8 指数平滑
8.1 简单指数平滑
指数平滑最早是来自一种简单的预测方法: 用历史数据的线性组合预测下一时间点的值, 线性组合系数随距离变远而按负指数(几何级数)衰减:
\[ \hat x_h(1) \approx w x_h + w^2 x_{h-1} + \dots = \sum_{j=1}^\infty w^j x_{h+1-j} \] 其中\(0<w<1\), \(w\)越小, 距离远的历史观测对预测的贡献越小。
因为是加权平均, 所以所有加权的和应该等于零, 注意到 \[ \sum_{j=1}^\infty w^j = \frac{w}{1-w} \] 所以第\(j\)个权重应为 \[ \frac{w^j}{\frac{w}{1-w}} = (1-w) w^{j-1}, \ j=1,2,\dots \] 于是 \[ \hat x_h(1) = (1-w)(x_h + w x_{h-1} + w^2 x_{h-2} + \dots) = (1-w) \sum_{j=0}^\infty w^j x_{h-j} \] 这种预测方法叫做指数平滑方法(exponential smoothing method), 在早期应用中权重\(w\)是凭经验选取的。
经研究, ARIMA(0,1,1)的\(\hat x_h(1)\)的公式恰好具有如上形式。 对如下的ARIMA(0,1,1)模型: \[ (1-B) X_t = (1 - \theta B) \varepsilon_t \] 两边除以\(1 - \theta B\),由于 \[ \frac{1}{1 - \theta z} = \sum_{j=0}^\infty \theta^j z^j \] 所以模型可以化为 \[ \begin{aligned} & (1 - B) \sum_{j=0}^\infty \theta^j X_{t-j} = \varepsilon_t \\ & \sum_{j=0}^\infty \theta^j X_{t-j} - \sum_{j=0}^\infty \theta^j X_{t-j-1} = \varepsilon_t \\ & X_t + \sum_{j=1}^\infty \theta^j X_{t-j} - \sum_{j=1}^\infty \theta^{j-1} X_{t-j} = \varepsilon_t \\ & X_t - (1-\theta) \sum_{j=1}^\infty \theta^{j-1} X_{t-j} = \varepsilon_t \\ & X_t - (1-\theta) \sum_{j=0}^\infty \theta^j X_{t-1-j} = \varepsilon_t \end{aligned} \] 以\(t=h+1\)代入得 \[ X_{h+1} = (1-\theta) \sum_{j=0}^\infty \theta^j X_{h-j} + \varepsilon_{h+1} \] 于是 \[ \hat x_h(1) = E(X_{h+1} | \mathscr F_h) = (1-\theta) \sum_{j=0}^\infty \theta^j X_{h-j} \] 这就是\(w=\theta\)的指数平滑预测公式。
因为指数平滑预测与ARIMA(0,1,1)预测的等价性,
可以用ARIMA建模方法估计权重\(w\)。
注意arima()函数估计的MA系数是\(1 + \theta_1 z + \dots + \theta_q z^q\)形式的系数。
也可以用ARIMA模型的充分性检验来判断指数平滑预测是否有意义。
例8.1 考虑CBOE的波动率指数(VIX)2004-01-02到2011-11-21的日收盘价的对数序列, 用指数平滑方法作一步预测。 共1988个观测。
读入数据,从中计算日收盘价对数值序列:
da <- read_table("d-vix0411.txt", col_types=cols(.default = col_double()))
xts.vix <- xts(da[,-(1:3)], make_date(da$year, da$mon, da$day))
str(xts.vix)## An 'xts' object on 2004-01-02/2011-11-21 containing:
## Data: num [1:1988, 1:4] 18 18.4 17.7 16.7 15.4 ...
## - attr(*, "dimnames")=List of 2
## ..$ : NULL
## ..$ : chr [1:4] "Open" "High" "Low" "Close"
## Indexed by objects of class: [Date] TZ: UTC
## xts Attributes:
## NULL作日对数收盘价的时间序列图:
plot(vix, type="l", main="VIX Daily Log Close",
major.ticks="years", minor.ticks=NULL,
grid.ticks.on="auto")
图8.1: VIX日对数收盘价
明显不平稳且没有固定趋势。
作日对数收益率的时间序列图:
plot(delta.vix, type="l", main="VIX Daily Log Return",
major.ticks="years", minor.ticks=NULL,
grid.ticks.on="auto")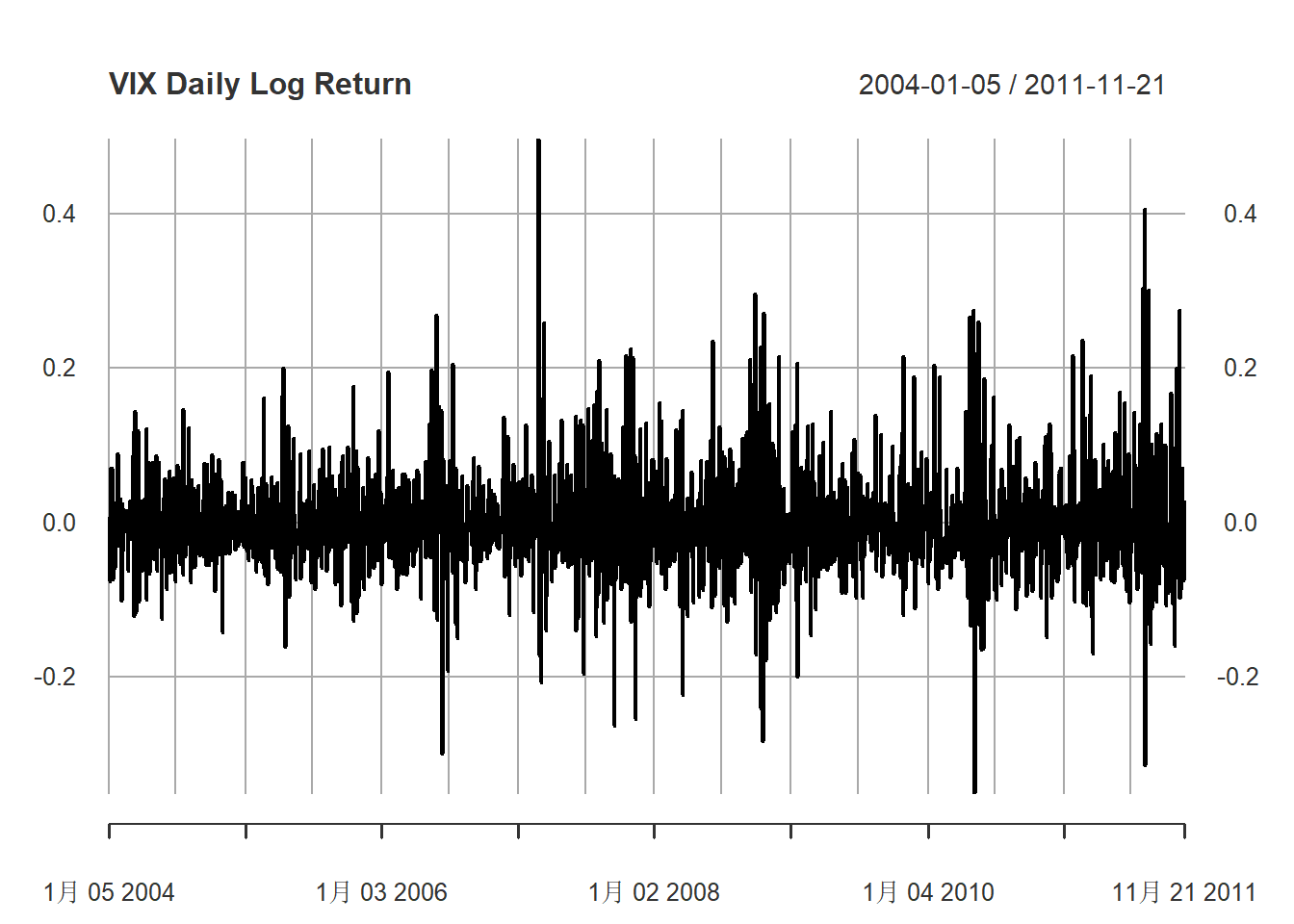
图8.2: VIX日对数收益率
日对数收益率的ACF:
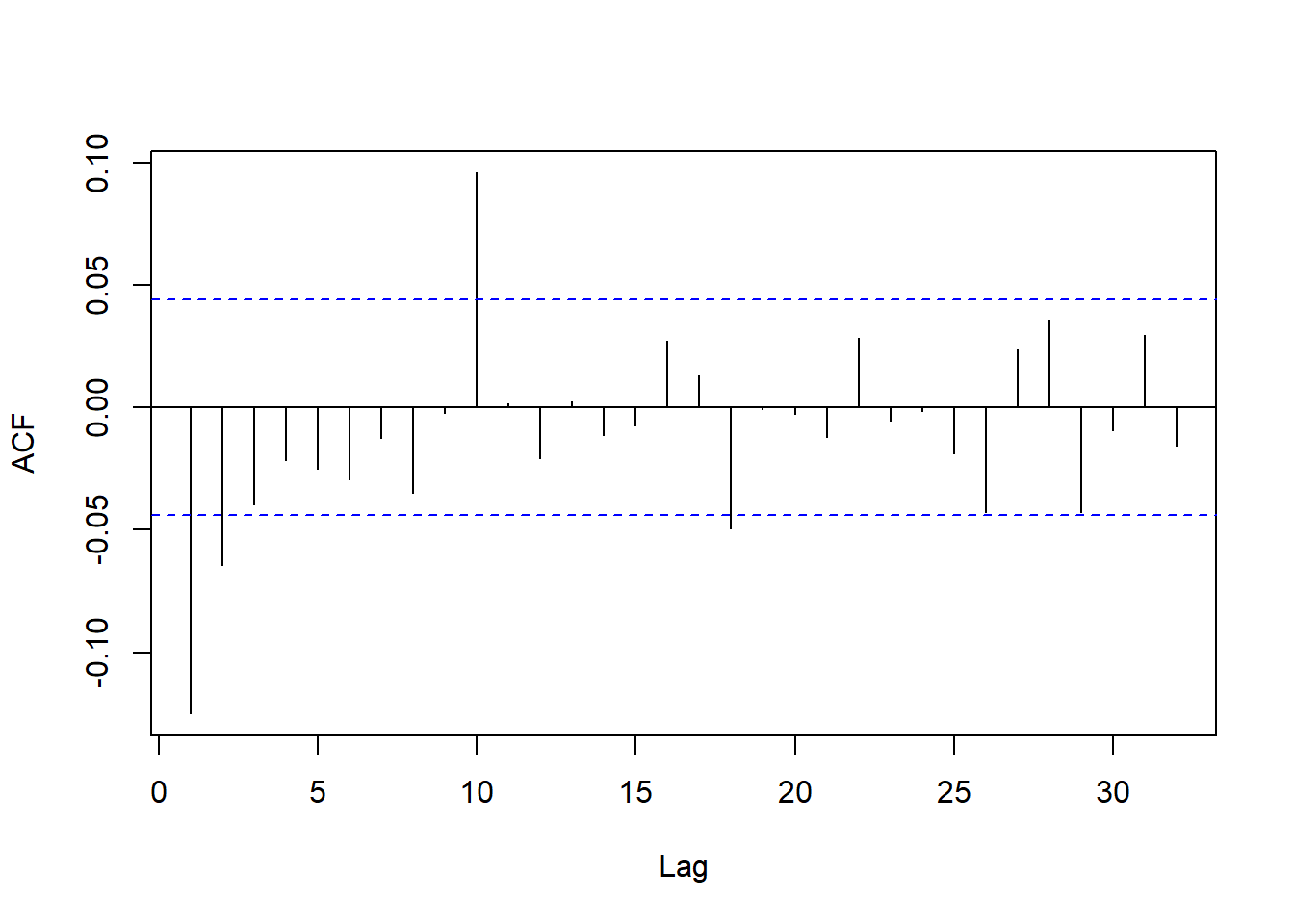
图8.3: VIX日对数收益率的ACF
虽然在滞后10的位置ACF也超界, 但是在低阶就只有滞后1明显超界, 所以对数收盘价用ARIMA(0,1,1)还是合理的。 ARIMA建模:
##
## Call:
## arima(x = c(coredata(vix)), order = c(0, 1, 1))
##
## Coefficients:
## ma1
## -0.1500
## s.e. 0.0244
##
## sigma^2 estimated as 0.004561: log likelihood = 2535.71, aic = -5067.42建立的模型为 \[ X_t = X_{t-1} + \varepsilon_t - 0.1500 \varepsilon_{t-1} \] 其中\(\hat\sigma^2 = 0.004561\)。 \(\theta = 0.1500\)。
检验残差是否白噪声:
##
## Box-Pierce test
##
## data: resm$residuals
## X-squared = 47, df = 9, p-value = 3.925e-07白噪声检验很显著, 说明模型有所不足。 从差分序列的\(\hat\rho_{10}\)很大可以预见这个问题。
另行试验ARIMA(0,1,10):
##
## Call:
## arima(x = c(coredata(vix)), order = c(0, 1, 10))
##
## Coefficients:
## ma1 ma2 ma3 ma4 ma5 ma6 ma7 ma8
## -0.1493 -0.0716 -0.0484 -0.0258 -0.0303 -0.0401 -0.0131 -0.0181
## s.e. 0.0223 0.0226 0.0228 0.0225 0.0226 0.0236 0.0231 0.0219
## ma9 ma10
## 0.0092 0.0966
## s.e. 0.0245 0.0230
##
## sigma^2 estimated as 0.004453: log likelihood = 2559.57, aic = -5097.13##
## Box-Pierce test
##
## data: resm2$residuals
## X-squared = 9.5782, df = 10, p-value = 0.4782这个模型的白噪声检验通过,而且AIC也更好。
注意我们用了8年的数据, 教材(Tsay 2013)用的数据是2008-05-01到2010-04-19为两年数据。 两年数据可能ARIMA(0,1,1)就足够。
○○○○○
8.2 时间序列成分分解
简单指数平滑, 相当于只用一个变化的水平值\(\ell_t\)拟合数据\(y_t\), \[ \ell_t = \alpha y_t + (1 - \alpha) \ell_{t-1}, \] 预测为 \[ \hat y_{t+h|t} = \ell_t . \]
可以增加一个线性的趋势增长项\(b_t\),变成: \[\begin{aligned} \ell_t =& \alpha y_t + (1 - \alpha) (\ell_{t-1} + b_{t-1}), \\ b_t =& \beta (\ell_t - \ell_{t-1}) + (1 - \beta) b_{t-1} , \\ \hat y_{t+h|t} =& \ell_t + h b_t. \end{aligned}\]
可以增加季节项\(s_t\),变成: \[\begin{aligned} \ell_t =& \alpha (y_t - s_{t-m}) + (1 - \alpha) (\ell_{t-1} + b_{t-1}), \\ b_t =& \beta (\ell_t - \ell_{t-1}) + (1 - \beta) b_{t-1} , \\ s_t =& \gamma (y_t - \ell_{t-1} - b_{t-1}) + (1 - \gamma) s_{t-m}, \\ \hat y_{t+h|t} =& \ell_t + h b_t + s_{t - m + h_m^+} . \end{aligned}\] 其中\(m\)是季节频率,如月度数据为12, 季度数据为4。 \(t - m + h_m^+\)是\(t, t-1, \dots, t-m+1\)中与\(t-m+h\)同月(季度)的值。
各项可以是相乘的。
支持时间序列分解模型的R函数:
- stats包的
HoltWinters()函数提供这样的指数平滑方法。 - forecast包的
ets()函数提供了自动选择合适的指数平滑方法并进行预报的功能。 - stats包的
StructTS()使用最大似然估计方法估计这样的分解, 仅支持加性模型。 - stats包的
stl()用局部多项式拟合方法进行分解。 - stats包的
decompose()用简单的滑动平均方法估计分解成分。
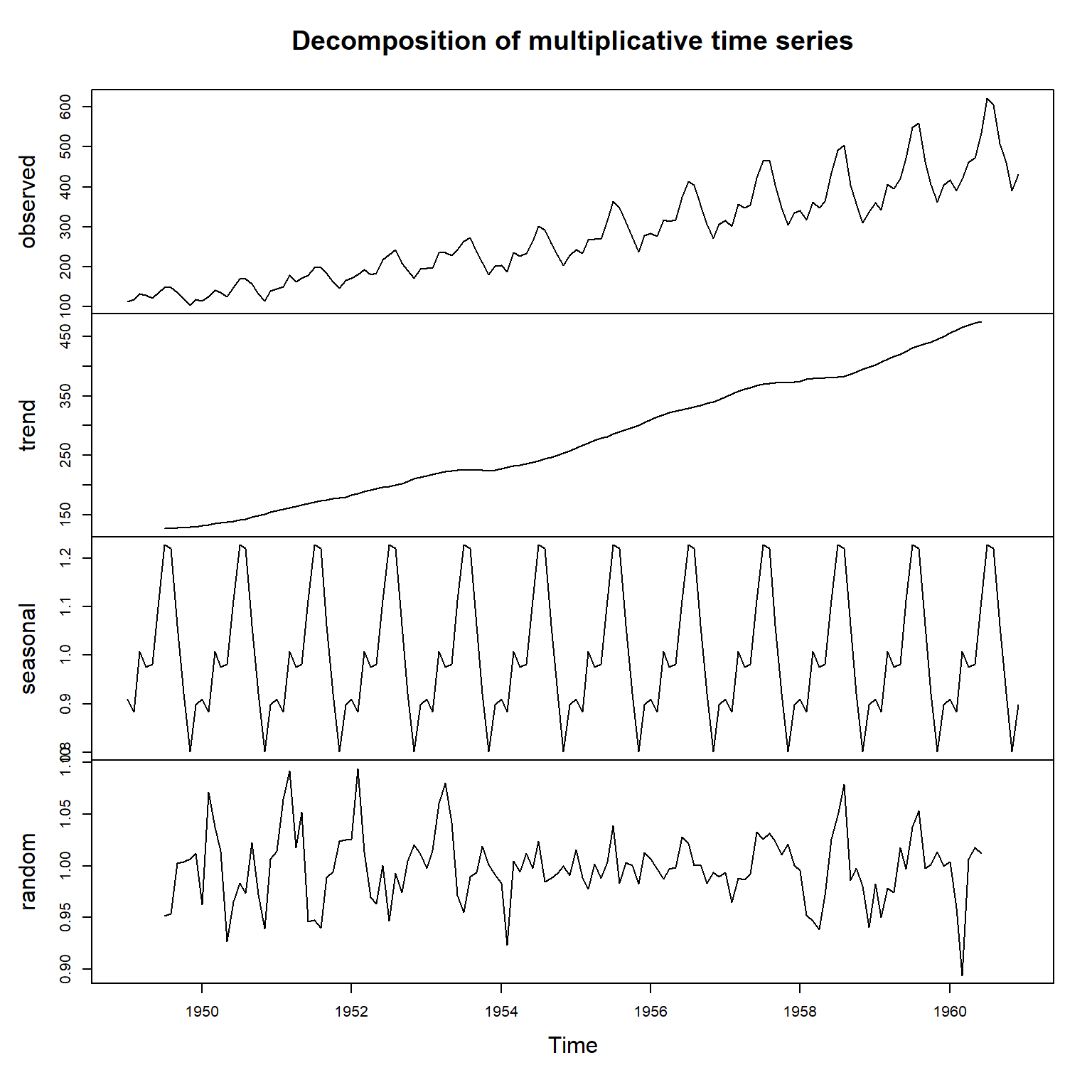
例8.2 考虑著名的航空数据的建模。 AirPassengers时间序列为1949年到1960年某航空公司月乘客人数。
图形:
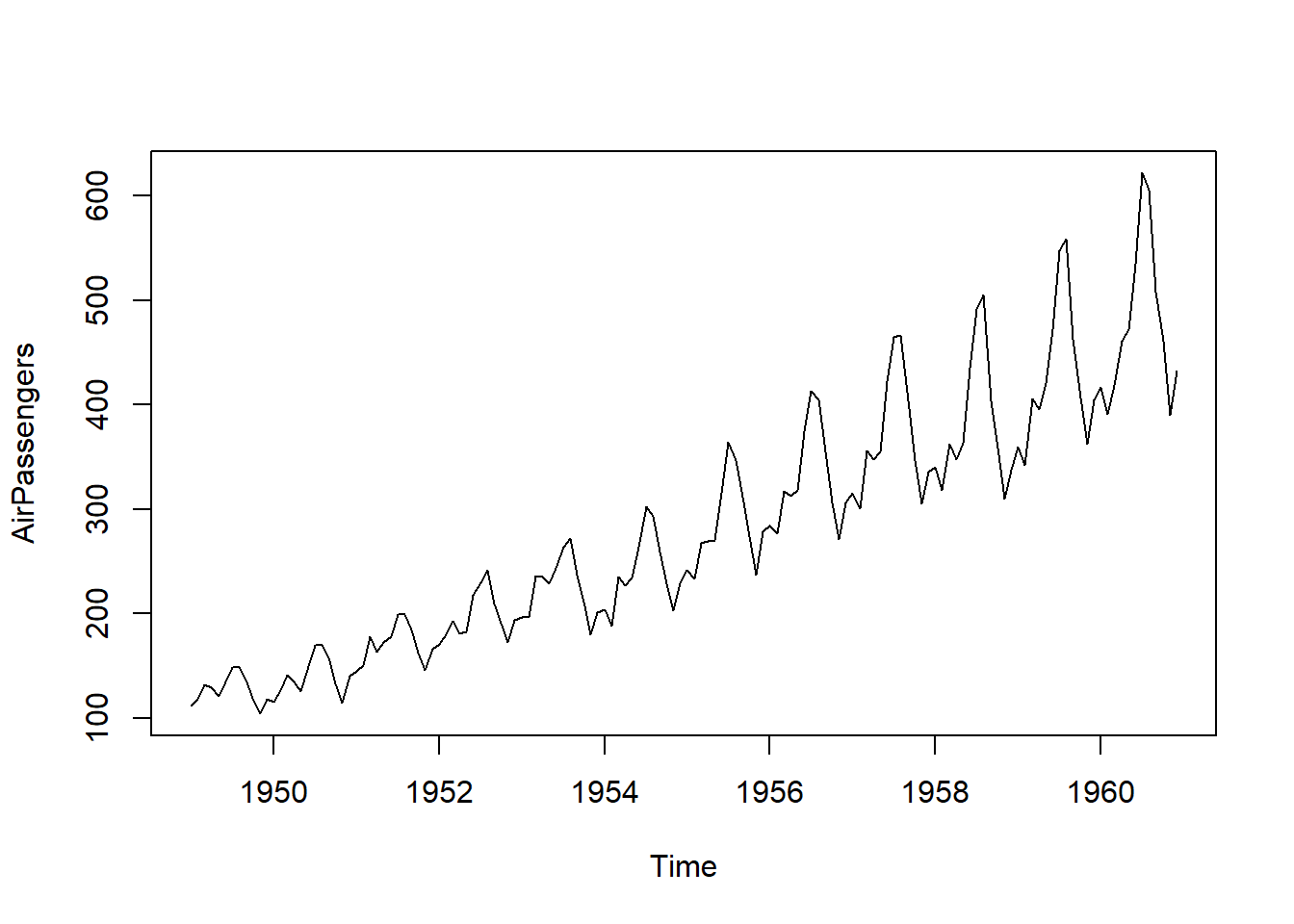
数据包含趋势、季节项, 并且应为乘性模型, 或者取对数后建模。
用HoltWinters()建模分解,并作拟合图:
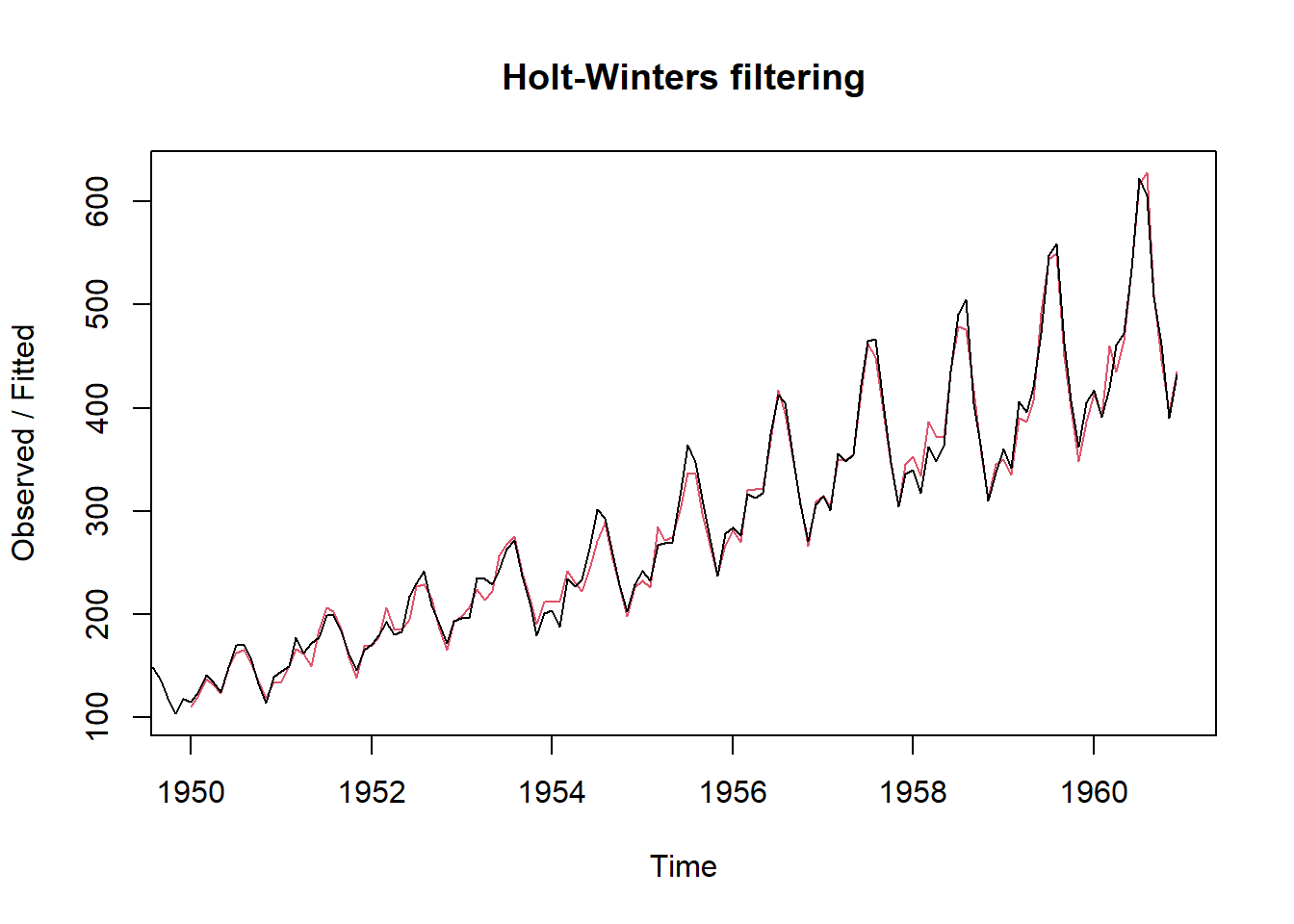
各个分解成分的滤波结果:
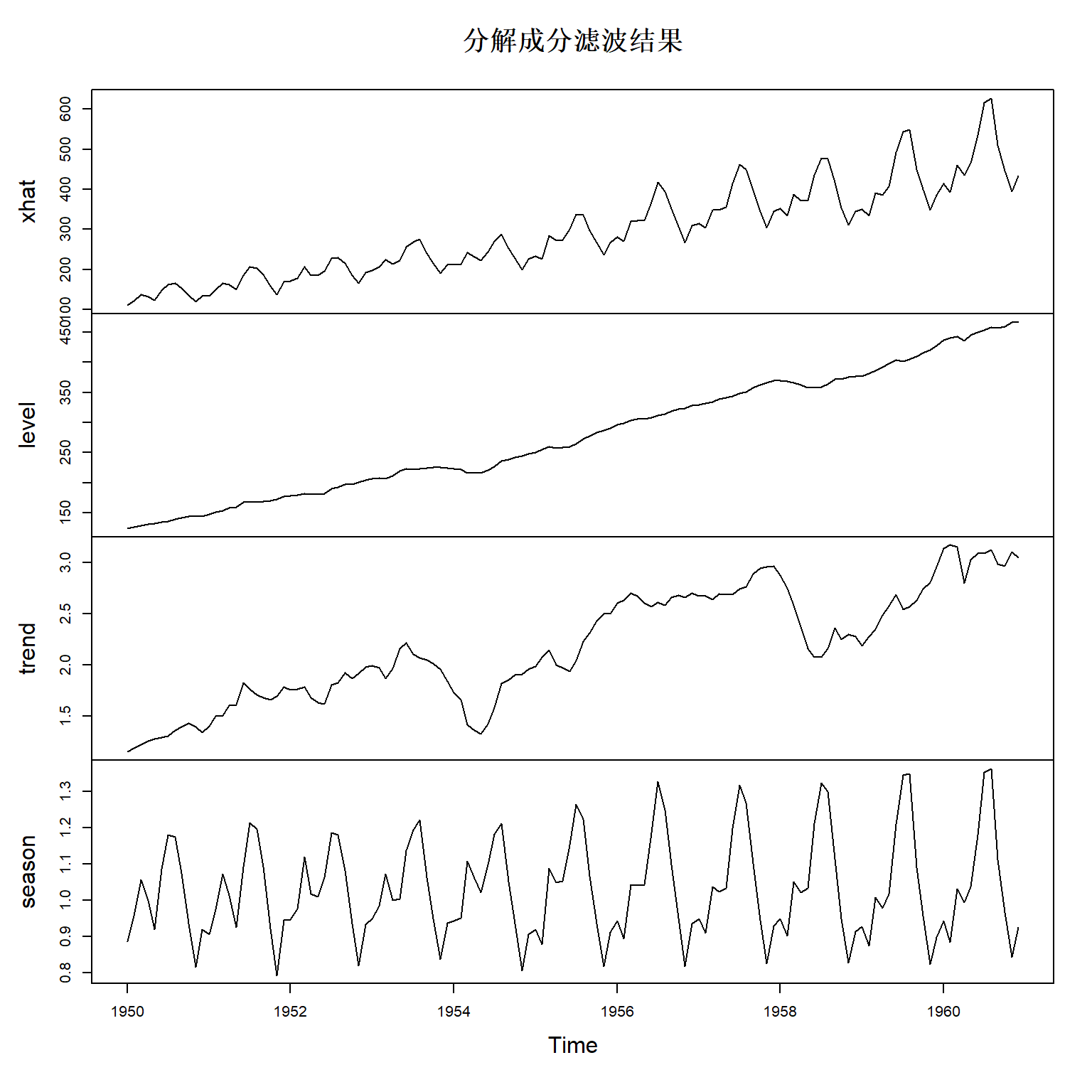
各成分为拟合值、\(l_t\)、\(b_t\)、\(s_t\)的滤波估计。
使用forecast::ets():
## ETS(M,Ad,M)
##
## Call:
## forecast::ets(y = AirPassengers)
##
## Smoothing parameters:
## alpha = 0.7096
## beta = 0.0204
## gamma = 1e-04
## phi = 0.98
##
## Initial states:
## l = 120.9939
## b = 1.7705
## s = 0.8944 0.7993 0.9217 1.0592 1.2203 1.2318
## 1.1105 0.9786 0.9804 1.011 0.8869 0.9059
##
## sigma: 0.0392
##
## AIC AICc BIC
## 1395.166 1400.638 1448.623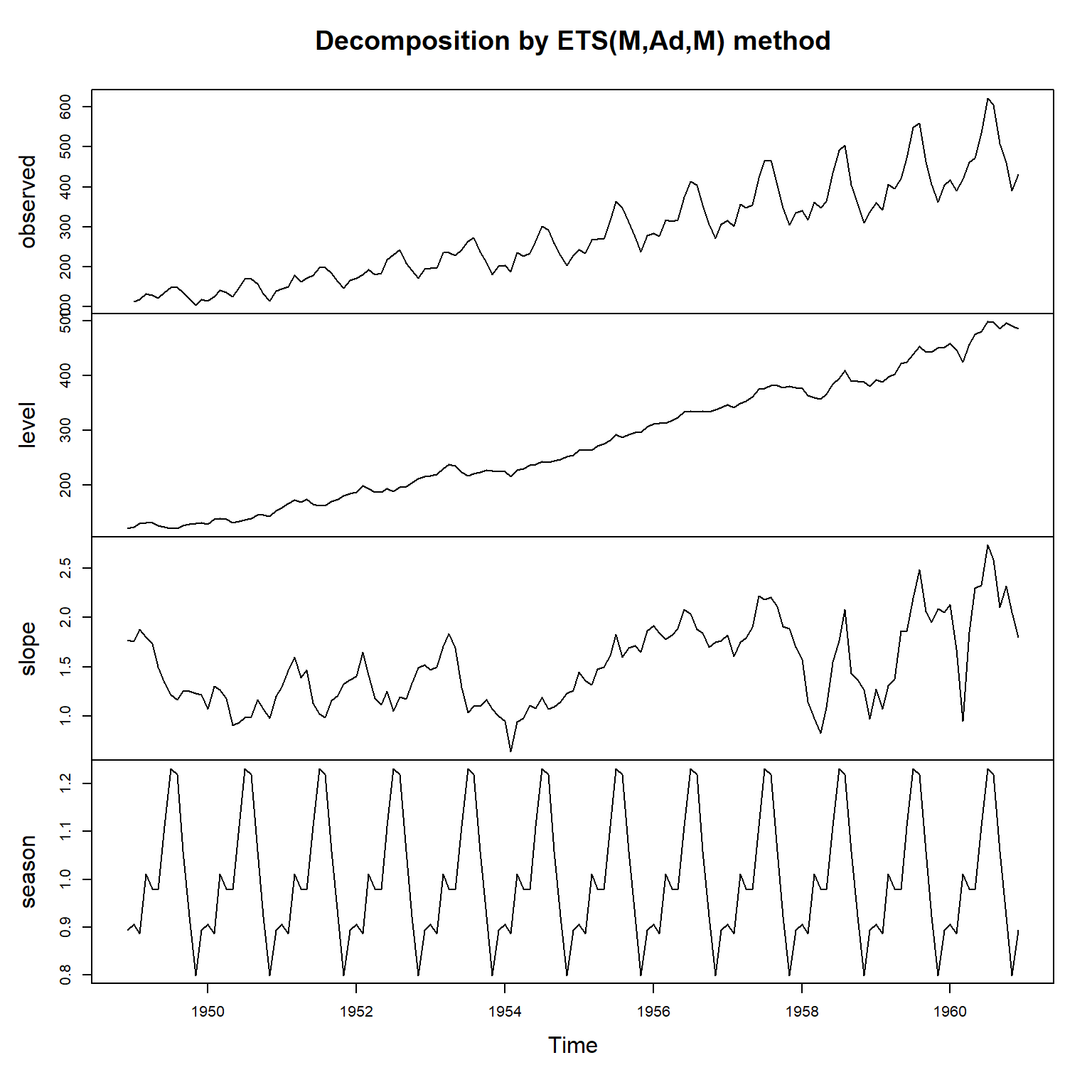
这个模型中误差项和季节项是乘性的, 趋势项是加性的。
使用StructTS():
##
## Call:
## StructTS(x = AirPassengers)
##
## Variances:
## level slope seas epsilon
## 0.00 160.98 29.85 0.00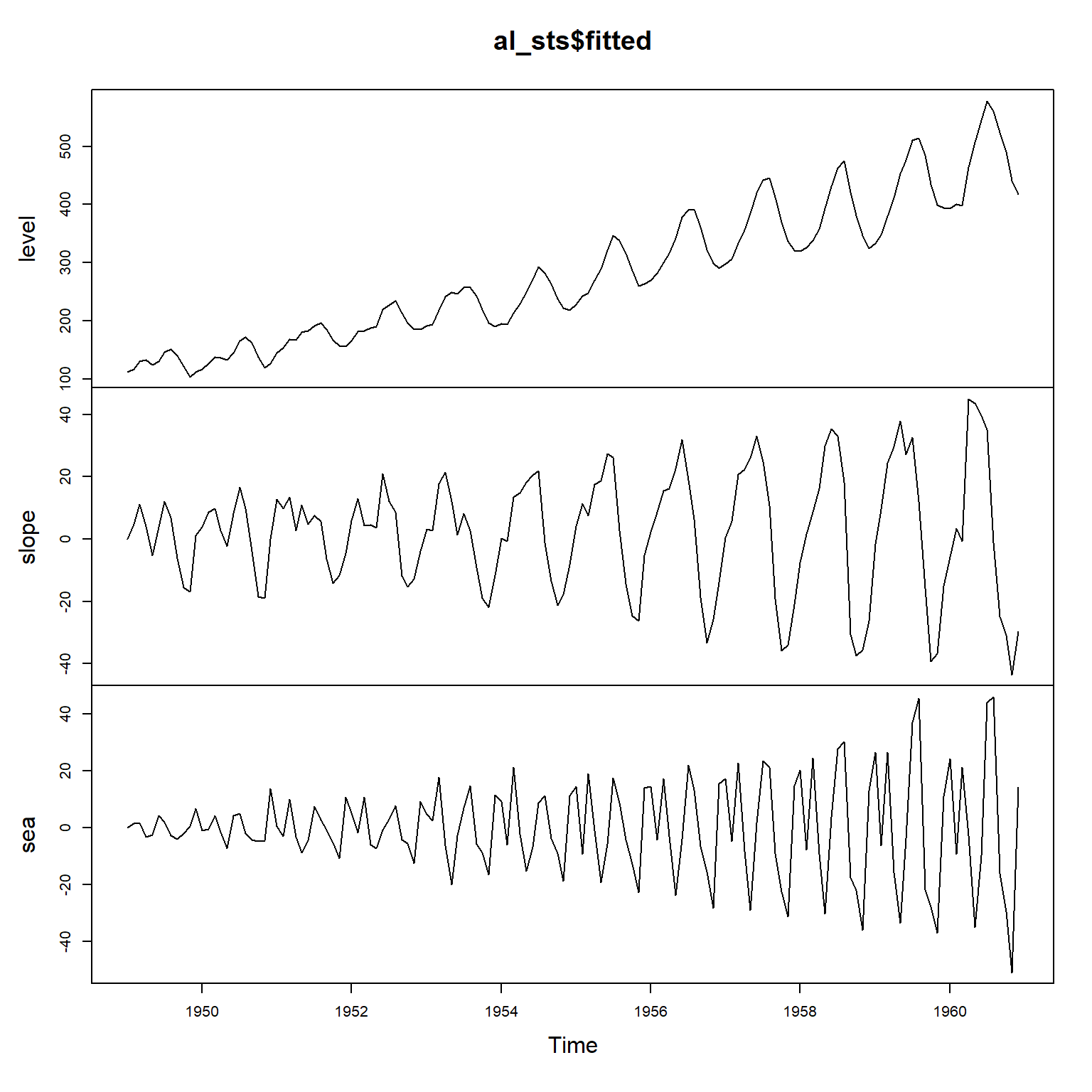
使用stl():
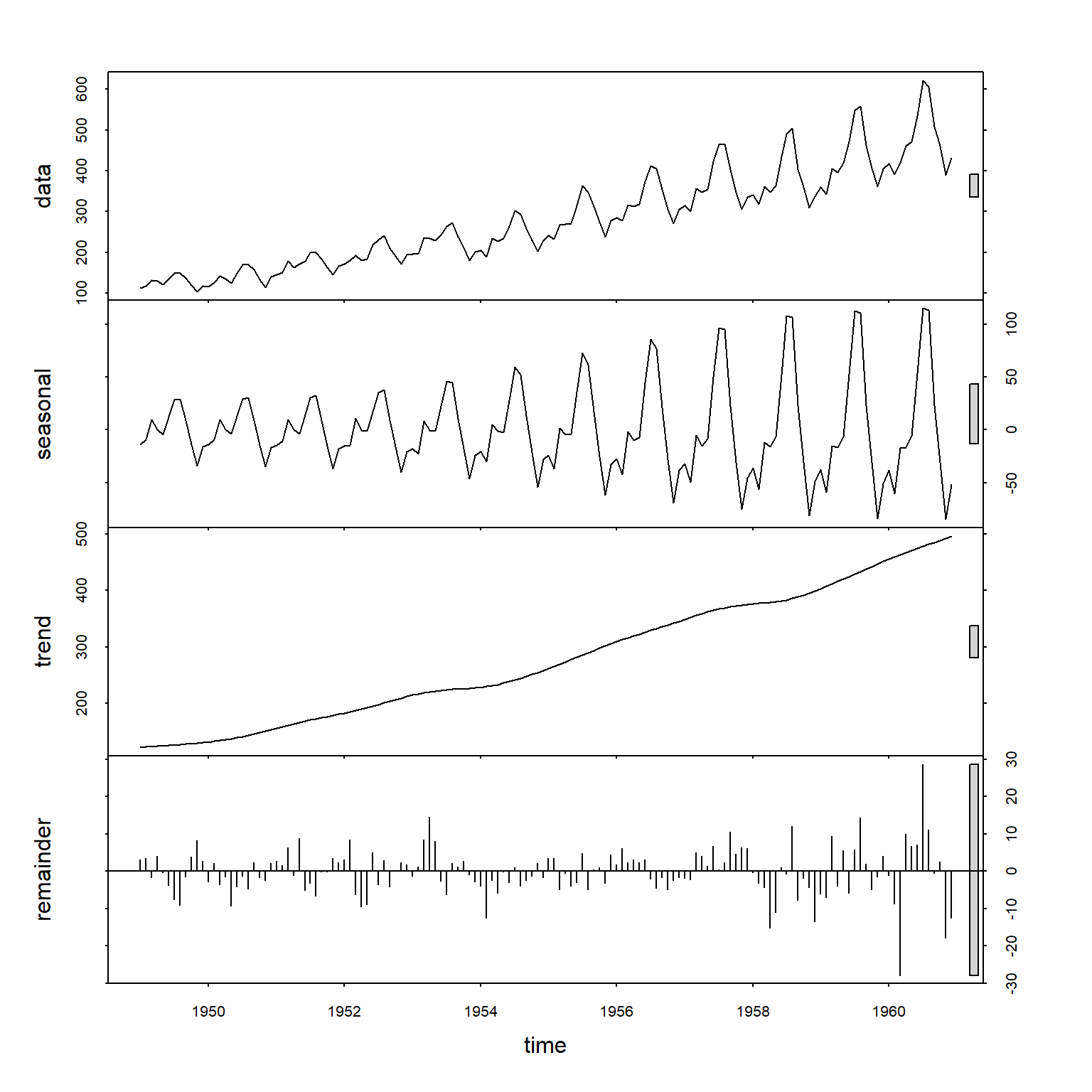
使用decompose():