41 统计学习介绍
统计学习介绍的主要参考书:
- (James et al. 2013): Gareth James, Daniela Witten, Trevor Hastie, Robert Tibshirani(2013) An Introduction to Statistical Learning: with Applications in R, Springer.
- Max Kuhn and Julia Silge(2023), Tidy Modeling with R, https://www.tmwr.org/
41.1 统计学习的基本概念和方法
统计学习(statistical learning), 也有数据挖掘(data mining),机器学习(machine learning)等称呼。 主要目的是用一些计算机算法从大量数据中发现知识。 方兴未艾的数据科学就以统计学习为重要支柱。 方法分为有监督(supervised)学习与无监督(unsupervised)学习。
无监督学习方法如聚类问题、主成分分析、异常点识别、购物篮问题等。
有监督学习即统计中回归分析和判别分析解决的问题, 现在又有回归判别数、随机森林、lasso、梯度提升法、支持向量机、 神经网络、贝叶斯网络、排序算法等许多方法。
无监督学习在给了数据之后, 直接从数据中发现规律, 比如聚类分析是发现数据中的聚集和分组现象, 购物篮分析是从数据中找到更多的共同出现的条目 (比如购买啤酒的用户也有较大可能购买火腿肠)。
有监督学习方法众多。 通常,需要把数据分为训练样本(training sample)和测试样本(testing sample), 训练样本的因变量(数值型或分类型)是已知的, 根据训练样本中自变量和因变量的关系训练出一个回归函数, 此函数以自变量为输入, 可以输出因变量的预测值。
训练出的函数有可能是有简单表达式的(例如,logistic回归)、 有参数众多的表达式的(如神经网络), 也有可能是依赖于所有训练样本而无法写出表达式的(例如k近邻分类)。
41.2 偏差与方差折衷
对回归问题,经常使用均方误差\(E|Ey - \hat y|^2\)来衡量精度。 对分类问题,经常使用分类准确率等来衡量精度。 易见\(E|Ey - \hat y|^2 = \text{Var}(\hat y) + (E\hat y - E y)^2\),所以均方误差可以分解为 \[ \text{均方误差} = \text{方差} + \text{偏差}^2, \] 训练的回归函数如果仅考虑对训练样本解释尽可能好, 就会产生许多不自然的硬凑拟合, 使得估计结果方差很大(参见33.6), 在对检验样本进行计算时因方差大而导致很大的误差, 所以选取的回归函数应该尽可能简单。
如果选取的回归函数过于简单而实际上自变量与因变量关系比较复杂, 就会使得估计的回归函数偏差比较大, 这样在对检验样本进行计算时也会有比较大的误差。
所以,在有监督学习时, 回归函数的复杂程度是一个很关键的量, 太复杂和太简单都可能导致差的结果, 需要找到一个折衷的值。
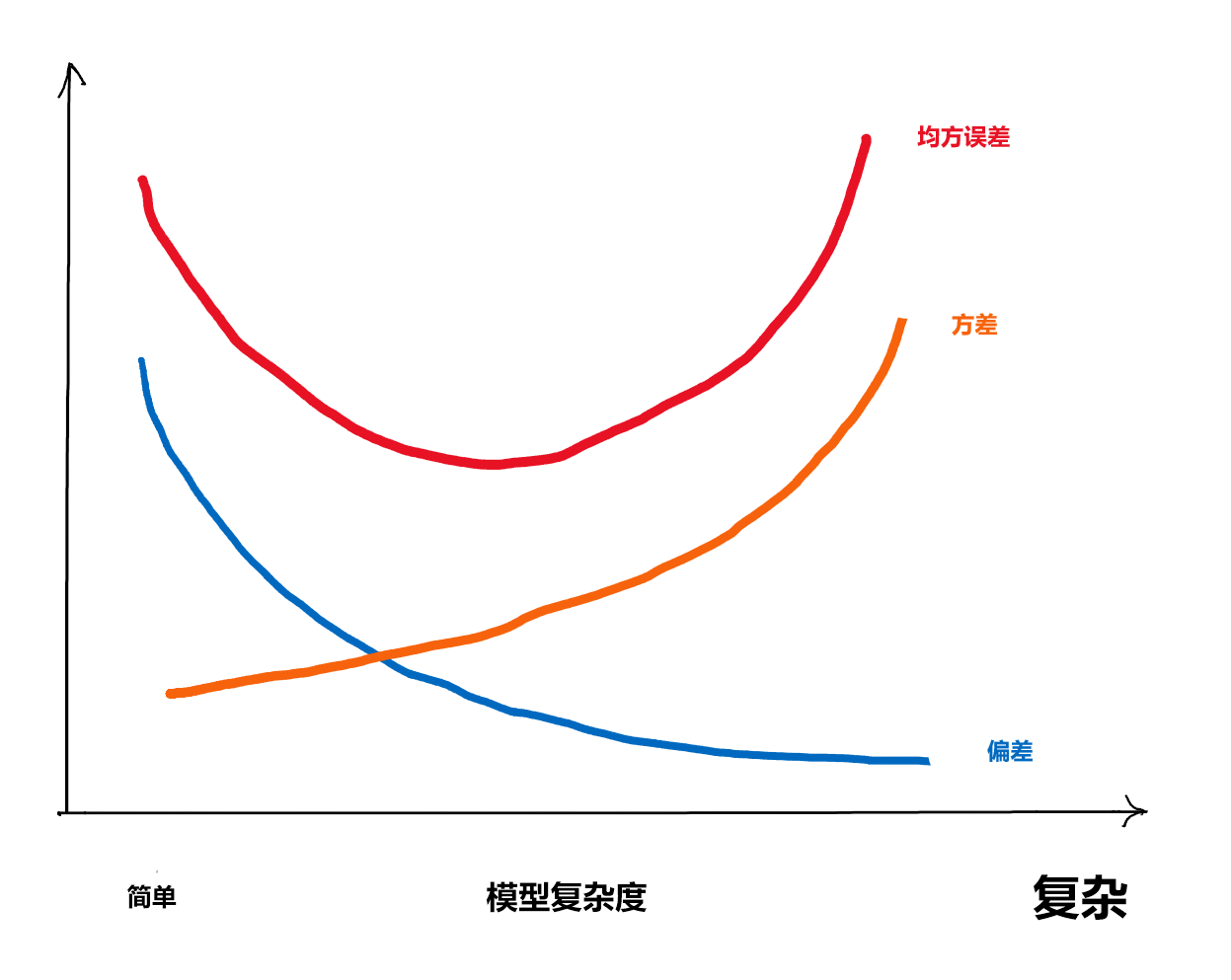
复杂程度在线性回归中就是自变量个数, 在一元曲线拟合中就是曲线的不光滑程度。 在其它指标类似的情况下, 简单的模型更稳定、可解释更好, 所以统计学特别重视模型的简化。
41.3 交叉验证
即使是在从训练样本中训练(估计)回归函数时, 也需要适当地选择模型的复杂度。 仅考虑对训练数据的拟合程度是不够的, 这会造成过度拟合问题。
为了相对客观地度量模型的预报误差, 假设训练样本有\(n\)个观测, 可以留出第一个观测不用, 用剩余的\(n-1\)个观测建模,然后预测第一个观测的因变量值, 得到一个误差;对每个观测都这样做, 就可以得到\(n\)个误差。 这样的方法叫做留一法。 这种方法想法简单, 但除了样本量特别小的情况以外, 这种方法从计算效率和统计性质上都是不好的,
更常用的是十折或五折交叉验证。 假设训练集有\(n\)个观测, 将其用随机抽样方法随机地均分成\(10\)份, 保留第1份不用, 将其余9份合并在一起用来建模,然后预报第一份; 对每一份都这样做, 并在每一份上计算评估预测精度的指标, 取这10份上的精度指标的平均值作为预测精度指标, 这样的模型预测精度评估方法叫做十折交叉验证(ten-fold cross validation)方法。
因为要预报的数据没有用来建模, 交叉验证得到的误差估计更准确。
rsample的vfold_cv可以生成这样的划分,
并对每一份,
可以用analysis()和assessment()分别提取建模用部分和验证用部分。
机器学习算法函数一般都包含了用交叉验证方法调参的功能,
不需要用户自己去划分数据。
41.4 一般步骤
一个有监督的统计学习项目, 大致上按如下步骤进行:
- 将数据拆分为训练集和测试集;
- 在训练集上比较不同的模型, 包括对变量进行的预处理、变换、降维、转码, 可以对影响模型的“超参数”用交叉验证方法进行调优, 不同模型之间也可以用交叉验证方法比较。
- 获得最优模型后,在训练集上估计模型参数, 对测试集进行测试。
41.5 回归问题的评判指标
对于回归类的问题, 设自变量为\(\boldsymbol x_i\), 因变量为\(y_i\) 用模型得到的因变量预测值为\(\hat y_i\), \(i=1,2,\dots,n\), 则常用的回归评判指标是根均方误差 \[ \text{RMSE} = \sqrt{\frac{1}{n} \sum_{i=1}^n (y_i - \hat y_i)^2} . \]
注意, 为了避免过度拟合, 计算\(\hat y_i\)所用的模型参数, 应该是从与上述数据无关的训练集中获得的。 如果使用同一组数据估计模型并且计算RMSE, 则只能衡量拟合效果, 模型用在其它数据上的效果有可能很差。
类似可以定义平均绝对误差: \[ \text{MAE} = \frac{1}{n} \sum_{i=1}^n | y_i - \hat y_i | . \]
还可以计算平均相对误差。
另一个常用的指标是复相关系数平方\(R^2\), 这是\(y_i\)和\(\hat y_i\)的样本相关系数的平方, 取值于\([0,1]\)区间, 取值越大则预测越好。
41.6 判别问题的评判指标
有监督学习问题的因变量取分类值时, 这样的问题称为判别问题。
不管可取类别有多少个, 都可以计算判别正确率, 即判别结果与真实结果相等的比例: \[ \text{正确率} = \frac{1}{n} \sum_{i=1}^n I_{\{\hat y_i = y_i \}} . \]
如果因变量仅取两个类别, 称为二分类问题。 二分类问题预测的评估有许多种指标, 各有侧重。
在医学检验中, 将有某种病的人正确检出的概率叫做敏感度(sensitivity), 将无病的人判为无病的概率叫做特异度(specificity)。 将这样的术语对应到统计假设检验问题: \[ H_0: \text{无病} \longleftrightarrow H_a: \text{有病} \] 第一类错误是\(H_0\)成立但拒绝\(H_0\)的错误, 概率为\(\alpha\); 第二类错误是\(H_a\)成立但承认\(H_0\)的错误, 概率为\(\beta\)。 则敏感度为\(1-\beta\)(检验功效), 特异度为\(1-\alpha\)。
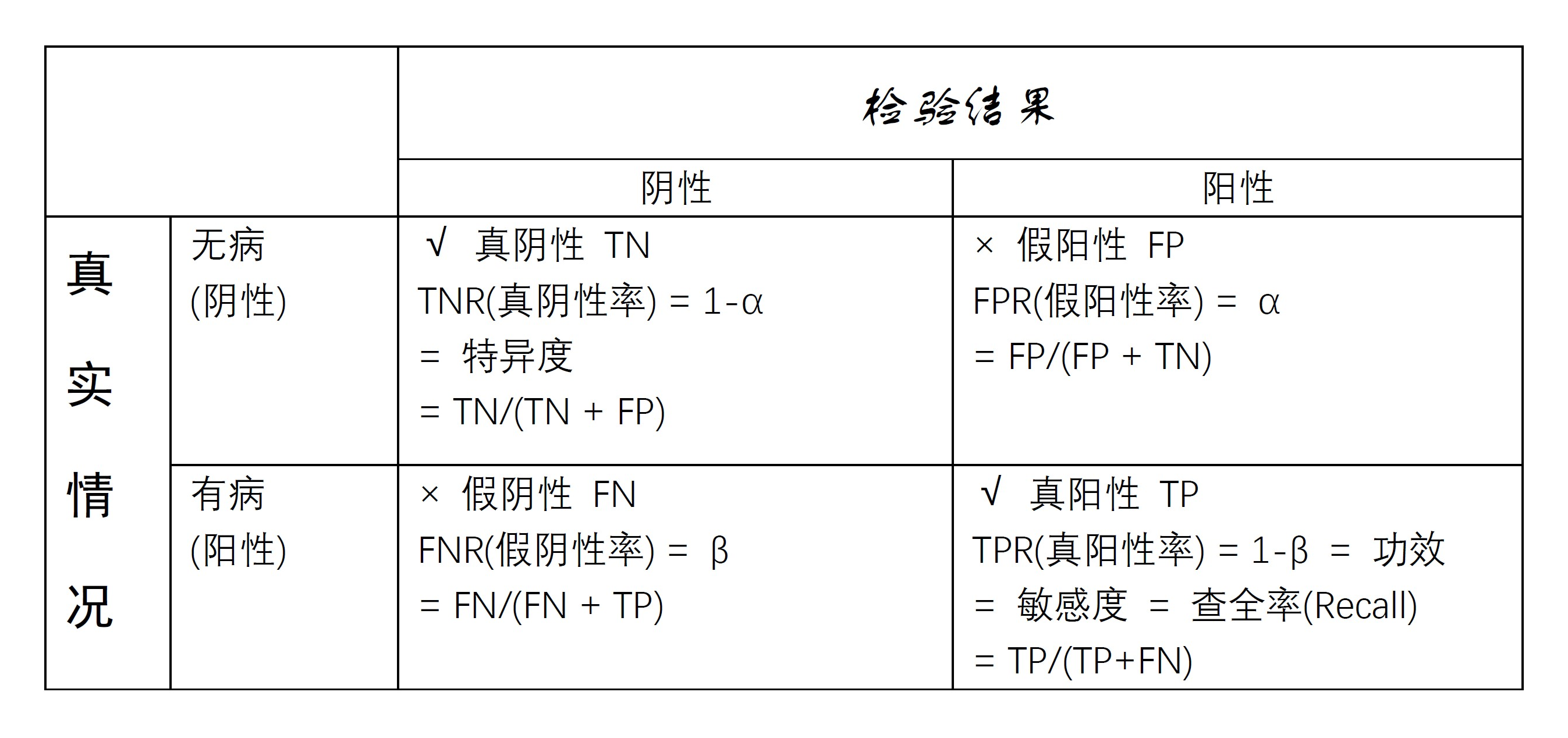
图41.1: 医学诊断四种情况表格
称\(\alpha\)为假阳性率(FPR), 等于1减去特异度; 称敏感度为真阳性率(TPR), 也称为召回率(recall)。
设图41.1中TN表示真阴性例数, 即无病判为无病个数; FN表示假阴性例数, 即有病判为无病例数; FP表示假阳性例数, 即无病判为有病例数; TP表示真阳性例数, 即有病判为有病例数。 这时,可以估计 \[\begin{aligned} \text{TPR(真阳性率)} =& 1 - \beta = \text{Sensitivity(敏感度)} = \text{Recall(查全率)} = \frac{TP}{TP + FN} ; \\ \text{FPR(假阳性率)} =& \alpha = \frac{FP}{FP + TN} ; \\ \text{TNR(真阴性率)} =& 1-\alpha = \text{Specificity(特异度)} = \frac{TN}{TN + FP}; \\ \text{FNR(假阴性率)} =& \beta = \frac{FN}{FN + TP} . \end{aligned}\]
另外, \[\begin{aligned} \text{Precision(查准率)} =& \text{Positive predictive value} = 1 - \text{FDR} = \frac{TP}{TP + FP}; \\ \text{FDR(错误发现率)} =& \frac{FP}{FP + TP} = 1 - \text{Precision}. \end{aligned}\]
F1指标是查准率与查全率的如下“调和平均”: \[ \frac{1}{\text{F1}} = \frac{1}{2} \left( \frac{1}{\text{Precision}} + \frac{1}{\text{Recall}} \right) . \] F1指标更重视将正例检出, 而忽视对反例的正确检出。
MCC(Mathew相关系数)度量\(2 \times 2\)列联表行、列变量的相关性, 与拟合优度卡方统计量等价,计算公式为: \[ \text{MCC} = \frac{\text{TN} \times \text{TP} - \text{FN} \times \text{FP} }{ \sqrt{ (\text{TP} + \text{FP}) (\text{TP} + \text{FN}) (\text{TN} + \text{FP}) (\text{TN} + \text{FN}) }} . \]
在两类的分类问题中, 将两类分别称为正例、反例, 或者阳性、阴性, 或者事件、非事件。 设自变量\(x\)得到的正例的后验概率为\(f(\boldsymbol x)\), 任意取分界值\(t\), 都可以按\(f(\boldsymbol x) > t\)和\(f(\boldsymbol x) < t\)将因变量值(标签)判为正例或者反例。 对每个\(t\), 都可以在训练集上或者测试集上计算对应的假阳性率(健康人判入有病的比例)和真阳性率(病人判为有病的概率)。 \(t\)值取得越大, 相当于检验水平\(\alpha\)取值越小, 越不容易判为有病, 这时假阳性率低, 真阳性率也低; \(t\)值取得越小, 越容易判为有病, 相当于检验水平\(\alpha\)取值很大, 这时假阳性率很高,真阳性率也很高。 最好是对比较大的分界点\(t\), 当假阳性率很低时, 真阳性率就很高。 以给定\(t\)后的假阳性率为横坐标, 真阳性率为纵坐标作曲线, 称为ROC(Receiver Operating Curve,受试者工作特征)曲线(例子见图41.2)。 曲线越靠近左上角越好。 可以用ROC曲线下方的面积大小度量判别方法的优劣, 面积越大越好。 记这个面积为AUC(Area Under the Curve)。
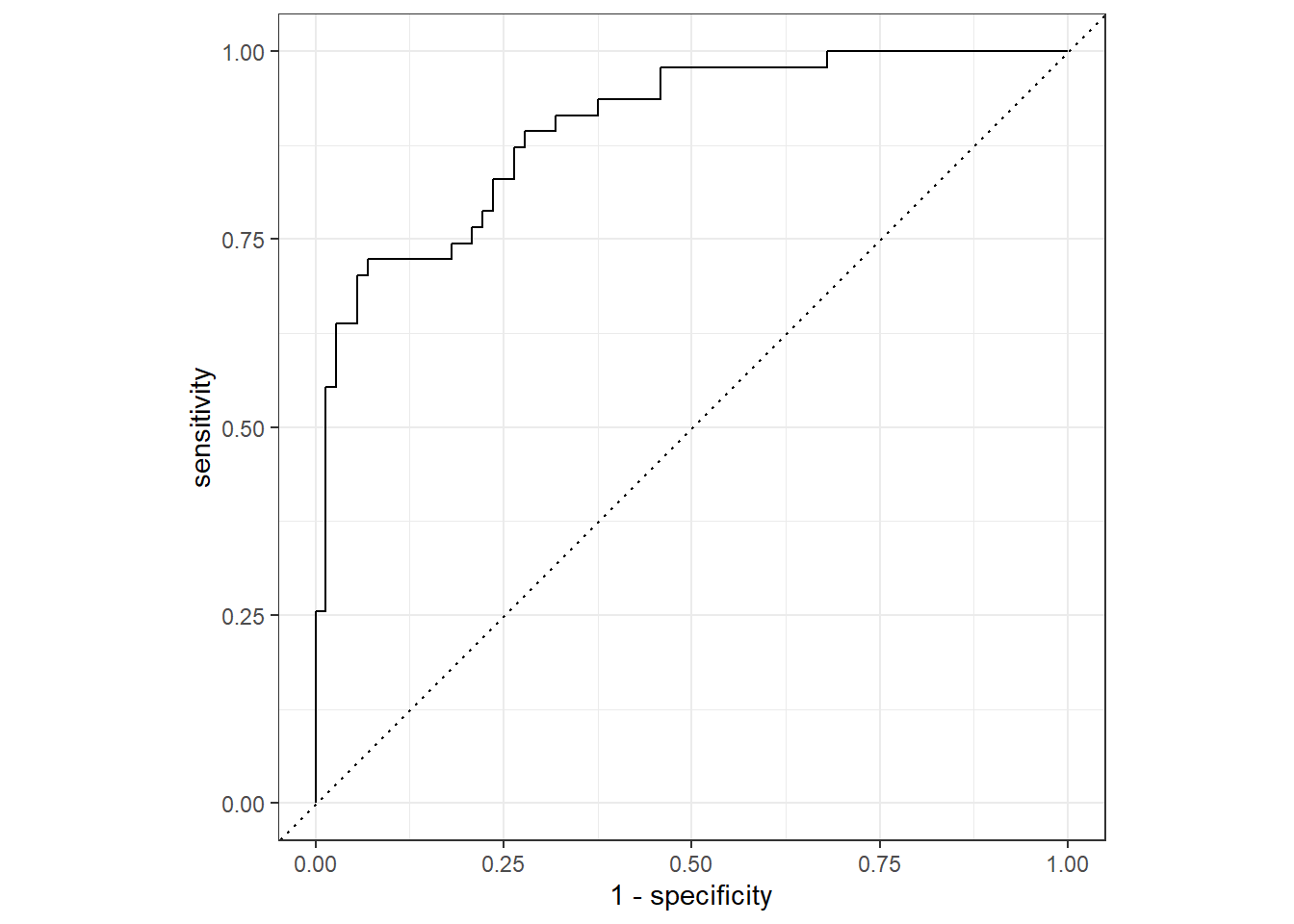
图41.2: ROC曲线示例