前面我们已经看到了SAS的编程计算、数据管理能力、数据汇总、数据探索分析能力。这 一章我们讲如何用SAS进行基本的统计检验、线性回归、方差分析、列联表检验等基本统计分 析。我们既使用SAS语言编程,也使用SAS/INSIGHT的菜单界面。
对单个变量,我们可能需要作正态性检验、两独立样本均值相等的检验、成对样本均 值相等的检验。
在PROC UNIVARIATE语句中加上NORMAL选项可以进行正态性检验。例如,我们要检验SASUSER.GPA 中GPA是否服从正态分布,只要用如下UNIVARIATE过程:
proc univariate data=sasuser.gpa normal;
var gpa;
run;
结果(部分)如下:
Univariate Procedure
Variable=GPA College Grade Point Average
Moments
…………
W:Normal 0.951556 Pr<W 0.0001
…………
其中W:Normal为Shapiro-Wilk正态性检验统计量,Pr<W为检验的显著性概率值(p值) 。当N≤2000时正态性检验用Shapiro-Wilk统计量,N>2000时用Kolmogorov D统计量。我 们可以看到,p值很小,所以在0.05水平(或0.10水平)下应拒绝零假设,即认为GPA分布非 正态。
在SAS/INSIGHT中为了检验GPA的分布,先选“Analyze | Distribution”菜单打开GPA 变量的分布窗口,然后选“Curves | Test for Distribution”菜单。除了可以检验是否正 态分布外还可以检验是否对数正态、指数分布、Weibull分布。
假设我们有两组样本分别来自两个独立总体,需要检验两个总体的均值或中心位置是 否一样。如果两个总体都分别服从正态分布,而且方差相等,可以使用两样本t检验过程TTEST 。
比如,我们要检验SASUSER.GPA数据集中男生和女生的SATM分数是否具有相等的平均值, 只要用如下程序:
proc ttest data=sasuser.gpa;
class sex;
var satm;
run;
过程中用CLASS语句指定分组变量,用VAR语句指定要比较的变量。结果如下:
TTEST PROCEDURE
Variable: SATM Math SAT Score
SEX N Mean Std Dev Std Error
-----------------------------------------------------------------------------
Female 145 611.77241379 84.02056171 6.97752786
Male 79 565.02531646 82.92937599 9.33028376
Variances T DF Prob>|T|
---------------------------------------
Unequal 4.0124 162.2 0.0001
Equal 3.9969 222.0 0.0001
For H0: Variances are equal, F' = 1.03 DF = (144,78) Prob>F' = 0.9114
结果有三个部分:两个总体的SATM简单统计量,两样本均值的检验,以及两样本方差是否 相等的检验。标准的两样本t检验要求两总体方差相等,所以第三部分结果检验两样本方差是 否相等。如果检验的结果为相等,则可使用精确的两样本t检验,看第二部分结果的Equal那 一行。如果方差检验的结果为不等,则只能使用近似的两样本t检验,看第二部分结果的Unequal 那一行。这里我们看到方差检验的p值为0.9114不显著,所以可以认为方差相等,所以我们看Equal 行,p值为0.0001在0.05水平下是显著的,所以应认为男、女生的SATM分数有显著差异,女生 分数要高。
上面的检验中对立假设是两组的均值不等,所以检验是双边的,p值的计算公式为Pr(t 分布随机变量绝对值>计算得到的t统计量的绝对值)。如果要进行单边的检验,比如对立 假设为女生分数高于男生分数(右边),则p值为Pr(t分布随机变量>计算得到的t统计量) ,当计算得到的t统计量值为正数时(现在t=4.0)此单边p值为双边p值的一半,当计算得到 的t统计量为负数时肯定不能否定零假设。检验左边时恰好相反。
如果我们希望检验男、女生的GPA分数则无法使用两样本t检验,因为检验女生的GPA 样本的正态性发现它非正态。这种情况下我们可以使用非参数检验。检验两独立样本的位置 是否相同的非参数检验有Wilcoxon秩和检验。我们用NPAR1WAY过程加Wilcoxon选项可以进行 这种检验。见下例:
proc npar1way data=sasuser.gpa wilcoxon; class sex; var gpa; run;
其CLASS语句和VAR与TTEST过程相同。结果如下:
N P A R 1 W A Y P R O C E D U R E
Wilcoxon Scores (Rank Sums) for Variable GPA
Classified by Variable SEX
Sum of Expected Std Dev Mean
SEX N Scores Under H0 Under H0 Score
Female 145 16067.5000 16312.5000 463.429146 110.810345
Male 79 9132.5000 8887.5000 463.429146 115.601266
Average Scores Were Used for Ties
Wilcoxon 2-Sample Test (Normal Approximation)
(with Continuity Correction of .5)
S = 9132.50 Z = 0.527589 Prob > |Z| = 0.5978
T-Test Approx. Significance = 0.5983
Kruskal-Wallis Test (Chi-Square Approximation)
CHISQ = 0.27949 DF = 1 Prob > CHISQ = 0.5970
结果分为四部分:两样本的秩和的有关统计量,Wilcoxon两样本检验的结果,t检验的近 似显著性,Kruskal-wallis检验结果。我们只要看Wilcoxon检验的p值Prob > |Z| = 0.5978 ,检验结果不显著,可认为男、女生的GPA分数在0.05水平下无显著差异。
SAS/INSIGHT中未提供两独立样本检验的功能。
我们在现实中经常遇到两个总体是相关的测量结果的比较,比如,考察同一组人在参 加一年的长跑锻炼前后的心率有无显著差异。这时,每个人一年前的心率和一年后的心率是 相关的,心率本来较快的人锻炼后仍相对于其它人较快。所以,检验这样的成对总体的均值 不能使用两样本t检验的方法,因为独立性条件不再满足。这时,我们可以检验两个变量间的 差值的均值是否为零,这等价于检验两组测量值的平均水平有无显著差异。
检验单个样本的均值是否为零只要使用UNIVARIATE过程,在UNIVARIATE过程的矩部分给出 了均值为零的t检验和符号检验、符号秩检验的结果。例如,我们想知道SATM和SATV这两门考 试的成绩有无显著差异(SATM平均值为595.3,SASTV平均值为504.6,我们希望知道差异是否 显著)。因为这两个成绩是同一个学生的成绩,所以它们之间是相关的(学得好的学生两科 一般都好,学得差的一般两科都差),不能用独立两样本的t检验,但可以计算两变量间的差DMV =SATM-SATV,检验差值变量的均值是否为零。如果否定,则可认为SATM和SATV的平均值有 显著差异。
为此,我们先用一个数据步计算差值,然后对差值变量用UNIVARIATE过程进行分析就可以 得到结果。程序如下:
data new; set sasuser.gpa; dmv = satm - satv; keep dmv; run; proc univariate data=new; var dmv; run;
结果(部分)如下:
Univariate Procedure
Variable=DMV
Moments
N 224 Sum Wgts 224
Mean 90.73661 Sum 20325
Std Dev 92.82931 Variance 8617.28
Skewness -0.10367 Kurtosis -0.34625
USS 3765875 CSS 1921653
CV 102.3063 Std Mean 6.202419
T:Mean=0 14.62923 Pr>|T| 0.0001
Num ^= 0 215 Num > 0 181
M(Sign) 73.5 Pr>=|M| 0.0001
Sgn Rank 9757.5 Pr>=|S| 0.0001
我们只要看其中的三个检验:T: Mean=0是假定差值变量服从正态分布时检验均值为零的t 统计量值,相应的p值Pr>|T|为0.0001在0.05水平下是显著的,所以可认为两科分数有显 著差异。M(Sign)是非参数检验符号检验的统计量,其p值Pr>=|M|为0.0001在0.05水平下 是显著的,结论不变。Sgn Rank是非参数检验符号秩检验的统计量,其p值Pr>=|S|为0.0001 在0.05水平下是显著的,结论不变。所以这三个检验的结论都是两科成绩有显著差异。
如果t检验对立假设是单边的,其p值算法与上面讲的两样本t检验p值算法相同。
在SAS/INSIGHT中比较成对样本均值的显著差异,同样是先计算两变量的差值变量( 在“Edit | Variables | Other”菜单中,指定两个变量,指定两个变量间的计算为减法, 则可以生成差值变量,可以用数据窗口菜单的“Define Variables”改变量名),然后对此 差值变量选“Analyze | Distribution”,选“Tables | Location Tests”并选中t检验、 符号检验和符号秩检验即可在分布窗口显示结果。
本节先讲述如何用SAS/INSIGHT进行曲线拟合,然后进一步讲如何用SAS/INSIGHT进行 线性回归,简单介绍SAS/INSIGHT的广义线性模型拟合,最后介绍如何用编程进行回归分析。
两个变量Y和X之间的相关关系经常可以用一个函数来表示,一元函数可以等同于一条 曲线,实际工作中经常对两个变量拟合一条曲线来近似它们的相关关系。最基本的“曲线” 是直线,还可以用多项式、样条函数、核估计和局部多项式估计。其模型可表示为
![]()
例如,我们要研究SASUSER.CLASS数据集中学生体重与身高之间的相关关系。为此, 我们可以先画出两者的散点图(Analyze | Scatter plot)。从图中可以看出,身高越高的 人一般体重越重。我们可以把体重作为因变量、身高作为自变量拟合一条回归直线,只要选 “Analyze | Fit (Y X)”,并选体重为Y变量,身高为X变量,即可自动拟合出一条回归直线 ,见图 1。窗口中还给出了拟合的模型方程、参数估计、诊断信息等,我们在下一小节再详 细介绍。
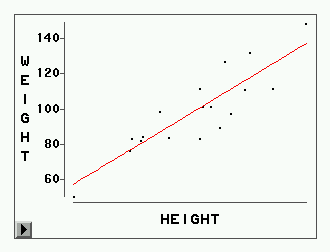
在拟合了直线后,为拟合多项式曲线,只要选“Curves | Polynomial”,然后输入 阶次(Degree(Polynomial)),就可以在散点图基础上再加入一条多项式曲线。对于本例, 我们看到二次多项式得到的曲线与直线差别很小,所以用二次多项式拟合没有优势。还可以 试用三次、四次等多项式。为了改变阶次还可以使用拟合窗口中的多项式阶次滑块(Parametric Regression Fit中的Degree(Polynomial))。
样条曲线是一种非参数回归的曲线拟合方法。光滑样条为分段的三次多项式,曲线在 每一段内是一个三次多项式,在两段的连接点是连续、光滑的。为拟合样条曲线,只要选“Curves | Spline”,使用缺省的GCV准则(广义交叉核实)来选取光滑系数(光滑系数c越大,得到 的曲线越光滑,但拟合同时变差,光滑系数c小的时候得到的曲线较曲折,而拟合较好),就 可以在散点图的基础上画出样条曲线。可以用光滑系数c的滑块来调整曲线的光滑程度/拟合 优度。对于本例,GCV准则得到的样条曲线与回归直线几乎是重合的,说明直线拟合可以得到 满意的结果。
核估计是另一种非参数回归的曲线拟合方法。它定义了一个核函数
![]() ,例如使用标准正态分布密度曲线,然后用
如下公式估计经验公式
,例如使用标准正态分布密度曲线,然后用
如下公式估计经验公式
![]() :
:
![]()

其中
![]() 为光滑系数,
为光滑系数,
![]() 越大得到的曲线越光滑。为了画核估计曲线
,只要选“Curves | Kernel”,权重函数使用缺省的正态核,选取光滑系数的方法采用缺省
的GCV法,就可以把核估计图附加到散点图上。本例得到的核估计曲线与回归直线、样条曲线
有一定差别。可以手动调整光滑系数
越大得到的曲线越光滑。为了画核估计曲线
,只要选“Curves | Kernel”,权重函数使用缺省的正态核,选取光滑系数的方法采用缺省
的GCV法,就可以把核估计图附加到散点图上。本例得到的核估计曲线与回归直线、样条曲线
有一定差别。可以手动调整光滑系数
![]() 的值,可以看到,当
的值,可以看到,当
![]() 过大时曲线不仅变光滑而且越来越变水平,
因为这时的拟合值基本是一个常数,这与样条曲线的情形不同,样条曲线当
过大时曲线不仅变光滑而且越来越变水平,
因为这时的拟合值基本是一个常数,这与样条曲线的情形不同,样条曲线当
![]() 增大时曲线变光滑但不趋向于常数(水平线
)。
增大时曲线变光滑但不趋向于常数(水平线
)。
局部多项式估计(Loess)是另一种非参数回归的曲线拟合方法。它在每一自变量值处拟 合一个局部多项式,可以是零阶、一阶、二阶,零阶时与核估计相同。SAS/INSIGHT缺省使用 一阶(线性)局部多项式。改变Loess的系数alpha可以改变曲线的光滑度。alpha增大时曲线 变光滑,而且使用一阶或二阶多项式时曲线不会同时变水平。
固定带宽的局部多项式是另一种局部多项式拟合方法。它有一个光滑系数c。
上面我们已经看到,用菜单“Analyze | Fit (Y X)”就可以拟合一条回归直线,这 是对回归方程
![]()
的估计结果。这样的线性回归可以推广到一个因变量、多个自变量的情况。线性模型写成 矩阵形式为
![]()
下面列出了线性模型中常用的一些量和结论:
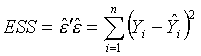
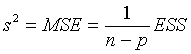
 (其中
(其中
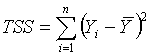 ),它代表在因变量的变差中用模型能够
解释的部分的比例,所以
),它代表在因变量的变差中用模型能够
解释的部分的比例,所以
例如,我们在“Fit (Y X)”的选择变量窗口选Y变量(因变量)为体重(WEIGHT),选X 变量(自变量)为身高(HEIGHT)和年龄(AGE),则可以得到体重对身高、年龄的线性回归 结果。下面对基本结果进行说明。
回归基本模型:
WEIGHT = HEIGHT AGE
Response Distribution: Normal
Link Function: Identity
回归模型方程:
Model Equation
WEIGHT = - 141.2238 + 3.5970 HEIGHT + 1.2784 AGE
拟合概况:
Summary of Fit
Mean of Response 100.0263 R-Square 0.7729
Root MSE 11.5111 Adj R-Sq 0.7445
其中Mean of Response为因变量(Response)的均值,Root MSE叫做根均方误差,是均方
误差的平方根,R-Square即复相关系数平方,Adj R-Sq为修正的复相关系数平方,其公式为
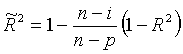 ,其中
,其中
![]() 当有截距项时取1,否则取0,这个公式考虑
到了自变量个数
当有截距项时取1,否则取0,这个公式考虑
到了自变量个数
![]() 的多少对拟合的影响,原来的
的多少对拟合的影响,原来的
![]() 随着自变量个数的增加总会增大,而修正的
随着自变量个数的增加总会增大,而修正的
![]() 则因为
则因为
![]() 对它有一个单调减的影响所以
对它有一个单调减的影响所以
![]() 增大时修正的
增大时修正的
![]() 不一定增大,便于不同自变量个数的模型的
比较。
不一定增大,便于不同自变量个数的模型的
比较。
方差分析表:
Analysis of Variance
Source DF Sum of Squares Mean Square F Stat Prob > F
Model 2 7215.6371 3607.8186 27.2275 0.0001
Error 16 2120.0997 132.5062 . .
C Total 18 9335.7368 . . .
这是关于模型是否成立的最重要的检验。它检验的是
![]() :模型中所有斜率项系数都等于零,这等价
于说自变量的线性组合对因变量没有解释作用。它依据的是一个标准的方差分解,把因变量
的总离差平方和(C Total)分解为能用模型解释的部分(Model)与不能被模型解释的部分
(随机误差,Error)之和,如果能解释的部分占的比例大就否定
:模型中所有斜率项系数都等于零,这等价
于说自变量的线性组合对因变量没有解释作用。它依据的是一个标准的方差分解,把因变量
的总离差平方和(C Total)分解为能用模型解释的部分(Model)与不能被模型解释的部分
(随机误差,Error)之和,如果能解释的部分占的比例大就否定
![]() 。F统计量(F Stat)就是这个比例(用自
由度修正过)。从上面结果看我们这个模型很显著(p值不超过万分之一),所以可以否定
。F统计量(F Stat)就是这个比例(用自
由度修正过)。从上面结果看我们这个模型很显著(p值不超过万分之一),所以可以否定
![]() 。
。
第三类检验:
Type III Tests
Source DF Sum of Squares Mean Square F Stat Prob > F
HEIGHT 1 2091.1460 2091.1460 15.7815 0.0011
AGE 1 22.3880 22.3880 0.1690 0.6865
这个表格给出了对各斜率项是否为零(
![]() )的检验结果。检验利用的是所谓第三类平
方和(Type III SS),又叫偏平方和,它代表在只缺少了本变量的模型中加入本变量导致的
模型平方和的增加量。比如,HEIGHT的第三类平方和即现在的模型平方和减去删除变量HEIGHT
的模型的模型平方和得到的差。第三类平方和与模型中自变量的次序无关,一般也不构成模
型平方和的平方和分解。表中用F统计量对假设进行了检验,分子是第三类平方和的均方,分
母为误差的均方。实际上,当分子自由度为1时,F统计量即通常的t检验统计量的平方。从表
中可见,身高的作用是显著的,而年龄的作用则不显著,有可能去掉年龄后的模型更好一些
。
)的检验结果。检验利用的是所谓第三类平
方和(Type III SS),又叫偏平方和,它代表在只缺少了本变量的模型中加入本变量导致的
模型平方和的增加量。比如,HEIGHT的第三类平方和即现在的模型平方和减去删除变量HEIGHT
的模型的模型平方和得到的差。第三类平方和与模型中自变量的次序无关,一般也不构成模
型平方和的平方和分解。表中用F统计量对假设进行了检验,分子是第三类平方和的均方,分
母为误差的均方。实际上,当分子自由度为1时,F统计量即通常的t检验统计量的平方。从表
中可见,身高的作用是显著的,而年龄的作用则不显著,有可能去掉年龄后的模型更好一些
。
参数估计及相关统计量:
Parameter Estimates
Variable DF Estimate Std Error T Stat Prob >|T|
INTERCEPT 1 -141.2238 33.3831 -4.2304 0.0006
HEIGHT 1 3.5970 0.9055 3.9726 0.0011
AGE 1 1.2784 3.1101 0.4110 0.6865
Parameter Estimates
Tolerance Var Inflation
. 0.0000
0.3416 2.9276
0.3416 2.9276
对截距项系数和各斜率项系数,给出了自由度(DF),估计值(Estimate),估计的标准
误差(Std Error),检验系数为零的t统计量,t统计量的p值,检验共线性的容许度(Tolerance
)和方差膨胀因子(Var Inflation)。其中自变量
![]() 的容许度定义为1减去
的容许度定义为1减去
![]() 对其它自变量的复相关系数平方,因此容许
度越小(接近0),说明
对其它自变量的复相关系数平方,因此容许
度越小(接近0),说明
![]() 对其它自变量的复相关系数平方大,即
对其它自变量的复相关系数平方大,即
![]() 可以很好地被其它自变量的线性组合近似,
这样
可以很好地被其它自变量的线性组合近似,
这样
![]() 在模型中的作用不大。记
在模型中的作用不大。记
![]() ,则
,则
![]() ,
,
![]() 叫做方差膨胀因子,它代表
叫做方差膨胀因子,它代表
![]() 的系数估计的方差的比例系数,显然其值越
大说明估计越不准确,也说明
的系数估计的方差的比例系数,显然其值越
大说明估计越不准确,也说明
![]() 在模型中的作用不大。方差膨胀因子与容许
度互为倒数。
在模型中的作用不大。方差膨胀因子与容许
度互为倒数。

下一个结果为残差对预测值的散点图,用它可以检验残差中有无异常情况,比如非线 性关系、异方差、模型辨识错误、异常值、序列相关等等。此例中各散点较随机地散布在0线 的上下,没有明显的模式,可认为结果是合适的(多余的不显著的变量AGE不反映在残差图中 )。
用Tables菜单可以加入一些其它的统计量。用Graphs菜单可以加入残差的正态概率图 (Residual Normal QQ)和偏杠杆图(Partial Leverage)。
在Vars菜单中可以指定一些变量,这些变量可以加入到数据窗口中。数据窗口的内容
保存在内存中,不自动改写磁盘中的数据集,所以要保存数据窗口的修改结果的话需要用“File
| Save | Data”命令指定一个用来保存的数据集名。为了了解加入的变量的具体意义,选
数据窗口菜单中的“Data Options”,选中“Show Variable Labels”选项。各变量中,Hat
Diag为帽子矩阵的对角线元素(帽子矩阵
![]() 恰好是
恰好是
![]() 的),即杠杆率,反映了每个观测的影响大
小。Predicted为拟合值(预报值),Linear Predictor为使用线性模型拟合的结果,在线性
回归时与Predicted相同。Residual为残差。Residual Normal Quantile是残差由小到大排序
后对应的标准正态的分位数,第
的),即杠杆率,反映了每个观测的影响大
小。Predicted为拟合值(预报值),Linear Predictor为使用线性模型拟合的结果,在线性
回归时与Predicted相同。Residual为残差。Residual Normal Quantile是残差由小到大排序
后对应的标准正态的分位数,第
![]() 个残差的正态分位数用
个残差的正态分位数用
 计算,其中
计算,其中
![]() 为标准正态分布函数。Standardized Residual
(标准化误差)为残差除以其标准误差。Studentized Residual(学生化残差)为与标准化
残差类似,但计算第
为标准正态分布函数。Standardized Residual
(标准化误差)为残差除以其标准误差。Studentized Residual(学生化残差)为与标准化
残差类似,但计算第
![]() 个学生化残差时预测值和方差估计都是在删
除第
个学生化残差时预测值和方差估计都是在删
除第
![]() 个观测后得到的。当学生化残差的值超过2时
这个观测有可能是强影响点或异常点。
个观测后得到的。当学生化残差的值超过2时
这个观测有可能是强影响点或异常点。
关于其它的一些诊断统计量请参考帮助菜单的“Extended Help | SAS System Help: Main menu | Help for SAS Products | SAS/INSIGHT | Techniques | Multiple Regression” ,或《SAS系统:SAS/STAT软件使用手册》第一章和第九章。
在SAS/INSIGHT中,为了保存结果表格,在进行分析之前选中菜单“File | Save | Initial Tables”,这是一个状态开关,选中时输出表格画在分析窗口内的同时显示在输出(Output )窗口。如果要保存某一个表格,也可以选定此表格(单击表格外框线),然后用菜单“File | Save | Tables”。为了保存分析窗口的图形,先选定此图形,然后选“File | Save | Graphics File”,输入一个文件名,选择一种文件类型如BMP即可。为了打印某一表格或图形,先选 定它,然后用菜单“File | Print”。选中“File | Save | Statments”可以开始保存SAS/INSIGHT 语句。
经典线性回归理论的估计与假设检验要求自变量
![]() 为常数(非随机),随机误差项满足
为常数(非随机),随机误差项满足
![]() 。广义线性模型放宽了这些假设,其模型
为
。广义线性模型放宽了这些假设,其模型
为
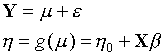
其中因变量
![]() (
(
![]() 向量)的元素为服从指数族分布(如正态、
逆高斯、伽马、泊松、二项分布)的随机变量,
向量)的元素为服从指数族分布(如正态、
逆高斯、伽马、泊松、二项分布)的随机变量,
![]() (
(
![]() 向量)的元素为与
向量)的元素为与
![]() 分布类型相同的随机误差项,元素之间相互
独立,单调函数
分布类型相同的随机误差项,元素之间相互
独立,单调函数
![]() 叫做联系函数,它把因变量的均值
叫做联系函数,它把因变量的均值
![]() 与自变量
与自变量
![]() (
(
![]() 阵)的线性组合联系起来。
阵)的线性组合联系起来。
![]() (
(
![]() 向量)为回归系数。模型中每个自变量对应
于设计阵
向量)为回归系数。模型中每个自变量对应
于设计阵
![]() 中的一列或几列,
中的一列或几列,
![]() 的第一列一般元素全为1,对应于截距项。
的第一列一般元素全为1,对应于截距项。
![]() (
(
![]() 向量)是表示偏移量的变量。
向量)是表示偏移量的变量。
注:随机变量Y称为服从指数族分布,如果其分布密度(概率函数)有如下形式:
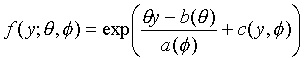
其中
![]() 为自然参数或称经典参数,
为自然参数或称经典参数,
![]() 为分散度参数(与尺度参数相关),
a,
b,
c为确定性函数。这样的自变量Y的均值和方差与参数的关系如下:
为分散度参数(与尺度参数相关),
a,
b,
c为确定性函数。这样的自变量Y的均值和方差与参数的关系如下:

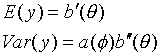
为了使用SAS/INSIGHT拟合广义线性模型,在选“Analyze | Fit (Y X)”之后,选定 因变量和自变量,然后按“Method”按钮,出现选择模型的对话框,在这里可以选因变量的 分布类型(Response Dist.),选联系函数,选估计尺度参数的方法。
各联系函数定义如下: Identity 恒等变换 Log 自然对数
Logit
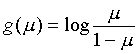
Probit
![]() ,其中
,其中
![]() 为标准正态分布函数
为标准正态分布函数
Comp. Log-Log
![]()
Power
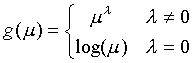 ,
,
![]() 在对话框的Power输入框指定。
在对话框的Power输入框指定。
对指数族中每一个因变量分布有一个特定的联系函数,使得
![]() ,即用分布的期望值表示经典参数,这样
的联系函数叫经典(canonical)联系函数。正态分布的经典联系函数为恒等变换,逆高斯分
布为-2次方变换,伽玛分布为-1次方变换,泊松分布为对数变换,二项分布为逻辑变换(Logit
)。注意Logit、probit、复合重对数变换都只适用于二项分布。
,即用分布的期望值表示经典参数,这样
的联系函数叫经典(canonical)联系函数。正态分布的经典联系函数为恒等变换,逆高斯分
布为-2次方变换,伽玛分布为-1次方变换,泊松分布为对数变换,二项分布为逻辑变换(Logit
)。注意Logit、probit、复合重对数变换都只适用于二项分布。
例如,SASUSER.INGOTS中存放了一个铸造厂的数据,它记录了各批铸件在一定的加热 、浸泡时间条件下出现的不能开始轧制的铸件数目。HEAT为加热时间,SOAK为浸泡时间,N为 每批铸件的件数,R为加热浸泡后N件铸件中还不能开始轧制的铸件数。R应该服从二项分布, 其分布参数(比例)可能受加热、浸泡时间的影响。因此,我们拟合以R为因变量,以HEAT和SOAK 为自变量的广义线性模型,因变量分布为二项分布,使用经典联系函数(Logit函数)。模型 为
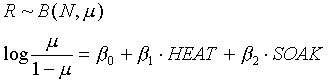
为了拟合这样的模型,选“Analyze | Fit(Y X)”,选R为Y变量,选HEAT和SOAK为自变量 ,按“Method”钮,选因变量分布为二项分布(Binomial),选变量N然后按“Binomial”钮 ,两次OK后即可以得到模型拟合窗口。可以看到,这个模型是显著的,但变量SOAK没有显著 影响。去掉变量SOAK重新拟合模型。可以看出,HEAT的系数为0.0807是正数,说明加热时间 越长不能轧制的件数越多。考察拟合结果窗口下方的残差对预报值图可以发现在右下方有三 个异常点,用刷亮方法选定它们,可以看到,这三个观测都是总共只有一个铸件的,所以对 一般结果意义不大。选“Edit | Observations | Exclude in Calculation”可以把这几个 点排除在外,发现结果基本不变。
SAS/STAT中提供了几个回归分析过程,包括REG(回归)、RSREG(二次响应面回归) 、ORTHOREG(病态数据回归)、NLIN(非线性回归)、TRANSREG(变换回归)、CALIS(线性 结构方程和路径分析)、GLM(一般线性模型)、GENMOD(广义线性模型),等等。我们这里 只介绍REG过程,其它过程的使用请参考《SAS系统――SAS/STAT软件使用手册》。
REG过程的基本用法为:
PROC REG DATA=输入数据集 选项; VAR 可参与建模的变量列表; MODEL 因变量=自变量表 / 选项; PRINT 输出结果; PLOT 诊断图形; RUN;
REG过程是交互式过程,在使用了RUN语句提交了若干个过程步语句后可以继续写其它的REG 过程步语句,提交运行,直到提交QUIT语句或开始其它过程步或数据步才终止。
例如,我们对SASUSER.CLASS中的WEIGHT用HEIGHT和AGE建模,可以用如下的简单REG 过程调用:
proc reg data=sasuser.class; var weight height age; model weight=height age; run;
就可以在输出窗口产生如下结果,注意程序窗口的标题行显示“PROC REG Running”表示REG 过程还在运行,并没有终止。
Model: MODEL1
Dependent Variable: WEIGHT Weight in pounds
Analysis of Variance
Sum of Mean
Source DF Squares Square F Value Prob>F
Model 2 7215.63710 3607.81855 27.228 0.0001
Error 16 2120.09974 132.50623
C Total 18 9335.73684
Root MSE 11.51114 R-square 0.7729
Dep Mean 100.02632 Adj R-sq 0.7445
C.V. 11.50811
Parameter Estimates
Parameter Standard T for H0:
Variable DF Estimate Error Parameter=0 Prob > |T|
INTERCEP 1 -141.223763 33.38309350 -4.230 0.0006
HEIGHT 1 3.597027 0.90546072 3.973 0.0011
AGE 1 1.278393 3.11010374 0.411 0.6865
Variable
Variable DF Label
INTERCEP 1 Intercept
HEIGHT 1 Height in inches
AGE 1 Age in years
这些结果与SAS/INSIGHT得到的结果是一致的。同样我们发现变量AGE的作用不显著,所以 我们只要再提交如下语句:
model weight=height; run; 就可以得到第二个模型结果: Model: MODEL2 Dependent Variable: WEIGHT Weight in pounds ……………
事实上,REG提供了自动选择最优自变量子集的选项。在MODEL语句中加上“SELECTION=
选择方法”的选项就可以自动挑选自变量,选择方法有NONE(全用,这是缺省)、FORWARD
(逐步引入法)、BACKWARD(逐步剔除法)、STEPWISE(逐步筛选法)、MAXR(最大
![]() 增量法)、MINR(最小
增量法)、MINR(最小
![]() 增量法)、RSQUARE(
增量法)、RSQUARE(
![]() 选择法)、ADJRSQ(修正
选择法)、ADJRSQ(修正
![]() 选择法)、CP(Mallows的
选择法)、CP(Mallows的
![]() 统计量法)。比如,我们用如下程序:
统计量法)。比如,我们用如下程序:
model weight=height age / selection=stepwise; run;可得到如下结果:
Stepwise Procedure for Dependent Variable WEIGHT
Step 1 Variable HEIGHT Entered R-square = 0.77050684 C(p) = 1.16895797
DF Sum of Squares Mean Square F Prob>F
Regression 1 7193.24911864 7193.24911864 57.08 0.0001
Error 17 2142.48772347 126.02868962
Total 18 9335.73684211
Parameter Standard Type II
Variable Estimate Error Sum of Squares F Prob>F
INTERCEP -143.02691844 32.27459130 2475.04717580 19.64 0.0004
HEIGHT 3.89903027 0.51609395 7193.24911864 57.08 0.0001
Bounds on condition number: 1, 1
------------------------------------------------------------------------------
All variables left in the model are significant at the 0.1500 level.
No other variable met the 0.1500 significance level for entry into the model.
Summary of Stepwise Procedure for Dependent Variable WEIGHT
Variable Number Partial Model
Step Entered Removed In R**2 R**2 C(p) F Prob>F
Label
1 HEIGHT 1 0.7705 0.7705 1.1690 57.0763 0.0001
Height in inches
可见只有变量HEIGHT进入了模型,而其它变量(AGE)则不能进入模型。
REG过程给出的缺省结果比较少。如果要输出高分辨率诊断图形的话需要在PROC REG 过程语句中加上GRAPHICS选项,用PRINT语句和PLOT语句显示额外的结果。为了显示模型的预 测值(拟合值)和95%预测界限,使用语句
print cli; run;得到如下的结果:
Dep Var Predict Std Err Lower95% Upper95%
Obs WEIGHT Value Predict Predict Predict Residual
1 84.0000 77.2683 3.963 52.1503 102.4 6.7317
2 98.0000 111.6 2.995 87.0659 136.1 -13.5798
3 90.0000 107.7 2.768 83.2863 132.1 -17.6807
4 77.0000 76.4885 4.042 51.3145 101.7 0.5115
5 84.5000 90.1351 2.889 65.6780 114.6 -5.6351
6 112.0 116.3 3.354 91.5388 141.0 -4.2586
7 50.5000 56.9933 6.251 29.8835 84.1032 -6.4933
8 112.5 100.7 2.577 76.3612 125.0 11.8375
9 102.5 101.8 2.587 77.5263 126.1 0.6678
10 112.5 126.0 4.296 100.6 151.4 -13.5062
11 102.5 104.6 2.645 80.2279 128.9 -2.0615
12 133.0 118.2 3.525 93.3827 143.0 14.7919
13 83.0000 80.3875 3.659 55.4757 105.3 2.6125
14 84.0000 100.7 2.577 76.3612 125.0 -16.6625
15 99.5000 87.0159 3.098 62.4451 111.6 12.4841
16 150.0 137.7 5.613 111.2 164.2 12.2967
17 128.0 109.6 2.872 85.1821 134.1 18.3698
18 85.0000 81.1673 3.587 56.3025 106.0 3.8327
19 112.0 116.3 3.354 91.5388 141.0 -4.2586
Sum of Residuals 0
Sum of Squared Residuals 2142.4877
Predicted Resid SS (Press) 2651.3521
各列分别为观测序号(Obs),因变量的值(Dep Var),预测值(Predict Value),预
测值的标准误差(Std Err Predict),95%预测区间下限(Lower 95% Predict),95%预
测区间上限(Upper 95% Predict),残差(Residual,为因变量值减预测值)。在表后又给
出了残差的总和(Sum of Residuals),残差平方和(Sum of Squared Residuals),预测
残差的平方和(Predicted Resid SS (Press))。所谓预测残差,是在计算第
i号观测的残差时从实际值中减去的预报值是用扣除第i号观测后的样本得到的模型产
生的预报值,而不是我们一般所用的预测值(实际是拟合值)。第i号样本的预测残差还可以
用公式
![]() 来计算,其中
来计算,其中
![]() 为帽子矩阵
为帽子矩阵
![]() 的第
i个主对角线元素。
的第
i个主对角线元素。
用print cli列出的是实际值的预测界限,还可以列出模型均值的预测界限,使用
print clm;
语句。在PRINT语句中可以指定的有ACOV, ALL, CLI, CLM, COLLIN, COLLINOINT, COOKD, CORRB, COVB, DW, I, INFLUENCE, P, PARTIAL, PCORR1, PCORR2, R, SCORR1, SCORR2, SEQB, SPEC, SS1, SS2, STB, TOL, VIF, XPX,等等。
对于自变量是一元的情况,可以在自变量和因变量的散点图上附加回归直线和均值置 信界限。比如,
plot weight * height / conf95;

可以产生图 4,在图的上方列出了模型方程,右方还给出了观测个数、
![]() 、修正
、修正
![]() 、均方误差开根。在PLOT语句中可以使用PREDICTED.
、RESIDUAL.等特殊名字表示预测值、残差等计算出的变量,比如,在自变量为多元时无法作
回归直线,常用的诊断图表为残差对预测值图,就可以用
、均方误差开根。在PLOT语句中可以使用PREDICTED.
、RESIDUAL.等特殊名字表示预测值、残差等计算出的变量,比如,在自变量为多元时无法作
回归直线,常用的诊断图表为残差对预测值图,就可以用
plot residual. * predicted.;绘制。为了绘制学生化残差的图形,可以用
plot rstudent. * obs.;回归分析的其它用法及进一步的诊断方法请参考有关统计书籍和SAS使用手册。
统计学中用方差分析来研究分类变量(所谓“因素”)对数值型变量(所谓“指标” )的影响。主要目的是研究某些因素对于指标有无显著的影响。对有显著影响的因素,一般 希望找出最好水平。
单因素方差分析是4.1.2问题的一个自然延续。在4.1.2中,我们有一个分类变量把观 测分为两组,我们要研究这两组的均值有没有显著差异。如果这个分类变量的取值不只两个 ,则这时4.1.2的检验方法不再适用,但我们同样要解决各组均值是否有显著差异的问题。如 果各组之间有显著差异,说明这个因素(分类变量)对指标是有显著影响的,因素的不同取 值(叫做水平)会影响到指标的取值。
例如,数据集SASUSER.VENEER中为比较若干种牌子的胶合板的耐磨情况得到的数据,变量BRAND 为试样的牌子,变量WEAR为试样的磨损量。共有五种牌子的胶合板,每种试验了4个试样。我 们希望知道这五种牌子胶合板的磨损量有无显著差别,如果无显著差别我们在选购时就不必 考虑哪一个更耐磨而只需考虑价格等因素,但如果结果有显著差异则应考虑使用耐磨性好的 牌子。这里,因素是胶合板的牌子,指标为磨损量,当各种牌子胶合板磨损量有显著差异时 ,说明因素的取值对指标有显著的影响。所以,方差分析的结论是因素对指标有无显著影响 。注意,经典的方差分析只判断因素的各水平有无显著差异,而不管两个因素之间是否有差 异,比如说我们的五个牌子即使有四个牌子没有显著差异,只有一个牌子的胶合板比这四个 牌子的都好,结论也是说因素是显著的,或因素的各水平间有显著差异。
方差分析把指标的方差分解为由因素的不同取值能够解释的部分,和剩余的不能解释的部 分,然后比较两部分,当能用因素解释的部分明显大于剩余的部分时认为因素是显著的。方 差分析假定观测是彼此独立的,观测为正态分布的样本,由因素各水平分成的各组的方差相 等。在这些假定满足时,就可以用ANOVA过程来进行方差分析。其一般写法为
PROC ANOVA DATA=数据集; CLASS 因素; MODEL 指标=因素; RUN;
比如,为了分析SASUSER.VENEER中各种牌子的胶合板的耐磨性有无显著差别,首先我们假 定假设检验使用的检验水平为0.05,可以使用如下程序进行方差分析:
proc anova data=sasuser.veneer; class brand; model wear=brand; run;结果如下:
Analysis of Variance Procedure
Class Level Information
Class Levels Values
BRAND 5 ACME AJAX CHAMP TUFFY XTRA
Number of observations in data set = 20
Dependent Variable: WEAR Amount of material worn away
Source DF Sum of Squares Mean Square F Value Pr > F
Model 4 0.61700000 0.15425000 7.40 0.0017
Error 15 0.31250000 0.02083333
Corrected Total 19 0.92950000
R-Square C.V. Root MSE WEAR Mean
0.663798 6.155120 0.14433757 2.34500000
Source DF Anova SS Mean Square F Value Pr > F
BRAND 4 0.61700000 0.15425000 7.40 0.0017
结果可以分为四个部分,第一部分是因素水平的信息,我们看到因素只有一个BRAND,它 有5个水平,分别是ACME、AJAX、CHAMP、TUFFY、XTRA。共有20个观测。第二部分就是经典的 方差分析表,表前面指明了因变量(指标)为WEAR,第一列“来源”说明方差的来源,是模 型的(可以用方差分析模型解释的),误差的(不能用模型解释的),还是总和。第三列为 平方和,其大小代表了各方差来源作用的大小。第二列为自由度。第四列为均方,即平方和 除以自由度。第五列F值是F统计量的值,其计算公式为模型均方除以误差均方,用来检验模 型的显著性,如果不显著说明模型对指标的变化没有解释能力。第六列是F统计量的p值。由 于这里p值小于0.05(我们的检验水平),所以模型是显著的,因素对指标有显著影响。结果 的第三部分是一些与模型有关的简单统计量,第一个是复相关系数平方,与回归模型一样仍 代表总变差中能被模型解释的比例,第二个是变异系数,第三个是根均方误差,第四个是指 标的均值。结果的第四部分是方差分析表的细化,给出了各因素的平方和和F统计量,因为是 单因素所以这一行与上面的“模型”一行相同。
当方差分析的正态分布假定或方差相等假定不能满足时,对单因素问题,可以使 用非参数方差分析的Kruskal-Wallis检验方法。这种检验不要求观测来自正态分布总体,不 要求各组的方差相等,甚至指标可以是有序变量(变量取值只有大小之分而没有差距的概念 ,比如磨损量可以分为大、中、小三档,得病的程度可以分为重、轻、无,等等)。
NPAR1WAY过程的调用与ANOVA过程不同,因为它是单因素方差分析过程,所以只要用CLASS 语句给出分类变量(因素),用VAR语句给出指标就可以了,一般格式为:
PROC NPAR1WAY DATA=数据集 WILCOXON; CLASS 因素; VAR 指标; RUN;
注意这样的语句格式与1.4.2中两独立样本比较的做法完全相同。当“因素”有两个水平 时,执行Wilcoxon秩和检验,多个水平时执行Kruskal-Wallis检验。
比如,为了分析上面的胶合板例子中各牌子的耐磨性有无显著差异,取定0.10的检验 水平,可以用如下的NPAR1WAY过程:
proc npar1way data=sasuser.veneer wilcoxon; class brand; var wear; run;得到如下结果:
N P A R 1 W A Y P R O C E D U R E
Wilcoxon Scores (Rank Sums) for Variable WEAR
Classified by Variable BRAND
Sum of Expected Std Dev Mean
BRAND N Scores Under H0 Under H0 Score
ACME 4 40.0 42.0 10.4830691 10.0000000
CHAMP 4 44.0 42.0 10.4830691 11.0000000
AJAX 4 12.0 42.0 10.4830691 3.0000000
TUFFY 4 69.0 42.0 10.4830691 17.2500000
XTRA 4 45.0 42.0 10.4830691 11.2500000
Average Scores Were Used for Ties
Kruskal-Wallis Test (Chi-Square Approximation)
CHISQ = 11.982 DF = 4 Prob > CHISQ = 0.0175
结果分为两个部分,第一部分是各组的秩和的情况,包括观测个数(N)、秩和(Sum of
Scores)、在各组无显著差异的零假设下的期望秩和(Expected Under H0)、在零假设下
的标准差(Std Dev Under H0)、平均秩和(Mean Score,为秩和除以组内观测数)。下面
的“Average Scores Were Used for Ties”是说当名次相同时(如两个第2)用名次的平均
值((2+3)/2=2.5)。第二部分为Kruskal-Wallis检验的结果,包括近似的
![]() 统计量,自由度,检验的p值(Prob > CHISQ
)。现在p值0.0175小于预定的水平0.10所以结论是各种牌子的胶合板的耐磨性能有显著差异
。注意,Kruskal-Wallis检验是非参数检验,在同等条件下非参数检验一般比参数检验的功
效低,所以这里的p值0.0175比用ANOVA过程得到的p值0.0017要大。
统计量,自由度,检验的p值(Prob > CHISQ
)。现在p值0.0175小于预定的水平0.10所以结论是各种牌子的胶合板的耐磨性能有显著差异
。注意,Kruskal-Wallis检验是非参数检验,在同等条件下非参数检验一般比参数检验的功
效低,所以这里的p值0.0175比用ANOVA过程得到的p值0.0017要大。
方差分析只检验各组是否没有任何两两之间的差异,但不检验到底是哪两组之间有显 著差异。在三个或多个组之间进行两个或多个比较的检验叫做多重比较。多重比较在统计学 中没有一个公认的解决方法,而是提供了若干种检验方法。因为多重比较要进行不只一次的 比较,所以在多重比较的检验水平有两种:总错误率(experimentwise error rate)和单次 比较错误率。总错误率是指所有比较(比如,五个组两两之间比较有10次)的总第一类错误 概率,单次比较错误率是指每一次比较的第一类错误概率。显然,总错误率要比单次比较错 误率高。
在ANOVA过程中使用MEANS语句可以进行多重比较。格式如下:
MEANS 因素 / 选项;
如果不使用选项,则只对因素的各水平计算指标的平均值和标准差,比如:
proc anova data=sasuser.veneer; class brand; model wear=brand; means brand; run;则在通常的方差分析结果基础上增加如下结果:
Level of -------------WEAR------------
BRAND N Mean SD
ACME 4 2.32500000 0.17078251
AJAX 4 2.05000000 0.12909944
CHAMP 4 2.37500000 0.17078251
TUFFY 4 2.60000000 0.14142136
XTRA 4 2.37500000 0.09574271
要进行两两比较,有多种方法,可以在MEANS语句的选项中指定检验方法。
一、用重复t检验控制单次比较错误率
重复t检验的想法很简单:在适当的检验水平下对两组之间进行两样本t检验并对 所有组两两之间检验。控制的是每次比较的第一类错误概率。缺省使用0.05水平。注意这样 检验的总错误率将大大高于每次比较的错误率。比如,在上面程序后加入(ANOVA是交互式过 程)
means brand / t; run;可得如下结果:
T tests (LSD) for variable: WEAR
NOTE: This test controls the type I comparisonwise error rate not the
experimentwise error rate.
Alpha= 0.05 df= 15 MSE= 0.020833
Critical Value of T= 2.13
Least Significant Difference= 0.2175
Means with the same letter are not significantly different.
T Grouping Mean N BRAND
A 2.6000 4 TUFFY
B 2.3750 4 XTRA
B
B 2.3750 4 CHAMP
B
B 2.3250 4 ACME
C 2.0500 4 AJAX
结果先说明了检验的指标是变量WEAR,然后说明了这种检验控制单次比较的第一类错误概 率而不是总的第一类错误概率。下面给出了检验的一些指标,比如水平(Alpha)为0.05(控 制单次比较的第一类错误概率),自由度(df)为15,误差的均方(MSE,是方差分析表中误 差的均方)为0.020833,两样本t检验的t统计量的临界值(Critical Value of T)为2.13, 如果两样本t检验的t统计量值绝对值超过临界值则认为两组有显著差异,或者等价地,如果 两组的均值之差绝对值大于最小显著差别(Least Significant Difference)0.2175也是有 显著差异。下面列出了检验的结果,把因素各水平的指标平均值由大到小排列,然后把两两 比较的结果用第一列的字母来表示,字母相同的水平没有显著差异,字母不同的水平有显著 差异。所以我们看到,重复t检验的结果把五种牌子分成了A、B、C三个组,TUFFY单独是一组 ,它的磨损量最大;XTRA、CHAMP、ACME是一组,这三种两两之间没有显著差异;AJAX单独是 一组,其磨损量最小。
二、用Bonferroni t检验控制总错误率
Bonferroni t检验通过把每次比较的错误率取得很小来控制总误差率。比如,共 有10次比较时,把每次比较的错误率控制在0.005就可以保证总错误率不超过0.05,但是,这 样得到的实际总第一类错误率可能要比预定的水平小得多。在MEANS语句中使用BON语句可以 执行Bonferroni t检验,缺省总错误率控制水平为0.05。对上面的胶合板数据增加如下语句 :
means brand / bon; run;结果如下:
Bonferroni (Dunn) T tests for variable: WEAR
NOTE: This test controls the type I experimentwise error rate, but
generally has a higher type II error rate than REGWQ.
Alpha= 0.05 df= 15 MSE= 0.020833
Critical Value of T= 3.29
Minimum Significant Difference= 0.3354
Means with the same letter are not significantly different.
Bon Grouping Mean N BRAND
A 2.6000 4 TUFFY
A
B A 2.3750 4 XTRA
B A
B A 2.3750 4 CHAMP
B A
B A 2.3250 4 ACME
B
B 2.0500 4 AJAX
结果先说明了检验类型和指标(变量WEAR),然后说明了检验控制总第一类错误率,但一 般比REGWQ方法的第二类错误概率高(检验功效较低)。下面给出了几个检验用的值。最后给 出了Bonferroni t检验的结果,有相同分组字母的因素水平间无显著差异,否则有显著差异 。我们看到,TUFFY与XTRA、CHAMP、ACME没有显著差异,与AJAX有显著差异;XTRA、CHAMP、ACME 两两之间没有显著差异,而且与其它两个也都没有显著差异;AJAX与TUFFY有显著差异,与其 它三个没有显著差异。其分组是有交叉的。
三、用REGWQ检验控制总错误率
用Bonferroni t检验控制总错误率过于保守,功效较低,不易发现实际存在的显 著差异。REGWQ方法可以控制总错误率并且一般比Bonferroni t检验要好。这种方法执行多阶 段的检验,它对因素水平的各种子集进行检验。在MEANS语句中用REGWQ选项可以进行REGWQ检 验。例如,在前面的例子后再运行
means brand/ regwq; run;结果如下
Ryan-Einot-Gabriel-Welsch Multiple Range Test for variable: WEAR
NOTE: This test controls the type I experimentwise error rate.
Alpha= 0.05 df= 15 MSE= 0.020833
Number of Means 2 3 4 5
Critical Range 0.264828 0.2917322 0.2941581 0.31516
Means with the same letter are not significantly different.
REGWQ Grouping Mean N BRAND
A 2.6000 4 TUFFY
A
A 2.3750 4 XTRA
A
A 2.3750 4 CHAMP
A
A 2.3250 4 ACME
B 2.0500 4 AJAX
可见它比Bonferroni方法发现了较多的显著差异,除了TUFFY和AJAX仍有显著差异以外, 还发现XTRA、CHAMP、ACME也都与AJAX有显著差异。
MEANS语句的选项可以同时使用。在MEANS语句中可以用ALPHA=水平值来指定检验的水 平。ANOVA过程中还提供了其它的多重比较方法,请自己参考有关资料。
SAS提供了若干个方差分析过程,可以考虑多个因素、有交互作用、有嵌套等情况的 方差分析。用GLM过程还可以用一般线性模型来处理方差分析问题。在这里我们只介绍如何用ANOVA 过程进行均衡设计的多因素方差分析。
例如,为了提高一种橡胶的定强,考虑三种不同的促进剂(因素A)、四种不同分量的氧 化锌(因素B)对定强的影响,对配方的每种组合重复试验两次,总共试验了24次,得到如下 的结果:
表格 1 橡胶配方试验数据
|
B:氧化锌 A:促进剂 |
1 |
2 |
3 |
4 |
|
1 |
31, 33 |
34, 36 |
35, 36 |
39, 38 |
|
2 |
33, 34 |
36, 37 |
37, 39 |
38, 41 |
|
3 |
35, 37 |
37, 38 |
39, 40 |
42, 44 |
我们首先把数据输入为SAS数据集。输入的办法可以是直接输入各个观测,例如:
data rubber; input A B STREN; cards; 1 1 31 1 1 33 1 2 34 1 2 36 1 3 35 1 3 36 1 4 39 1 4 38 2 1 33 …………… ; run;也可以使用如下的直接循环控制的INPUT读取:
data rubber;
do a=1 to 3;
do b=1 to 4;
do r=1 to 2;
input stren @@;
output;
end;
end;
end;
cards;
31 33 34 36 35 36 39 38
33 34 36 37 37 39 38 41
35 37 37 38 39 40 42 44
;
run;
其中INPUT语句尾部的两个@符号表示多次INPUT语句可以从同一行去读取(否则每次INPUT 语句运行时自动从下一行开始读)。
为了研究两个因素的主效应和交互作用,使用如下ANOVA过程:
proc anova data=rubber; class a b; model stren = a b a*b; run;
MODEL语句中中A表示因素A的主效应,B表示因素B的主效应,A*B表示A和B的交互作用。结 果如下:
Analysis of Variance Procedure
Class Level Information
Class Levels Values
A 3 1 2 3
B 4 1 2 3 4
Number of observations in data set = 24
Dependent Variable: STREN
Sum of Mean
Source DF Squares Square F Value Pr > F
Model 11 193.45833333 17.58712121 12.06 0.0001
Error 12 17.50000000 1.45833333
Corrected Total 23 210.95833333
R-Square C.V. Root MSE STREN Mean
0.917045 3.260152 1.2076147 37.041667
Source DF Anova SS Mean Square F Value Pr > F
A 2 56.58333333 28.29166667 19.40 0.0002
B 3 132.12500000 44.04166667 30.20 0.0001
A*B 6 4.75000000 0.79166667 0.54 0.7665
结果首先给出了因素(Class)的变量名和各水平值,观测数。然后是总的方差分析表, 指明指标为变量STREN,给出了模型、误差、总平方和,F统计量值和p值。可见模型是显著的 。为了分析各作用的显著性,看后面的详细的方差分析表,它给出了模型中各作用(A、B、A*B )的平方和和检验的F统计量值及p值。可以看出,两个因素的主效应都是显著的,交互作用 效应不显著。所以,我们可以重新运行ANOVA过程,不指定交互作用效应:
proc anova data=rubber; class a b; model stren = a b / t; run;
这时模型的F统计量变为30.53,因素A主效应的F统计量变为22.89,因素B主效应的F统计 量变为35.63,都增大了。两个因素的主效应仍是高度显著的,说明它们对定强都有显著影响 。为了找到最好的配方,在前面的ANOVA过程后使用
means a b; run;
可以计算出每种水平下的指标平均值,因素A(促进剂)在第三水平使指标(定强)最大 ,因素B(氧化锌)在第四水平使指标最大,所以最好的配方是:第三种促进剂,第四种氧化 锌分量。
ANOVA也可以用来分析正交设计的结果。例如,为了提高某种试剂产品的收率(指标 ),考虑如下几个因素对其影响:
表格 2 试剂产品影响因素
|
A:反应温度 |
1 (50℃) |
2 (70℃) |
|
B:反应时间 |
1 (1小时) |
2 (2小时) |
|
C:硫酸浓度 |
1 (17%) |
2 (27%) |
|
D:硫酸产地 |
1 (天津) |
2 (上海) |
|
E:操作方式 |
1 (搅拌) |
2 (不搅拌) |
把这五个因素放在
![]() 表的五列上,得到如下的试验方案及结果(
见下面的数据步)。用ANOVA过程可以分析:
表的五列上,得到如下的试验方案及结果(
见下面的数据步)。用ANOVA过程可以分析:
data exp; input temp time conc manu mix prod; cards; 1 1 1 1 1 65 1 1 1 2 2 74 1 2 2 1 2 71 1 2 2 2 1 73 2 1 2 1 2 70 2 1 2 2 1 73 2 2 1 1 1 62 2 2 1 2 2 69 ; run; proc anova data=exp; class temp time conc manu mix; model prod = temp--mix; means temp--mix / t; run;
用0.05水平,得到的模型是显著的(模型p值为0.0250),各因素的检验结果如下:
Source DF Anova SS Mean Square F Value Pr > F TEMP 1 10.12500000 10.12500000 16.20 0.0565 TIME 1 6.12500000 6.12500000 9.80 0.0887 CONC 1 36.12500000 36.12500000 57.80 0.0169 MANU 1 55.12500000 55.12500000 88.20 0.0111 MIX 1 15.12500000 15.12500000 24.20 0.0389
可见硫酸浓度、产地、操作方式是显著的,必须采用它们的最好水平,温度、时间不显著 ,在同等条件下可以优先采用它们的最好水平。从MEANS语句的结果可以知道,硫酸浓度的最 好水平是水平2(27%),硫酸产地的最好水平是水平2(上海),操作方式的最好水平是水平2 (不搅拌),反应温度的最好水平是水平1(50℃),反应时间的最好水平是水平1(1小时) 。从以上分析可以得到好的生产方案。
上面所讲到的统计分析主要针对数值型(区间)变量进行。在实际工作中,离散取值 的名义变量(如性别、职业、民族)和有序变量(如调查意见的完全同意、同意、中立、反 对、强烈反对)也是十分常见的,对这类离散变量(又称属性变量)的分析也是统计学的重 要的研究内容。这一节我们讲述检验两个离散取值的变量的独立性的列联表检验方法,并介 绍有序变量的关联性量度的算法。
离散变量的取值可以把样本进行分类。比如,我们的样本是一个班的学生情况,可以 根据学生的性别把观测分为男生和女生两个组。我们也可以根据学生的来源把观测分为本地 学生和外地学生两个组。如果联合使用这两个变量对观测分类,就可以把观测分为四个组, 我们可以统计每个组学生的人数,并把结果画成一个表格:
表格 3 学生性别、来源分布表
|
男生 |
女生 |
|
|
本地 |
4 |
6 |
|
外地 |
14 |
7 |
这样的表格就叫做列联表。它给出了按照两个变量总和分类得到的每一个小类的观测个数 。
为了得到这样的表格,需要把数据输入为数据集。有时我们得到的数据是每一个观测 的变量取值,比如,我们有每一个学生的性别(SEX)情况和来源(FROM)情况,可以输入这 些原始数据,如:
data class; input sno sex $ from $; label sex='性别' from='来源'; cards; 1 男 本地 2 女 外地 3 男 外地 …………/* 所有学生的记录 */ ; run;
然后用如下的FREQ过程可以画出列联表:
proc freq data=class; tables from * sex; run;结果见表格4。
表格数据输入的另一种情况是,我们得到的数据就已经是上面表格 3那样的调查结果而不 是具体的样本情况,可以直接把表格输入一个数据集,但数据集中要有一个代表观测数的变 量,例如:
data classt; input from $ sex $ numcell; label sex='性别' from='来源'; cards; 本地 男 4 本地 女 6 外地 男 14 外地 女 7 ; run;
这样的数据要画列联表,需要在FREQ过程中使用WEIGHT语句指定表示重复数的变量(NUMCELL ):
proc freq data=classt; tables from * sex; weight numcell; run;
结果和上面得到的结果相同。
在输出结果中,我们看到TABLES语句中的前一个变量被用来区分行,后一个变量被用 来区分列。每个格子中有四个数:Frequency(频数,本格子的观测数),Percent(百分比 ),Row Pct(行百分比,表示本类在本行中占的百分比,比如本地男生有4个人,本行有10 个人,占本行的40.00%),Col Pct(列百分比)。在表的右侧有行总计,比如本地学生有10 个人,占总学生数(31人)的32.26%。在表的下侧有列总计,比如男生有18个人,占学生总 数的58.06%。表格右下方是总数(31)和总百分比(100)。
为了作列联表,调用FREQ过程,使用TABLES语句指定行变量和列变量,两者用星号分 开,如果数据本身是表格数据还需要用WEIGHT语句指定存放表格单元观测数的变量。
可以作出简化的表格,在TABLES语句中加上NOFREQ、NOPCT、NOROW、NOCOL等选项就 可以抑制相应的统计量的输出。例如,用如下程序:
proc freq data=classt; tables from * sex / nopct norow nocol; weight numcell; run;就可以产生只有单元数的表格。
对于数值型变量,我们考虑其相关关系的通常的办法是计算相关系数和进行回归分析
。如果我们要研究离散取值的名义变量和有序变量有无相关,最常用的检验办法是列联表独
立性检验。列联表检验的零假设是两变量
![]() 和
和
![]() 相互独立,计算一个
相互独立,计算一个
![]() 统计量,与列联表中频数取值和零假设下期
望取值之差有关,当
统计量,与列联表中频数取值和零假设下期
望取值之差有关,当
![]() 很大时否定零假设。
很大时否定零假设。
例如,为了探讨吸烟与慢性支气管炎有无关系,调查了339人,情况如下: 表格 5 吸烟与慢性支气管炎调查表
|
患慢性支气管炎 |
未患慢性支气管炎 |
|
|
吸烟 |
43 |
162 |
|
不吸烟 |
13 |
121 |
设想有两个随机变量X,Y:X取1表示吸烟,取2表示不吸烟,Y取1表示患慢性支气管炎, 取2表示未患。零假设为:
![]() : X与Y相互独立
: X与Y相互独立
要检验此零假设,先取定检验水平0.05,用PROC FREQ过程,在TABLES语句中加上CHISQ选 项即可。下面的例子中还加入了EXPECTED选项以显示零假设下的期望频数值:
data bron; input smoke $ bron $ numcell; label smoke='吸烟' bron='慢性支气管炎'; cards; 吸烟 患病 43 吸烟 未患 162 不吸烟 患病 13 不吸烟 未患 121 ; proc freq data=bron; tables smoke*bron / nopct norow nocol chisq expected; weight numcell; run;
结果如下:
TABLE OF SMOKE BY BRON
SMOKE(吸烟) BRON(慢性支气管炎)
Frequency|
Expected |患病 |未患 | Total
---------+--------+--------+
不吸烟 | 13 | 121 | 134
| 22.136 | 111.86 |
---------+--------+--------+
吸烟 | 43 | 162 | 205
| 33.864 | 171.14 |
---------+--------+--------+
Total 56 283 339
STATISTICS FOR TABLE OF SMOKE BY BRON
Statistic DF Value Prob
------------------------------------------------------
Chi-Square 1 7.469 0.006
Likelihood Ratio Chi-Square 1 7.925 0.005
Continuity Adj. Chi-Square 1 6.674 0.010
Mantel-Haenszel Chi-Square 1 7.447 0.006
Fisher's Exact Test (Left) 4.09E-03
(Right) 0.998
(2-Tail) 6.86E-03
Phi Coefficient -0.148
Contingency Coefficient 0.147
Cramer's V -0.148
Sample Size = 339
列联表中列出了表格单元频数和在零假设下的期望频数,可以看出,吸烟人中患病的数目 比期望数目大。检验的结果只要看后面的统计量部分的Chi-Square一行,其值为7.469,p值 为0.006,所以应否定零假设,吸烟与患慢性支气管炎是不独立的。
使用
![]() 检验要求每个单元格至少频数不少于5。在
条件不满足的时候还可以使用Fisher精确检验。对于两行两列的表格FREQ过程自动给出Fisher
精确检验的结果,其双侧检验p值为0.00686,应拒绝零假设。
检验要求每个单元格至少频数不少于5。在
条件不满足的时候还可以使用Fisher精确检验。对于两行两列的表格FREQ过程自动给出Fisher
精确检验的结果,其双侧检验p值为0.00686,应拒绝零假设。
对于区间变量,我们可以计算两两的相关系数。属性变量因为没有数值概念所以不能 计算相关系数,但对于两个有序变量我们可以计算类似于相关系数的关联性量度。其中一种 关联性量度叫做Kendal Tau-b统计量,取值在-1到1之间,值接近于1表示正关联,接近于-1 表示负关联,接近于0表示没有相关关系。
下面用例子说明如何在FREQ过程中计算Kendal Tau-b统计量。本例取自《SAS系统与基础 统计分析》一书。假设我们要研究奶牛种群大小与其患某种细菌性疾病的关系。牛的患病程 度(DISEASE)分为没有(0)、低(1)、高(2),牛群大小(HERDSIZE)分为小(1)、中 (2)、大(3)。数据如下数据步所示:
data cows; input herdsize disease numcell; label herdsize='牛群大小' disease='患病程度'; cards; 1 0 9 1 1 5 1 2 9 2 0 18 2 1 4 2 2 19 3 0 11 3 1 88 3 2 136
;
用FREQ过程在TABLES语句中加上MEASURES选项就可以计算Kendall Tau-b统计量:
proc freq data=cows; tables herdsize*disease / measures expected nopercent norow nocol; weight numcell; title '奶牛疾病数据分析'; run;
结果如下:
HERDSIZE(牛群大小) DISEASE(患病程度)
Frequency|
Expected | 0| 1| 2| Total
---------+--------+--------+--------+
1 | 9 | 5 | 9 | 23
| 2.9231 | 7.4615 | 12.615 |
---------+--------+--------+--------+
2 | 18 | 4 | 19 | 41
| 5.2107 | 13.301 | 22.488 |
---------+--------+--------+--------+
3 | 11 | 88 | 136 | 235
| 29.866 | 76.237 | 128.9 |
---------+--------+--------+--------+
Total 38 97 164 299
STATISTICS FOR TABLE OF HERDSIZE BY DISEASE
Statistic Value ASE
------------------------------------------------------
Gamma 0.411 0.101
Kendall's Tau-b 0.217 0.061
Stuart's Tau-c 0.148 0.044
Somers' D C|R 0.276 0.078
Somers' D R|C 0.171 0.048
Pearson Correlation 0.282 0.066
Spearman Correlation 0.233 0.066
Lambda Asymmetric C|R 0.000 0.000
Lambda Asymmetric R|C 0.109 0.079
Lambda Symmetric 0.035 0.026
Uncertainty Coefficient C|R 0.099 0.026
Uncertainty Coefficient R|C 0.144 0.037
Uncertainty Coefficient Symmetric 0.117 0.030
Sample Size = 299
算出的Kendall Tau-b统计量值为0.217,渐近标准误差(ASE)为0.061,用统计量值加减 两倍标准误差作为Kendall Tau-b的95%置信区间,可算得(0.095,0.339)在零点左边,所以 可认为奶牛患病程度与种群大小有正的关联。事实上,我们从列联表中实际频数与期望频数 的对比也可以看出,小的种群患病比期望值轻,大的种群患病比期望值重,即患病程度与种 群大小有正的关联。
15 3.5 3.5 7 1 7 5.75 27 15 8 4.75 7.5 4.25 6.25 5.75 5 8.5 9 6.25 5.5 4 7.5 8.75 6.5 4 5.25 3 12 3.75 4.75 6.25 3.25 2.5
男性组:13.3 19 20 8 18 22 20 31 21 12 16 12 24 女性组:22 26 16 12 21.7 23.2 21 28 30 23比较这些人中男性和女性的身体脂肪含量有无显著差异。
|
学号 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
第一次 |
93 |
88 |
89 |
88 |
67 |
89 |
83 |
94 |
89 |
55 |
|
第二次 |
98 |
74 |
67 |
92 |
83 |
90 |
74 |
97 |
96 |
81 |
|
学号 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
|
第一次 |
88 |
91 |
85 |
70 |
90 |
90 |
94 |
67 |
87 |
83 |
|
第二次 |
83 |
94 |
89 |
78 |
96 |
93 |
81 |
81 |
93 |
91 |
胃溃疡病人组:0.2 10.4 0.3 10.9 0.4 11.3 1.1 12.4 2.0 16.2 2.1 17.6 3.3 18.9 3.8 20.7 4.5 24.0 4.8 25.4 4.9 40.0 5.0 42.2 5.3 50.0 7.5 60.0 9.8
对照组:0.2 5.4 0.3 5.7 0.4 5.8 0.7 7.5 1.2 8.7 1.5 8.8 1.5 9.1 1.9 10.3 2.0 15.6 2.4 16.1 2.5 16.5 2.8 16.7 3.6 20.0 4.8 20.7 4.8 33.0
提示:要考虑分布是否正态。
|
标准 |
14.7 |
14.0 |
12.9 |
16.2 |
10.2 |
12.4 |
12.0 |
14.8 |
11.8 |
9.7 |
|
高压 |
12.1 |
10.9 |
13.1 |
14.5 |
9.6 |
11.2 |
9.8 |
13.7 |
12.0 |
9.1 |
|
x |
1 |
1 |
2 |
2 |
2 |
3 |
5 |
6 |
6 |
7 |
|
y |
94.5 |
86.4 |
71 |
80.5 |
81.4 |
67.4 |
49.3 |
46.8 |
42.3 |
36.6 |
8.为试制某种化工产品,在三种不同温度、四种不同压力下试验,每一水平组合重复两 次,得到产品的收率数据如下(%):
|
压力 温度 |
1 |
2 |
3 |
4 |
|
1 |
52, 57 |
42, 45 |
41, 45 |
48, 45 |
|
2 |
50, 52 |
47, 45 |
47, 48 |
53, 30 |
|
3 |
63, 58 |
54, 59 |
57, 60 |
58, 59 |
试在0.05水平下进行方差分析并简述结果。
|
黑人 |
白人 |
|
|
有罪 |
17 |
19 |
|
无罪 |
149 |
141 |
试在0.05水平下检验判决结果与被告种族是否独立。