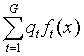 。
。判别分析的目的是对已知分类的数据建立由数值指标构成的分类规则,然后把这样的 规则应用到未知分类的样本去分类。例如,我们有了患胃炎的病人和健康人的一些化验指标 ,就可以从这些化验指标发现两类人的区别,把这种区别表示为一个判别公式,然后对怀疑 患胃炎的人就可以根据其化验指标用判别公式诊断。
判别分析的方法有参数方法和非参数方法。参数方法假定每个类的观测来自(多元) 正态分布总体,各类的分布的均值(中心)可以不同。非参数方法不要求知道各类所来自总 体的分布,它对每一类使用非参数方法估计该类的分布密度,然后据此建立判别规则。
记
![]() 为用来建立判别规则的
为用来建立判别规则的
![]() 维随机变量,
维随机变量,
![]() 为合并协方差阵估计,
为合并协方差阵估计,
![]() 为组的下标,共有
为组的下标,共有
![]() 个组。记
个组。记
![]() 为第
为第
![]() 组中训练样本的个数,
组中训练样本的个数,
![]() 为第
为第
![]() 组的自变量均值向量,
组的自变量均值向量,
![]() 为第
为第
![]() 组的协方差阵,
组的协方差阵,
![]() 为
为
![]() 的行列式,
的行列式,
![]() 为第
为第
![]() 组出现的先验概率,
组出现的先验概率,
![]() 为自变量为
为自变量为
![]() 的观测属于第
的观测属于第
![]() 组的后验概率,
组的后验概率,
![]() 为第
为第
![]() 组的分布密度在
组的分布密度在
![]() 处的值,
处的值,
![]() 为非条件密度
。
为非条件密度
。
按照Bayes理论,自变量为
![]() 的观测属于第
的观测属于第
![]() 组的后验概率
组的后验概率
![]() 。于是,可以把自变量
。于是,可以把自变量
![]() 的取值空间
的取值空间
![]() 划分为
划分为
![]() 个区域
个区域
![]() ,使得当
,使得当
![]() 的取值
的取值
![]() 属于
属于
![]() 时后验概率在第
时后验概率在第
![]() 组最大,即
组最大,即
![]()
建立的判别规则为:计算自变量
![]() 到每一个组中心的广义平方距离,并把
到每一个组中心的广义平方距离,并把
![]() 判入最近的类。广义平方距离的计算可能使
用合并的协方差阵估计或者单独的协方差阵估计,并与先验概率有关,定义为
判入最近的类。广义平方距离的计算可能使
用合并的协方差阵估计或者单独的协方差阵估计,并与先验概率有关,定义为
![]()
其中
![]()
![]()

![]() (使用单个类的协方差阵估计)或
(使用单个类的协方差阵估计)或
![]() (使用合并的协方差阵估计)。
(使用合并的协方差阵估计)。
![]() 可以用第
可以用第
![]() 组的均值
组的均值
![]() 代替。在使用合并协方差阵时,
代替。在使用合并协方差阵时,
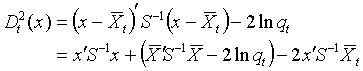
其中
![]() 是共同的可以不考虑,于是在比较
是共同的可以不考虑,于是在比较
![]() 到各组中心的广义平方距离时,只要计算线
性判别函数
到各组中心的广义平方距离时,只要计算线
性判别函数
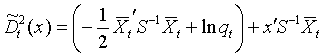 ,当
,当
![]() 到第
到第
![]() 组的线性判别函数最大时把
组的线性判别函数最大时把
![]() 对应观测判入第
对应观测判入第
![]() 组。在如果使用单个类的协方差阵估计
组。在如果使用单个类的协方差阵估计
![]() 则距离函数是
则距离函数是
![]() 的二次函数,称为二次判别函数。
的二次函数,称为二次判别函数。
后验概率可以用广义距离表示为
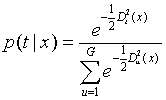
因此,参数方法的判别规则为:先决定是使用合并协方差阵还是单个类的协方差阵,计算
![]() 到各组的广义距离,把
到各组的广义距离,把
![]() 判入最近的组;或者计算
判入最近的组;或者计算
![]() 属于各组的后验概率,把
属于各组的后验概率,把
![]() 判入后验概率最大的组。如果
判入后验概率最大的组。如果
![]() 的最大的后验概率都很小(小于一个给定的
界限),则把它判入其它组。
的最大的后验概率都很小(小于一个给定的
界限),则把它判入其它组。
非参数判别方法仍使用Bayes后验概率密度的大小来进行判别,但这时第
![]() 组在
组在
![]() 处的密度值
处的密度值
![]() 不再具有参数形式,不象参数方法那样可以
用
不再具有参数形式,不象参数方法那样可以
用
![]() 和
和
![]() (或
(或
![]() )表示出来。非参数方法用核方法或最近邻
方法来估计概率密度
)表示出来。非参数方法用核方法或最近邻
方法来估计概率密度
![]() 。
。
最近邻估计和核估计也都需要定义空间中的距离。除了可以用欧氏距离外,还可以用 马氏(Mahalanobis)距离,定义为:
![]()
其中
![]() 为以下形式之一:
为以下形式之一:
![]() 合并协方差阵
合并协方差阵
![]() 合并协方差阵的对角阵
合并协方差阵的对角阵
![]() 第
第
![]() 组内的协方差阵
组内的协方差阵
![]() 第
第
![]() 组内的协方差阵的对角阵
组内的协方差阵的对角阵
![]() 单位阵,这时距离即普通欧氏距离
单位阵,这时距离即普通欧氏距离
SAS/STAT的DISCRIM过程可以进行参数判别分析和非参数判别分析,其一般格式 如下:
PROC DISCRIM DATA=输入数据集 选项; CLASS 分类变量; VAR 判别用自变量集合; RUN;
其中,PROC DISCRIM语句的选项中“输入数据集”为训练数据的数据集,包括一个分类变 量(在CLASS语句中说明)和用来建立判别公式的自变量集合(在VAR语句中说明)。可以用 “TESTDATA=数据集”选项指定一个检验数据集,检验数据集必须包含与训练数据集相同的自 变量集合,用训练数据集产生判别规则后将对检验数据集中的每一个观测给出分类值,如果 这个检验数据集中有表示真实分类的变量可以在过程中用“TESTCLASS 分类变量”语句指定 ,这样可以检验判别的效果如何。用“OUTSTAT=数据集”指定输出判别函数的数据集,后面 可以再次用DISCRIM过程把这样输出的判别函数作为输入数据集(DATA=)读入并用它来判别 检验数据(TESTDATA=)。用“OUT=数据集”指定存放训练样本及后验概率、交叉确认分类的 数据集。用“OUTD=数据集”指定训练样本及组密度估计数据集。用“TESTOUT=数据集”指定 检验数据的后验概率及分类结果。用“TESTOUTD=数据集”输出检验数据及组密度估计。
PROC DISCRIM语句还有一些指定判别分析方法的选项。用METHOD=NORMAL或NPAR选择 参数方法或非参数方法。用POOL=NO或TEST或YES表示不用合并协方差阵、通过检验决定是否 使用合并协方差阵、用合并协方差阵。如果使用非参数方法,需要指定“R=核估计半径”选 项来规定核估计方法或者指定“K=最近邻个数”来规定最近邻估计方法。
PROC DISCRIM语句有一些规定显示结果的选项。用LISTERR显示训练样本错判的观测 。用CROSLISTERR显示用交叉核实方法对训练样本判别错判的观测。用LIST对每一观测显示结 果。用NOCLASSIFY取消对训练样本的分类检验。用CROSSLIST显示对训练样本的交叉核实的判 别结果。用CROSSVALIDATE要求进行交叉核实。当有用“TESTDATA=”指定的检验数据集时用TESTLIST 选项显示检验数据集的检验结果,当有TESTCLASS语句时用TESTLISTERR可以列出检验样本判 错的观测,用POSTERR选项可以打印基于分类结果的分类准则的后验概率错误率估计。用NOPRINT 选项可以取消结果的显示。
在DISCRIM过程中还可以使用PRIORS语句指定先验概率
![]() 的取法。“PRIORS EQUAL”指定等先验概率
。“PRIORS PROPORTIONAL”指定先验概率与各类个数成正比。“PRIORS 概率值表”可以直
接指定各组的先验概率值。
的取法。“PRIORS EQUAL”指定等先验概率
。“PRIORS PROPORTIONAL”指定先验概率与各类个数成正比。“PRIORS 概率值表”可以直
接指定各组的先验概率值。
用卫星遥感可以分辨作物的种类。CROPS是训练数据集,其中包含了作物的实际 种类(CROP)和四种遥感指标变量(X1-X4)。数据集中还把各X1-X4变量值作为一个字符型 变量读入来作为行标识。
data crops; title '五种作物遥感数据的判别分析'; input crop $ 1-10 x1-x4 xvalues $ 11-21; cards; CORN 16 27 31 33 CORN 15 23 30 30 CORN 16 27 27 26 CORN 18 20 25 23 CORN 15 15 31 32 CORN 15 32 32 15 CORN 12 15 16 73 SOYBEANS 20 23 23 25 SOYBEANS 24 24 25 32 SOYBEANS 21 25 23 24 SOYBEANS 27 45 24 12 SOYBEANS 12 13 15 42 SOYBEANS 22 32 31 43 COTTON 31 32 33 34 COTTON 29 24 26 28 COTTON 34 32 28 45 COTTON 26 25 23 24 COTTON 53 48 75 26 COTTON 34 35 25 78 SUGARBEETS22 23 25 42 SUGARBEETS25 25 24 26 SUGARBEETS34 25 16 52 SUGARBEETS54 23 21 54 SUGARBEETS25 43 32 15 SUGARBEETS26 54 2 54 CLOVER 12 45 32 54 CLOVER 24 58 25 34 CLOVER 87 54 61 21 CLOVER 51 31 31 16 CLOVER 96 48 54 62 CLOVER 31 31 11 11 CLOVER 56 13 13 71 CLOVER 32 13 27 32 CLOVER 36 26 54 32 CLOVER 53 08 06 54 CLOVER 32 32 62 16 ; run;
用下列DISCRIM过程可以产生线性判别函数(METHOD=NORMAL规定使用参数方法,POOL=YES 选项规定使用合并协方差阵,这样产生的判别函数是线性函数)。用OUTSTAT=选项指定了判 别函数的输出数据集为CROPSTAT,这个数据集可以用来判别检验数据集。选项LIST要求列出 每个观测的结果,CROSSVALIDATE要求交叉核实。“PRIORS PROPORTIONAL”即按各种类出现 的比例计算各类的先验概率,ID语句指定列出各观测时以什么变量值作为标识。
proc discrim data=crops outstat=cropstat
method=normal pool=yes
list crossvalidate;
class crop;
priors proportional;
id xvalues;
var x1-x4;
title2 '使用线性判别函数';
run;
结果如下(节略):
Discriminant Analysis
36 Observations 35 DF Total
4 Variables 31 DF Within Classes
5 Classes 4 DF Between Classes
上面是一些基本情况。
Class Level Information
Prior
CROP Frequency Weight Proportion Probability
CLOVER 11 11.0000 0.305556 0.305556
CORN 7 7.0000 0.194444 0.194444
COTTON 6 6.0000 0.166667 0.166667
SOYBEANS 6 6.0000 0.166667 0.166667
SUGARBEETS 6 6.0000 0.166667 0.166667
以上为各组的基本情况,并列出了先验概率值。因为指定了“PRIORS PROPORTIONAL”所 以各组的先验概率按实际数据中各组比例计算。
Discriminant Analysis Pairwise Generalized Squared Distances Between Groups
2 _ _ -1 _ _
D (i|j) = (X - X )' COV (X - X ) - 2 ln PRIOR
i j i j j
上面为各组均值间广义距离平方的公式,即
![]() 。
。
_ -1 _ -1 _
Constant = -.5 X' COV X + ln PRIOR Coefficient Vector = COV X
j j j j
上面即线性判别函数的公式,给出了到第j类的线性判别函数的常数项和各自变量的系数 的公式。下面具体给出了各类的线性判别函数的各常数项及系数值。
CROP
CLOVER CORN COTTON SOYBEANS SUGARBEETS
CONSTANT -10.98457 -7.72070 -11.46537 -7.28260 -9.80179
X1 0.08907 -0.04180 0.02462 0.0000369 0.04245
X2 0.17379 0.11970 0.17596 0.15896 0.20988
X3 0.11899 0.16511 0.15880 0.10622 0.06540
X4 0.15637 0.16768 0.18362 0.14133 0.16408
比如,观测了X1-X4后到CLOVER(苜蓿)类的线性判别函数就可以用 -10.98457+0.08907*X1+0.17379*X2+0.11899*X3+0.15637*X4 来计算。下面为判别分析对训练数据集(Calibration Data)用线性判别函数的判别结果, 先给出了广义平方距离函数的公式
Discriminant Analysis Classification Results for Calibration Data: WORK.CROPS
Resubstitution Results using Linear Discriminant Function
Generalized Squared Distance Function:
2 _ -1 _
D (X) = (X-X )' COV (X-X ) - 2 ln PRIOR
j j j j
然后是每个观测属于各类的后验概率的公式:
Posterior Probability of Membership in each CROP:
2 2
Pr(j|X) = exp(-.5 D (X)) / SUM exp(-.5 D (X))
j k k
下面就是每个观测的判别情况,包括原来为哪一类(From CROP),分入了哪一类(Classified into CROP),即属于各类的后验概率值。有星号的为错判的观测。
Posterior Probability of Membership in
CROP:
XVALUES From Classified
CROP into CROP CLOVER CORN COTTON SOYBEANS SUGARBEETS
16 27 31 33 CORN CORN 0.0894 0.4054 0.1763 0.2392 0.0897
15 23 30 30 CORN CORN 0.0769 0.4558 0.1421 0.2530 0.0722
16 27 27 26 CORN CORN 0.0982 0.3422 0.1365 0.3073 0.1157
18 20 25 23 CORN CORN 0.1052 0.3634 0.1078 0.3281 0.0955
15 15 31 32 CORN CORN 0.0588 0.5754 0.1173 0.2087 0.0398
15 32 32 15 CORN SOYBEANS * 0.0972 0.3278 0.1318 0.3420 0.1011
12 15 16 73 CORN CORN 0.0454 0.5238 0.1849 0.1376 0.1083
20 23 23 25 SOYBEANS SOYBEANS 0.1330 0.2804 0.1176 0.3305 0.1385
24 24 25 32 SOYBEANS SOYBEANS 0.1768 0.2483 0.1586 0.2660 0.1502
21 25 23 24 SOYBEANS SOYBEANS 0.1481 0.2431 0.1200 0.3318 0.1570
27 45 24 12 SOYBEANS SUGARBEETS * 0.2357 0.0547 0.1016 0.2721 0.3359
12 13 15 42 SOYBEANS CORN * 0.0549 0.4749 0.0920 0.2768 0.1013
22 32 31 43 SOYBEANS COTTON * 0.1474 0.2606 0.2624 0.1848 0.1448
31 32 33 34 COTTON CLOVER * 0.2815 0.1518 0.2377 0.1767 0.1523
29 24 26 28 COTTON SOYBEANS * 0.2521 0.1842 0.1529 0.2549 0.1559
34 32 28 45 COTTON CLOVER * 0.3125 0.1023 0.2404 0.1357 0.2091
26 25 23 24 COTTON SOYBEANS * 0.2121 0.1809 0.1245 0.3045 0.1780
53 48 75 26 COTTON CLOVER * 0.4837 0.0391 0.4384 0.0223 0.0166
34 35 25 78 COTTON COTTON 0.2256 0.0794 0.3810 0.0592 0.2548
22 23 25 42 SUGARBEETS CORN * 0.1421 0.3066 0.1901 0.2231 0.1381
25 25 24 26 SUGARBEETS SOYBEANS * 0.1969 0.2050 0.1354 0.2960 0.1667
34 25 16 52 SUGARBEETS SUGARBEETS 0.2928 0.0871 0.1665 0.1479 0.3056
54 23 21 54 SUGARBEETS CLOVER * 0.6215 0.0194 0.1250 0.0496 0.1845
25 43 32 15 SUGARBEETS SOYBEANS * 0.2258 0.1135 0.1646 0.2770 0.2191
26 54 2 54 SUGARBEETS SUGARBEETS 0.0850 0.0081 0.0521 0.0661 0.7887
12 45 32 54 CLOVER COTTON * 0.0693 0.2663 0.3394 0.1460 0.1789
24 58 25 34 CLOVER SUGARBEETS * 0.1647 0.0376 0.1680 0.1452 0.4845
87 54 61 21 CLOVER CLOVER 0.9328 0.0003 0.0478 0.0025 0.0165
51 31 31 16 CLOVER CLOVER 0.6642 0.0205 0.0872 0.0959 0.1322
96 48 54 62 CLOVER CLOVER 0.9215 0.0002 0.0604 0.0007 0.0173
31 31 11 11 CLOVER SUGARBEETS * 0.2525 0.0402 0.0473 0.3012 0.3588
56 13 13 71 CLOVER CLOVER 0.6132 0.0212 0.1226 0.0408 0.2023
32 13 27 32 CLOVER CLOVER 0.2669 0.2616 0.1512 0.2260 0.0943
36 26 54 32 CLOVER COTTON * 0.2650 0.2645 0.3495 0.0918 0.0292
53 08 06 54 CLOVER CLOVER 0.5914 0.0237 0.0676 0.0781 0.2392
32 32 62 16 CLOVER COTTON * 0.2163 0.3180 0.3327 0.1125 0.0206
* Misclassified observation
下面给出了训练数据判别的概况,先写出了广义平方距离的公式和属于每一类的后验 概率的公式(略),然后是每一类判入各类的个数和百分比:
Discriminant Analysis Classification Summary for Calibration Data: WORK.CROPS
Resubstitution Summary using Linear Discriminant Function
Number of Observations and Percent Classified into CROP:
From CROP CLOVER CORN COTTON SOYBEANS SUGARBEETS Total
CLOVER 6 0 3 0 2 11
54.55 0.00 27.27 0.00 18.18 100.00
CORN 0 6 0 1 0 7
0.00 85.71 0.00 14.29 0.00 100.00
COTTON 3 0 1 2 0 6
50.00 0.00 16.67 33.33 0.00 100.00
SOYBEANS 0 1 1 3 1 6
0.00 16.67 16.67 50.00 16.67 100.00
SUGARBEETS 1 1 0 2 2 6
16.67 16.67 0.00 33.33 33.33 100.00
Total 10 8 5 8 5 36
Percent 27.78 22.22 13.89 22.22 13.89 100.00
Priors 0.3056 0.1944 0.1667 0.1667 0.1667
比如,CLOVER一共有11个观测,正确判别的为6个,占54.55,有3个错判为COTTON(棉花 ),2个错判为SUGARBEETS(甜菜)。最后一行为各类的先验概率。下面为各类的错判率(把 某类错判为其它类的次数百分比):
Error Count Estimates for CROP:
CLOVER CORN COTTON SOYBEANS SUGARBEETS Total
Rate 0.4545 0.1429 0.8333 0.5000 0.6667 0.5000
Priors 0.3056 0.1944 0.1667 0.1667 0.1667
可见识别最好的是玉米,最差的是棉花。
下面是对训练数据集进行交叉核实判别的情况。交叉核实的想法是,为了判断观测i
的判别正确与否,用删除第i个观测的训练数据集算出判别规则(函数),然后用此判别函数
来判别第i观测。对每一观测都进行这样的判别。结果先写出了广义平方距离函数,这里因为
建立判别规则时不使用要判别的观测,所以公式中用了
![]() 表示除去了X所在观测后的第j组的均值,用
表示除去了X所在观测后的第j组的均值,用
![]() 表示除去X所在观测后得到的合并协方差阵
估计。
表示除去X所在观测后得到的合并协方差阵
估计。
Discriminant Analysis Classification Summary for Calibration Data: WORK.CROPS
Cross-validation Summary using Linear Discriminant Function
Generalized Squared Distance Function:
2 _ -1 _
D (X) = (X-X )' COV (X-X ) - 2 ln PRIOR
j (X)j (X) (X)j j
Posterior Probability of Membership in each CROP:
2 2
Pr(j|X) = exp(-.5 D (X)) / SUM exp(-.5 D (X))
j k k
后面是对各类交叉核实判别的概况。
From CROP CLOVER CORN COTTON SOYBEANS SUGARBEETS Total
CLOVER 4 3 1 0 3 11
36.36 27.27 9.09 0.00 27.27 100.00
CORN 0 4 1 2 0 7
0.00 57.14 14.29 28.57 0.00 100.00
COTTON 3 0 0 2 1 6
50.00 0.00 0.00 33.33 16.67 100.00
SOYBEANS 0 1 1 3 1 6
0.00 16.67 16.67 50.00 16.67 100.00
SUGARBEETS 2 1 0 2 1 6
33.33 16.67 0.00 33.33 16.67 100.00
Total 9 9 3 9 6 36
Percent 25.00 25.00 8.33 25.00 16.67 100.00
Priors 0.3056 0.1944 0.1667 0.1667 0.1667
这一次11个苜蓿的观测只判对了4个。下面是用交叉核实计算的各类的错判率:
Error Count Estimates for CROP:
CLOVER CORN COTTON SOYBEANS SUGARBEETS
Total
Rate 0.6364 0.4286 1.0000 0.5000 0.8333 0.6667
Priors 0.3056 0.1944 0.1667 0.1667 0.1667
这时错误最少的玉米也有43%的错判率。
现在假设我们有若干遥感数据放在了数据集TEST中,实际是已知作物类型的(在变量CROP 中),但是我们假装不知道然后用上面建立的线性判别函数(已保存在CROPSTAT数据集中) 对这些遥感数据进行判别,这样可以得到比较客观的判别效果的评价。下面程序中用DATA=指 定了判别函数数据集(由上一次的DISCRIM过程产生),用TESTDATA=选项指定了检验数据集 名,用TESTOUT=选项指定了检验数据集判别结果的输出数据集,用TESTLIST要求列出检验结 果。TESTID语句指定检验数据集的各观测用什么变量的值来标识。
data test;
input crop $ 1-10 x1-x4 xvalues $ 11-21;
cards;
CORN 16 27 31 33
SOYBEANS 21 25 23 24
COTTON 29 24 26 28
SUGARBEETS54 23 21 54
CLOVER 32 32 62 16
;
proc discrim data=cropstat testdata=test testout=tout
testlist;
class crop;
testclass crop;
testid xvalues;
var x1-x4;
title2 '检验数据的判别';
run;
proc print data=tout;
title2 'Output Classification Results of Test Data';
run;
结果列出了每个观测的判别结果和判入每类的后验概率,因为我们知道真实类,所以 结果中有一项是“From CROP”,如果不知道真实类则只能给出判入的类(Classified into CROPP)。
Discriminant Analysis Classification Results for Test Data: WORK.TEST
Classification Results using Linear Discriminant Function
Posterior Probability of Membership in CROP:
XVALUES From Classified
CROP into CROP CLOVER CORN COTTON SOYBEANS SUGARBEETS
16 27 31 33 CORN CORN 0.0894 0.4054 0.1763 0.2392 0.0897
21 25 23 24 SOYBEANS SOYBEANS 0.1481 0.2431 0.1200 0.3318 0.1570
29 24 26 28 COTTON SOYBEANS * 0.2521 0.1842 0.1529 0.2549 0.1559
54 23 21 54 SUGARBEETS CLOVER * 0.6215 0.0194 0.1250 0.0496 0.1845
32 32 62 16 CLOVER COTTON * 0.2163 0.3180 0.3327 0.1125 0.0206
下面给出了各类的判别概况(略)。下面列出了错判的百分比。
Error Count Estimates for CROP:
CLOVER CORN COTTON SOYBEANS SUGARBEETS Total
Rate 1.0000 0.0000 1.0000 0.0000 1.0000 0.6389
Priors 0.3056 0.1944 0.1667 0.1667 0.1667
可见错判率很高(总错判率达64%)。