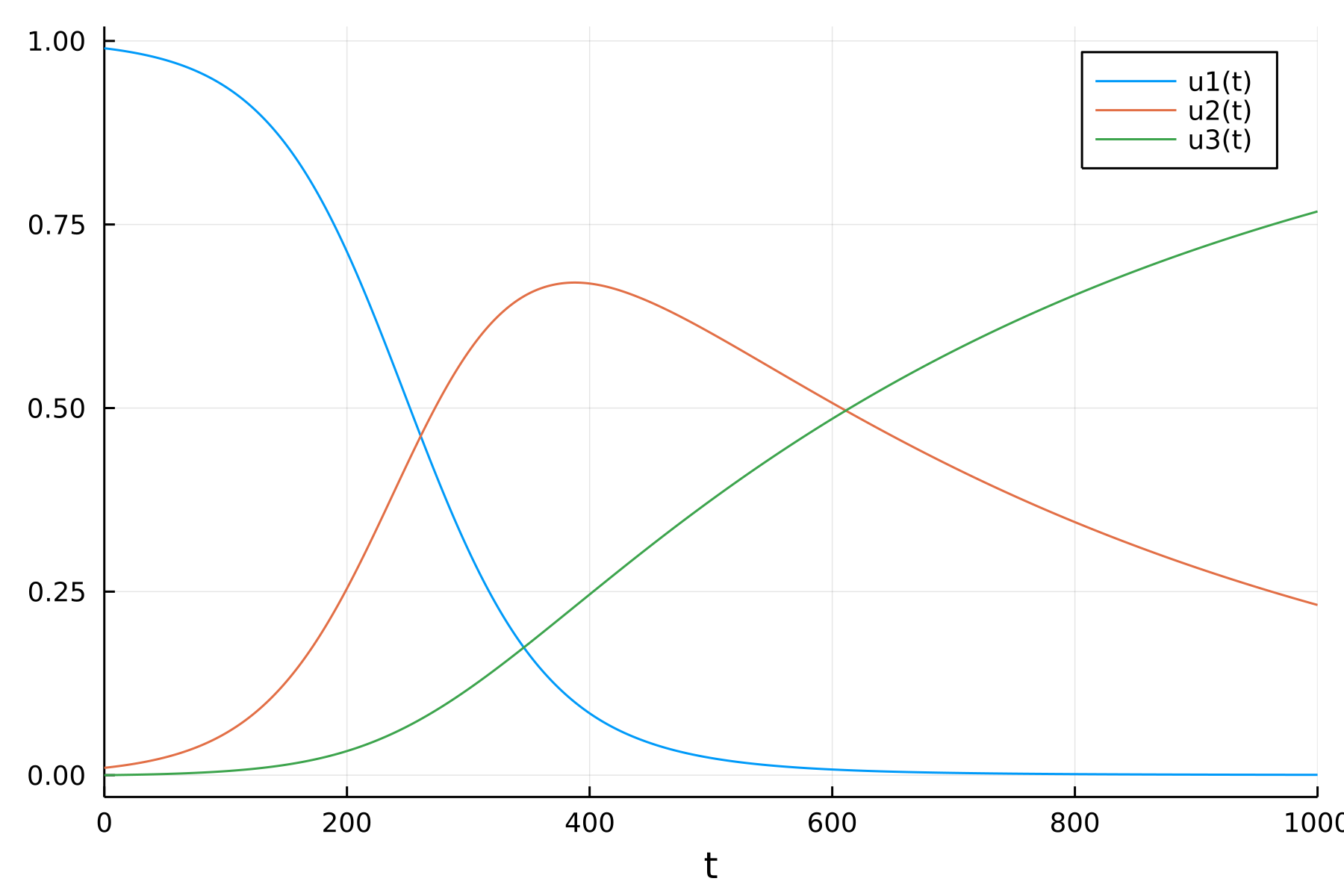
svg