用如下方法可以进入SAS系统的窗口运行环境:
在Win95或NT环境中,从开始菜单的程序文件夹中找到SAS系统文件夹,从中启动SAS 系统。或者生成SAS.EXE的快捷方式(把SAS.EXE用鼠标右键拖到桌面),双击SAS.EXE启动。
在Windows 3.xx环境中找到SAS系统程序组中的SAS图标双击启动。
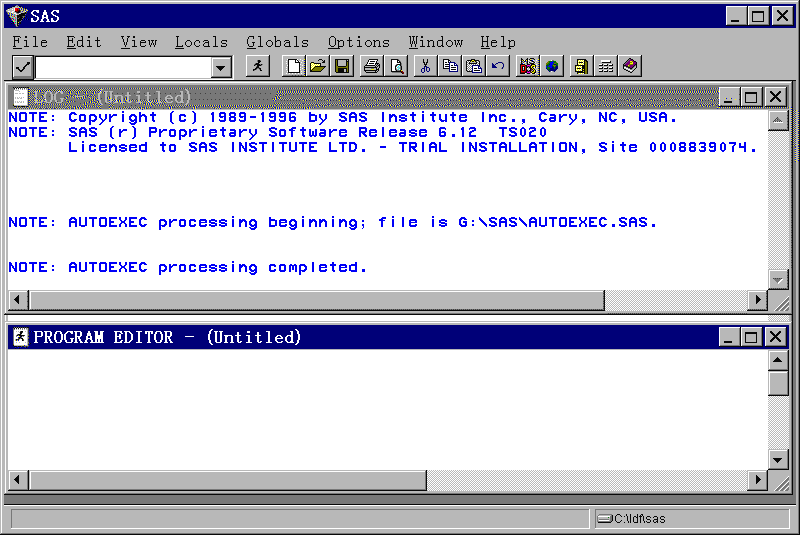
启动后,出现如图 1的SAS运行界面,术语称为“SAS工作空间(SAS Application WorkSpace )”。它象其它Windows应用程序一样,在一个主窗口内,包含若干个子窗口,并有菜单条、 工具栏、状态栏等。
SAS有三个最重要的子窗口:程序窗口(PROGRAM EDITOR)、运行记录窗口(LOG)、输出 窗口(OUTPUT)。
程序窗口的使用类似于Windows中的记事本程序,可以在其中编辑文本文件,主要是编辑SAS 程序。程序可以直接在窗口中键入,插入新行用回车,插入点光标(闪动的竖线)可以用光 标键(上下左右箭头、Home、End)移动或用鼠标单击到某一处。按住Shift再按光标键可以 加亮显示一块文本,然后用复制、剪切、粘贴命令(Edit菜单中的Cut、Copy、Paste,或工 具栏图标)可以复制或移动加亮显示的文本。这些编辑操作具体请参考Windows的有关文档。
运行记录窗口记录程序的运行情况,运行是成功还是出错,运行所用时间,如果出错,错 在什么地方。运行记录窗口中以红色显示的是错误信息。
输出窗口显示SAS程序的文本型输出(图形输出单独有一个GRAPHICS窗口)。输出分页显 示。
要把光标移动到某一窗口,可以用主菜单中的Window菜单选择要显示的窗口。用功能键F5 可以切换到程序窗口,F6可以到运行记录窗口,F7可以到输出窗口。
SAS主窗口标题栏下是主菜单。SAS菜单是动态的,其内容随上下文而不同,即光标在不同 窗口其菜单也不同。其中,File(文件)菜单主要是有关SAS文件调入、保存及打印的功能。Edit (编辑)菜单用于窗口的编辑(如清空、复制、剪切、粘贴、查找、替换)。Locals(局部 )菜单与当前正在进行的操作有关,如果你正在程序窗口中编辑程序,则Locals菜单有提交 运行、调回修改等项,如果在运行记录窗口或输出窗口则Locals菜单项根本不出现。Globals 菜单内容比较复杂,它可以打开被关闭的程序窗口、运行记录窗口、输出窗口、图形窗口, 可以进入SAS提供的各个独立模块。主菜单下是一个命令条和工具栏菜单。命令条主要是用于 与SAS较早版本的兼容性,可以在这里键入SAS的显示管理命令。工具栏图标提供了常见任务 的快捷方式,比如保存、打印、帮助等等。鼠标光标在某一工具栏图标上停留几秒可以显示 一个说明。工具栏图标的解释如下:
![]() Submit - 提交编辑窗口中的程序
Submit - 提交编辑窗口中的程序
![]() New - 清空编辑窗口
New - 清空编辑窗口
![]() Open - 打开文件到编辑窗口。用户指定
一个文件调入到编辑窗口内。这个文件从此与编辑窗口相关联,以后的存盘操作将自动存入
这个文件。
Open - 打开文件到编辑窗口。用户指定
一个文件调入到编辑窗口内。这个文件从此与编辑窗口相关联,以后的存盘操作将自动存入
这个文件。
![]() Save - 存盘,保存编辑窗口内容,注意
如果此窗口已经与一个文件相联系的话此功能将覆盖文件的原有内容而不提示。
Save - 存盘,保存编辑窗口内容,注意
如果此窗口已经与一个文件相联系的话此功能将覆盖文件的原有内容而不提示。
![]() Print - 打印当前窗口内容
Print - 打印当前窗口内容
![]() Print preview -打印预览。
Print preview -打印预览。
![]() Cut - 剪切选定文本。
Cut - 剪切选定文本。
![]() Copy - 复制选定文本。
Copy - 复制选定文本。
![]() Paste - 粘贴。注意这些操作是对Windows
剪贴板进行的,可以用来与其它Windows应用程序交换文本、数据等。剪切或复制到剪贴板的
内容可以被其它应用程序粘贴,其它应用程序放到剪贴板的内容也可以粘贴到SAS的编辑窗口
中。
Paste - 粘贴。注意这些操作是对Windows
剪贴板进行的,可以用来与其它Windows应用程序交换文本、数据等。剪切或复制到剪贴板的
内容可以被其它应用程序粘贴,其它应用程序放到剪贴板的内容也可以粘贴到SAS的编辑窗口
中。
![]() Undo - 撤销刚才的编辑操作。
Undo - 撤销刚才的编辑操作。
![]() DOS prompt - 临时进入DOS。
DOS prompt - 临时进入DOS。
![]() Browse - 打开WWW浏览器并进入SAS公司
的主页
www.sas.com。
Browse - 打开WWW浏览器并进入SAS公司
的主页
www.sas.com。
![]() Directories - 进入Directory(目录)
窗口,可以浏览各SAS数据库的内容,可以浏览数据库中的数据集、SAS目录的内容。
Directories - 进入Directory(目录)
窗口,可以浏览各SAS数据库的内容,可以浏览数据库中的数据集、SAS目录的内容。
![]() SAS/ASSIST - 启动SAS的菜单驱动界面SAS/ASSIST
。
SAS/ASSIST - 启动SAS的菜单驱动界面SAS/ASSIST
。
![]() Help - 启动Windows的帮助系统进入SAS
的帮助。
Help - 启动Windows的帮助系统进入SAS
的帮助。
假设我们有一个班学生的数学成绩和语文成绩,数学满分为100,语文满分为120,希 望计算学生的平均分数(按百分制)并按此排名,可以在程序窗口输入此程序:
title '95级1班学生成绩排名'; data c9501; input name $ 1-10 sex $ math chinese; avg = math*0.5 + chinese/120*100*0.5; cards; 李明 男 92 98 张红艺 女 89 106 王思明 男 86 90 张聪 男 98 109 刘颍 女 80 110 ; run; proc print;run; proc sort data=c9501; by descending avg; run; proc print;run;
实际上,输入这样包含中文的程序最好办法不是在SAS程序窗口直接输入,因为SAS目前对 中文输入的处理还不够完善,好的办法是打开一个其它的编辑程序如Windows中的记事本(在Win95 中用开始菜单中的“程序 | 附件 | 记事本”启动),在记事本中复制输入的程序,然后到SAS 系统程序窗口中使用粘贴命令(用Edit菜单的Paste或工具栏上的粘贴图标),把程序复制到SAS 中。也可以在记事本中把编好的程序存盘,然后在SAS程序窗口用File菜单的Open命令打开保 存好的程序文件。
要运行此程序,只要用鼠标单击工具栏的提交图标
![]() ,或用Locals菜单的Submit命令。运行后,运
行记录窗口出现如下内容:
,或用Locals菜单的Submit命令。运行后,运
行记录窗口出现如下内容:
50 title '95级1班学生成绩排名'; 51 data c9501; 52 input name $ 1-10 sex $ math chinese; 53 avg = math*0.5 + chinese/120*100*0.5; 54 cards; NOTE: The data set WORK.C9501 has 5 observations and 5 variables. NOTE: The DATA statement used 0.11 seconds. 60 ; 61 run; 62 proc print;run; NOTE: The PROCEDURE PRINT used 0.0 seconds. 63 proc sort data=c9501; 64 by descending avg; 65 run; NOTE: The data set WORK.C9501 has 5 observations and 5 variables. NOTE: The PROCEDURE SORT used 0.05 seconds. 66 proc print;run; NOTE: The PROCEDURE PRINT used 0.0 seconds.
其中记录了每段程序的运行情况、所用时间、生成数据保存情况。如果有错误还会用红色 指示错误。比如,最后的proc print后面的分号如果丢失,记录窗口显示如下错误:
67 proc printrun;
--------
181
ERROR 181-322: Procedure name misspelled.
错误说明为过程名错拼,但实际上是丢了分号导致print和run连成了一个词。在程序窗口 用“Locals | Recall text”菜单或按F4功能键可以调回程序修改。正确运行后输出窗口出 现如下结果:
95级1班学生成绩排名 3
OBS NAME SEX MATH CHINESE AVG
1 李明 男 92 98 86.8333
2 张红艺 女 89 106 88.6667
3 王思明 男 86 90 80.5000
4 张聪 男 98 109 94.4167
5 刘颍 女 80 110 85.8333
95级1班学生成绩排名 4
OBS NAME SEX MATH CHINESE AVG
1 张聪 男 98 109 94.4167
2 张红艺 女 89 106 88.6667
3 李明 男 92 98 86.8333
4 刘颍 女 80 110 85.8333
5 王思明 男 86 90 80.5000
这里有两页输出,第一页是输入数据后用PROC PRINT显示的数据集,第二页为按平均分排 名后的结果。
从上面的例子程序可以看出SAS程序的一些特点。SAS程序由 语句组成,语句用分号结束。SAS程序中大小写一般不区分(字符串中要区分大小写 )。SAS程序中的空格、空行一般可以任意放置,这样我们可以安排适当的缩进格式使得源程 序结构清楚易读。SAS程序由两种“步”构成,一种叫 数据步(data step),一种叫 过程步(proc step),分别以DATA语句和PROC语句开始。数据步和过程步由若干个 语句组成,一般以RUN语句结束。
本节介绍一些SAS特有的概念,其中最重要的是数据集。
SAS数据集(SAS Datasets)可以看作由若干行和若干列组成的表格,类似于一个矩 阵,但各列可以取不同的类型值,比如整数值、浮点值、时间值、字符串、货币值等等。SAS 数据集存放在以特殊格式存放的二进制文件中,我们用一个SAS中的逻辑名来使用SAS数据集 而不需关心它到底如何存储在磁盘上。比如,1.1.3的例子生成了一个名为C9501的数据集, 它的逻辑形式如下表:
|
NAME |
SEX |
MATH |
CHINESE |
AVG |
|
李明 |
男 |
92 |
98 |
86.8333 |
|
张红艺 |
女 |
89 |
106 |
88.6667 |
|
王思明 |
男 |
86 |
90 |
80.5000 |
|
张聪 |
男 |
98 |
109 |
94.4167 |
|
刘颍 |
女 |
80 |
110 |
85.8333 |
数据集的每一行叫做一个观测(Observation),每列叫做一个变量(Variable)。SAS数 据集等价于关系数据库系统中的一个表,实际上一个SAS数据集有时也称作一张表。在数据库 术语中一个观测称作一个记录,一个变量称作一个域。在C9501数据集中有5个观测,分别代 表5个学生的情况,而每个学生有5个数据,分别为姓名、性别、数学成绩、语文成绩、平均 分,所以此数据集有5个变量。
从上面看出,数据集要有名字,变量要有名字,所以SAS中对 名字(数据集名、变量名、数据库名,等等)有约定:SAS名字由英文字母、数字、 下划线组成,第一个字符必须是字母或下划线,名字最多用8个字符,大写字母和小写字母不 区分。比如,name,abc,aBC,x1,year12,_NULL_等是合法的名字,且abc和aBC是同一个 名字,而class-1(不能有减号)、a bit(不能有空格)、serial#(不能有特殊字符)、Documents (超长)等不是合法的名字。
SAS数据集是各种特殊格式的 SAS文件中最重要的一种。另一种重要的SAS文件是 SAS目录(Catalog),用来保存各种不能表示成行列结构表格形式的数据,比如系统 设置、图象、声音等。多个SAS文件可以放在一起,称为一个 SAS数据库(Library)。数据库有一个库名(Libname),其命名遵循上述SAS名字命 名原则。在MS DOS/Windows环境中,一个SAS数据库实际是磁盘上的一个子目录(特殊情况下 一个数据库可以由几个子目录组成)。为了把库名和子目录联系起来,使用LIBNAME语句。比 如,我们在C:\Y1995子目录中保存了几个SAS数据集,可以用如下语句把库名MYLIB与子目录C:\Y1995 联系起来:
libname mylib "c:\y1995";
有三个预定义的SAS数据库:WORK、SASUSER、SASHELP。其中,WORK数据库叫做 临时库,存放在其中的SAS文件叫 临时文件,这些临时文件当退出SAS系统时会被自动删除。SASUSER库保存与用户个人 设置有关的文件,它是永久的,即退出SAS时文件不会被删除。SASHELP库保存与SAS帮助系统 、例子有关的文件,是永久的。
从上面看出,SAS文件分为 临时文件和 永久文件:临时文件在退出SAS系统时自动被删除,永久文件在退出SAS系统时不自动 被删除。所以,我们把作为中间结果使用的数据集或练习用的数据集作为临时数据集保存, 而需要以后再用的数据集则可以保存为永久数据集。临时数据集和永久数据集的区别是:临 时数据集可以用 单水平名,即只有数据集名,比如C9501,而永久数据集名由两部分组成,前一部分 是它的库名,后一部分才是数据集名,两部分中间用小数点连接,比如放在MYLIB库(即"C:\Y1995" 子目录)中的数据集TEACH必须用MYLIB.TEACH表示。这样指定的数据集名在生成时可以放到 由库名指定的子目录中,在读取时可以到指定的子目录读取,并且不会被自动删除。
临时数据集除用单水平名外 ,也可以用库名为WORK的两水平名,如WORK.C9501和C9501 是一样的。
要生成永久数据集,只要在指定要生成的数据集名时使用两水平名且库名已有定义, 比如,要把上面的C9501数据集在生成时就放到"C:\Y1995"子目录中,可以用如下语句:
libname mylib "c:\y1995"; data mylib.c9501; …… proc sort data=mylib.c9501; ……
这个程序和1.1.3的例子相比只是增加了一个定义库名的LIBNAME语句,然后在所有用到数 据集名C9501的地方换成了两水平名MYLIB.C9501。要注意生成的数据集是MYLIB.C9501后面在 用到它的时候(在PROC SORT中)也必须使用两水平名MYLIB.C9501而不能使用单水平名C9501 ,这两个名字指向的不是同一个SAS文件。
为了显示现有定义的数据库,只要单击工具栏的
![]() 图标,如图 2。
图标,如图 2。
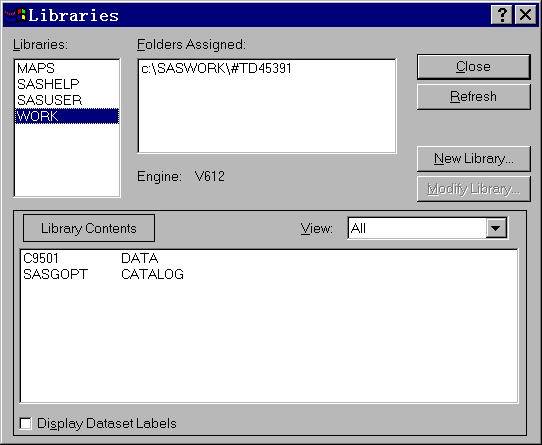
Libraries窗口显示了现有定 义的所有数据库及其对应的子目录,并在窗口下方显示了选定的数据库中的SAS文件列表。文 件列表第一列是SAS文件名称,第二列是其类型,DATA代表数据集。双击某一数据集名可以打 开此数据集到一个数据显示窗口查看。
SAS的使用方法一般是象1.1.3那样输入一个程序,运行,修改,最后在输出窗口得到 结果。随着图形界面、用户友好等程序思想的发展,SAS也逐渐提供了一些不需要学习SAS编 程就能进行数据管理、分析、报表、绘图的功能,其中做得比较出色的一个是SAS/INSIGHT模 块。SAS/INSIGHT是在基本的SAS系统基础上添加的一个模块,提供了数据交互输入、数据探 索、分布研究、相关分析、各种图形等功能。这里我们初步介绍SAS/INSIGHT的使用。
要启动SAS/INSIGHT,选Globals | Analyze | Interactive data analysis菜单,首 先出现图 3那样的选择数据集的窗口:
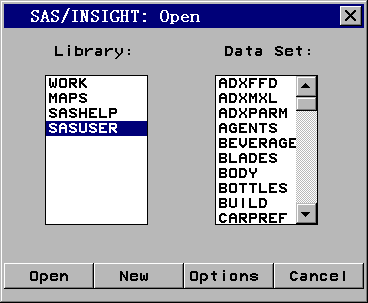
这是SAS/INSIGHT必须先选择一个要分析、观察的数据 集。如果要生成新数据集,按New按钮,如果要打开已有数据集,按Open按钮。 图 4是SAS/INSIGHT运行时的样子。
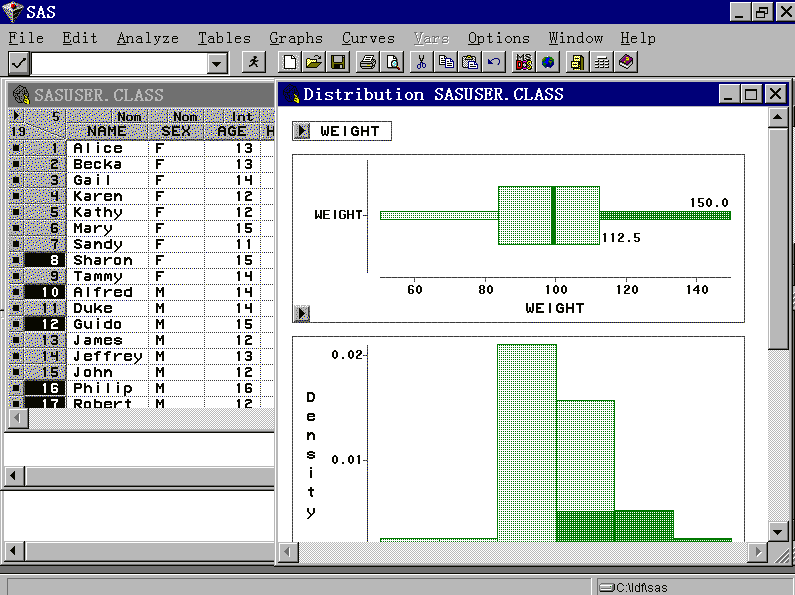
SAS/INSIGHT提供了一个类似于电子表格的数据窗口来管理数据集。图 5为显示了数 据集SASUSER.CLASS的数据窗口:
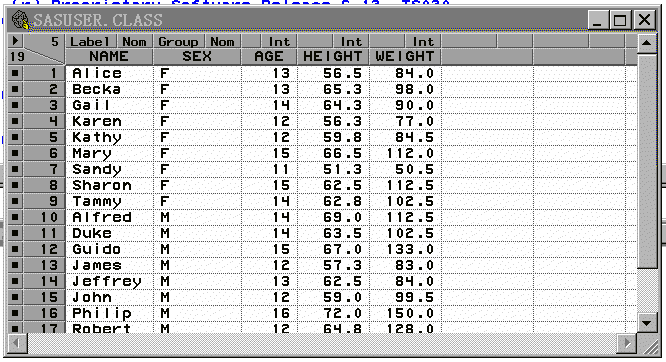
此数据集是一个班19个学生的一些情况,包括姓名、性别、 年龄、身高、体重。我们看到,数据窗口标题行显示了打开的数据集的名字,标题行下左上 角有一个向右的小三角,这是数据窗口的菜单,见图 6:
三角下方的19是观测行数,右方的5 是变量个数。窗口内每行最左边的方块是观测的绘图标记,用于在图形中标记观测;然后是 观测序号;再往右是各变量的值。数据窗口中的各变量用作列标题,如图 5中的NAME、SEX、AGE 、HEIGHT、WEIGHT就是数据集SASUSER.CLASS中的五个变量的名字。在每一个变量名的上面有 两个标签,右边一个代表变量的量测水平,分为区间变量(Int)和名义变量(Nom)。区间 变量是取连续值的变量,只能为数值;名义变量是取离散值的变量,一般为字符型,也可以 取数值。变量名上面左边的标签代表变量在分析中的缺省用途,比如NAME上面的Label表示此 变量的值(学生姓名)在绘图中用来标记观测,SEX上面的Group表示此变量(性别)用来分 组,等等。
数据窗口可以用来建立新数据集。在SAS/INSIGHT内用“File | New”菜单或在启动INSIGHT 的窗口(图 3)按“New”按钮,将出现一个空的数据窗口。这时,可以直接向第一行输入数 据,比如要输入 1.1.3 中的C9501数据集,就可以在第一行的前四列中分别输入李明、男、92 、98,这时各列自动取变量名为A、B、C、D,而且量测水平自动定为前两个字符型是名义变 量(Nom),后两个数值型是区间变量(Int)。为了修改变量名和变量的用途,从数据窗口 的菜单(图 6)选Define Variables,出现图 7的定义变量窗口:
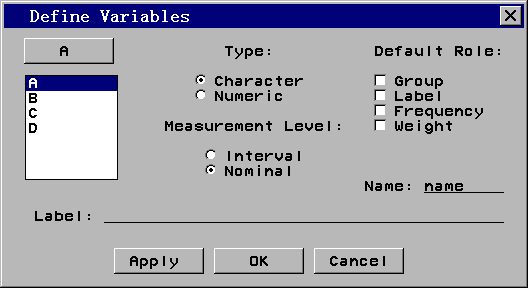
在这里可以修改变量名, 给变量加标签(Label),可以选择变量的量测水平,可以规定变量的用途。变量的标签是对 变量的一个可以长达40个字符的描述,可以用于以后的输出,可以用汉字。
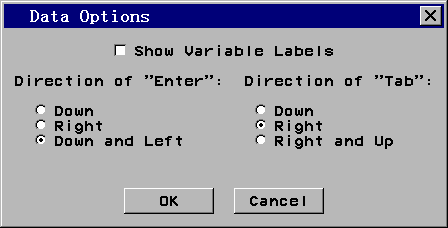
定好变量名等属性后就可以继续输入其它数据行,每输入一行后回车,直至把全部数据输 完。为了使回车时光标从前一行尾部进到下一行第一格,可以从数据窗口菜单(图 6)中选 “Data Options”,在弹出的对话框中(图 9):
选择回车的方向(Direction of Enter)为 左下(Down and Left)。为了保存输入的数据集,选“File | Save | Data”菜单,出现图 8 那样的输入数据集的窗口:
可以选择数据集放在哪一个数据库,可以输入一个数据集名,把 这里的A改成c9501,按OK钮就可以保存数据集。对于比较小的数据集(几个、十几个变量, 几十个观测),用SAS/INSIGHT的数据窗口可以迅速而直观地输入。对于更大量的数据,一般 从其它格式转换而得。
在数据窗口中如果需要修改某一个值,只要直接用鼠标点到其单元格修改,然后把输入光 标离开其所在行就实现了修改。在单元格之间移动可以用鼠标单击、制表键、回车、上下光 标键等方法。要保存所作的修改还需要用“File | Save | Data”菜单。
当数据窗口中变量较多时,可以用滚动条滚动窗口内容来查看。如果某个变量比较重要, 可以考虑把它放到第一列的位置,这只要先单击该变量的名字选中它,然后在图 6的菜单中 选Move to First。要把某列移到最后,选中它后用Move to Last菜单。
选中一列只要单击其变量名。如果要选中多个列,在选中一个后按住Ctrl键单击其它的名 字可以添加选中其它变量。选中一个变量后按住Shift单击另一个变量名可以选中这两个变量 及它们之间的所有变量。选中的多个列也可以用Move to First和Move to Last移动。
要选中一个观测(行),只要单击其观测号(行号)。选多个观测可以用Ctrl单击或Shift 单击的方法。选中的观测也可以用Move to First和Move to Last移动到最前或最后。
还可以选中某些列同时选中某些行。只要在后续的选中操作时用添加选中(Shift单击或Ctrl 单击)即可。用鼠标在数据窗口数值显示部分拖出一个方框也可以选定一部分数值。
选定了列或者行以后,用“Edit | Delete”菜单可以删除选定的列或行。
要取消所有选中,只要单击某一单元格而不是行、列标题即可。
下面简单介绍一下数据窗口菜单(图 6)中各命令:
SAS/INSIGHT提供了十分方便的数据探索功能。对一维数据,可以作直方图、盒形图 、马赛克图,对二维数据,可以作散点图、曲线图、散点图矩阵,对三维数据可以作旋转图 (三维散点图)。在图上可以选定一些观测,这些选择结果会同时反映在数据窗口和其它图 中。
以SASUSER.CLASS数据集为例。选定变量HEIGHT,用“Analyze | Histogram/Bar Charts(Y) ”菜单可以打开一个图形窗口生成身高的分布 直方图,如图 10。
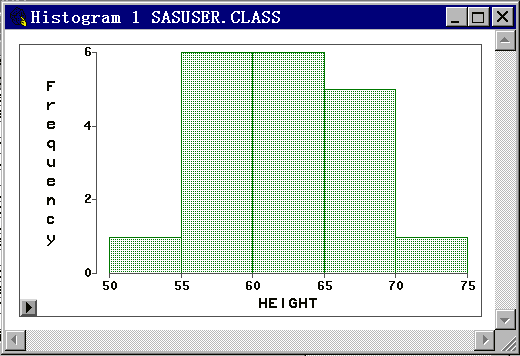
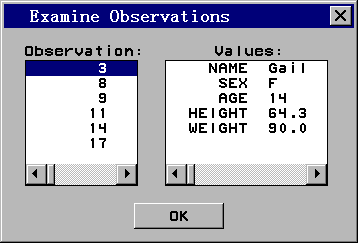
直方图的每一个条形代表了绘图变量(HEIGHT)在一个区间的取 值情况,比如70到75之间的条形代表身高在70到75英寸的人,条形高度为组频数,即取值在 这一区间的观测个数,可以看出这一组有一个学生。单击这一条形选中在此范围的观测,可 以发现这时数据窗口的相应观测也被选定了,被选中的是Philip,身高72英寸。如果双击某 一条形,比如60到65的条形,就可以在选定相应观测的同时弹出一个检查观测窗口,窗口中 显示各被选中的观测序号,以及其中一个观测的各变量值。这样可以很方便地检查图中各部 分所对应的观测。为取消选定,只要在图中空白处单击即可。
作出的图形有一个方框包围。如果想改变图形大小,可以单击方框使其变粗,然后拖动四 个角中的一个,就可以把图形放大或缩小。甚至还可以把一个角向其对角方向拖动一直拖过 对角,这样可以改变图形的横纵轴方向。拖动边框可以把图形移动到窗口内其它位置。
图形中提供了一个设置菜单,可以单击图形边框角上的向右箭头或在图形内右键单击来打 开。菜单内容包括Ticks,可以设置坐标轴的具体画法;Axes用来指定画不画坐标轴;Observations 用来指定是否画观测;Values指定是否标出各条形高度值。
对连续数据(Int型)作直方图可以反映其分布情况,对离散数据(Nom型)作直方图同样 可以反映其分布,即取每一个离散值的比例大小(频数分布)。比如,在作了身高的直方图 后,选定变量SEX,对其作直方图,则结果打开一个新图形窗口作出只有两个条形的条形图, 一个标记为F,另一个标记为M,高度分别为9和10,即有9个女生,10个男生,男女比例为10 :9。单击标F的条形,可以看到数据窗口中所有女生的观测被选定,另外还可以看到已作的 身高的直方图也发生了变换,身高的每一个条形都分成了颜色不同的两部分,其中下面的一 部分代表女生。
在用Analyse菜单中的作图命令作图时如果没有选定的变量则弹出一个对话框提问用哪一 个变量作图,如果对身高作图,只要选HEIGHT然后按Y钮即可。
盒形图是另一种表现数值型变量分布的图形。比如,要画身高分布的盒形图,选 定变量HEIGHT然后用“Analyse | Box Plot/Mosaic Plot”可以作出图 12。
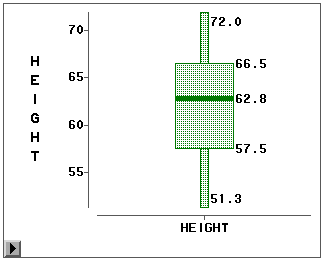
从图形菜单中选Values 可以标出图中重要数据值。可以看出,此盒形图的横轴没有用处,纵轴代表身高的取值范围 。盒形的中间有一条粗线,这是身高分布的中位数的位置,盒子上边线是分布的四分之三分 位数,下边线是分布的四分之一分位数,盒子上下边线包含了分布的中间50%的观测。盒子的 长度叫做分布的四分位间距,其作用类似于标准差,可以反映数据分布的分散程度。从盒子 边线向外画了两条线叫做触须线,最长可以延伸到四分位间距的1.5倍,但是如果已经到了数 据的最小值或最大值处就不再延伸。如果触须线没有达到数据的极端值,则这些数据点用触 须线以外的点来画出,一般认为这样的点是异常点。从盒形图可以看出数据的偏斜情况,比 如我们看到盒子的下半部比上半部长,而且下触须线比上触须线长,说明身高分布略左偏。
用盒形图菜单中的“Means”选项可以在盒形图上加画一个菱形,菱形的中间代表分布的 平均值,菱形端点到中间距离为两倍标准差。如果是变量服从正态分布,菱形上下端点之间 应该包含大约95%的观测。平均值和中位数的比较也能反映变量的偏斜情况,平均值低于中位 数可能左偏。
单击或双击盒形图的某一部分(盒子上半部或下半部、触须线、极端值)可以选定观测。
盒形图可以方便地比较按某分组变量分组后的分布情况。比如,如果我们想看一看男女的 身高分布有何异同,不选任何变量启动“Analyze | Box Plot/Mosaic Plot”菜单,弹出选 择变量的对话框如图 13。
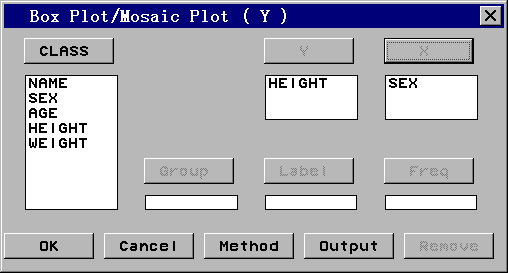
选身高为Y变量,选性别为X变量,画出的图见图 14。
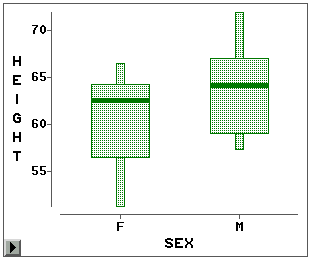
图中有两个 盒形图,女生一个,男生一个。从图中看出,男生身高普遍高于女生,且女生身高分布左偏 较男生严重。这种并排盒形图可以十分直观地比较两个相关的分布。作盒形图时指定多个Y变 量也可以作出并排的盒形图,比如,同时指定身高和体重作为Y变量作盒形图就可以生成身高 和体重的并排的盒形图。
Analyze菜单的“Box Plot/Mosaic Plot”命令对连续型变量作盒形图,对离散型变量将 作 马赛克图。比如,对性别变量作图得图 16。
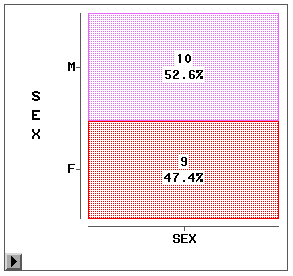
选“Values”菜单后标出了男女的人数 、百分比。马赛克图一般不对单个变量作,而是对两个离散变量来作。比如,先把SASUSER.CLASS 中变量AGE的量测水平由Int改为Nom,然后取消所有变量的选定,启动“Box Plot/Mosai Plot ”,选SEX为Y变量,选AGE为X变量,作图如图 15。
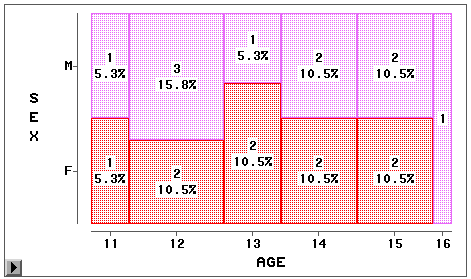
这种图的好处是直观显示了两个变量每种 取值组合的观测个数和比例。单击或双击其中一个方块可以迅速选中一个分组,比如双击年 龄为11性别为女(F)的方块可以看到这一组的学生。
SAS/INSIGHT可以作曲线图、散点图、散点图矩阵,可以在散点图中刷亮观测。
曲线图有一个取值由小到大的X变量,有一个或几个Y变量,以X变量为横坐标对Y 变量画曲线。为了演示曲线图,打开SASUSER.AIR数据集(用“File | Open”菜单)。这个 数据集是德国某城市一周的每小时记录的空气污染情况。变量DATETIME是记录的日期时间, 为特殊SAS格式数据,变量DAY为星期几,HOUR为几点钟,CO、O3、SO2、NO、DUST分别为一氧 化碳、臭氧、二氧化硫、一氧化氮、粉尘的浓度,WIND为风速。要画一氧化碳的曲线图,可 以在未选任何变量的情况下用“Analyse | Line Plot”,弹出变量对话框(图 17)。
选DATETIME 为X变量,CO为Y变量,可以画出CO的时间序列曲线图。
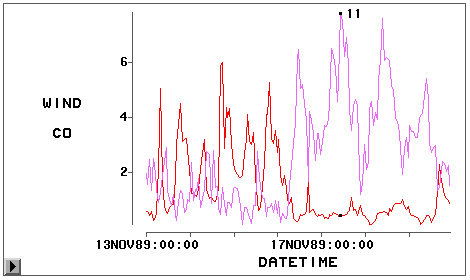
单击曲线上某一个点可以显示其观测 序号,双击可以检查观测。如果想单击曲线上点时不显示观测序号而显示记录时间是几点, 可以在曲线图窗口中选主菜单的“Edit | Window | Renew”,可以再弹出变量窗口,选HOUR 并按Label钮把时间指定为标签变量。这时在作的CO的曲线图上单击一个点显示的就是记录时 间了。可以看出CO的高峰一般在早晨8点和晚上17点-21点。用图形菜单(右键或单击向右三 角)中的Observations可以画出各个数据点的符号。
可以在图上同时画出多条曲线。比如,想考察风速对污染的影响,在图形窗口中再用主菜 单的“Edit | Window | Renew”,把WIND也作为Y变量,画出的图就有两条不同颜色的曲线 ,单击外面的CO变量符号和WIND变量符号可以加重显示对应的曲线以区分这两条曲线。见图 18 。图中被选的点是风速的最高值,时间是11点。注意在一条曲线中被选在另一条曲线中也被 选。从此图可以看出风速对污染有较明显的影响,风大时污染较轻。
散点图也有一个X变量和一个Y变量,但不要求X变量有从小到大的次序,画图不用 连线而是用散点画出每一对X、Y坐标。比如对SASUSER.CLASS,我们希望通过画图了解身高和 体重的关系。在数据窗口中先选定体重(Y轴变量)再附加选定身高(X轴变量),启动菜单 “Analyze | Scatter Plot”,就可以生成以体重为纵轴以身高为横轴的散点图(见图 19) 。
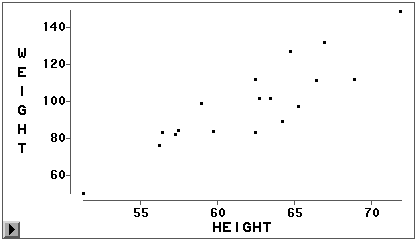
从图可以看出体重与身高有明显的线性相关关系。
为了解哪一个点代表哪一个学生,单击一个点可以显示其观测序号,双击可以检查观测。 为了在单击时可以显示学生名字而不是观测序号,需要把NAME指定为标签变量。这可以在生 成散点图时先不在数据窗口选X、Y变量而是直接启动“Analyze | Scatter Plot”菜单,弹 出变量对话框,在其中选X、Y变量并把NAME指定为Label变量。这时,单击散点图中最左下角 的那个点可以显示名字Sandy,单击最右上角的那个点可以显示Philip。选多个点可以用附加 选中的办法(Shift或Ctrl单击)。
为了在散点图中选定多个点,SAS/INSIGHT还提供了一种称为“ 刷亮(Brushing)”的操作。在图中拖动鼠标光标可以拖出一个小长方形,在这个长 方形中的点都被选中,称它为刷子。选中的点在数据窗口也被选中,可以在数据窗口翻页查 看,或用数据窗口的Find Next菜单命令查看,或在数据窗口用Move to First菜单命令把选 中的点移到最前查看。双击长方形(刷子)可以弹出检查观测窗口,在那里可以逐个查看选 中的观测内容。
拖动刷子的角可以改变其大小。拖动刷子内部可以移动它的刷亮位置,使进入刷子的点被 选中,而离开了刷子的点被取消选中。可以同时用附加选中(Ctrl单击)的办法加选不在刷 子内的点,这些点还可以显示标签。在拖动刷子时如果同时按住Shift或Ctrl键则为附加选定 ,即进入刷子的点被选中而离开刷子的点仍保持被选中。可以按住Shift或Ctrl键拖出第二个 刷子,这时第一个刷子不再显示但它刷亮的点仍保持刷亮,移动第二个刷子时如果按住Shift 或Ctrl键仍可保持已有选定。为了取消所有选定,只要点击图内空白处。
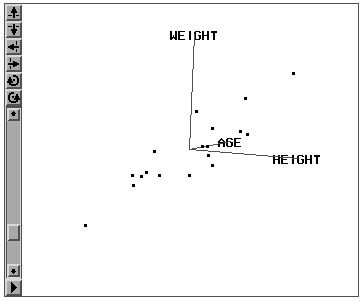
散点图矩阵画出多个变量两两间的散点图以考察多变量关系。以SASUSER.CLASS为 例,比如说我们想了解年龄、身高、体重间的关系。先把年龄的量测水平设为连续型(Int) ,在数据窗口选定年龄、身高、体重,可以作出图 20。
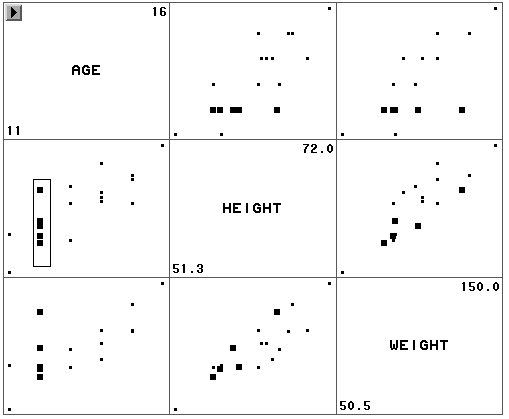
我们看到三个变量两两组合有三种组 合,每种组合有两个图形(横纵轴对换)。散点图矩阵对角线为变量标记和变量取值范围, 该变量是其所在行的纵轴变量,是其所在列的横轴变量。比如第二行第一列的图纵轴变量是HEIGHT ,横轴变量是AGE,为身高对年龄的散点图。其对称位置(第一行第二列)是年龄对身高的散 点图,两者只是把横纵坐标旋转对调。
散点图矩阵除了可以同时看到多个散点图的优点外主要是在一个散点图中被选中的点在其 它散点图和数据窗口中也同时被选中。这样,我们可以在一个图中选一个极端点,看它在其 它图中是否也处于极端位置。在一个散点图中刷亮的点在其它散点图中也同时被刷亮,这样 ,我们可以观察,年龄和身高都比较小时,体重是否也比较低。可以移动刷子,同时其它散 点图中被选中的点也在变化。从图 20可以看出,年龄由小到大变化时身高、体重一般也变大 ,但同一年龄的学生的身高、体重差距较大。
SAS/INSIGHT提供了自动移动刷子的功能。在拖动刷子时松开鼠标按钮,类似于“抛出” 刷子,刷子就可以按抛出的方向继续移动并反弹。不过现在还较难控制自动移动的速度,有 时移动过快。
SAS/INSIGHT对三维数据可以作称为旋转图的三维散点图。比如,要对SASUSER.CLASS 中的学生年龄、身高、体重作三维散点图,在数据窗口依次选定AGE、HEIGHT、WEIGHT,然后 启动菜单“Analyze | Rotating Plot”,可以生成一个三维散点图。图 21是经过旋转后的图 形。
这种三维散点图之所以称为旋转图,是因为坐标系可以在三维空间绕原点任意旋转。图形 的左侧有一个小工具栏,其中有向上、下、左、右、逆时针、顺时针旋转的图标,再往下有 一个滚动条,用它来规定自动旋转的速度。左下角是图形的菜单(向右的三角形)。
为了旋转坐标系,单击左侧的旋转方向图标。按住旋转图标可以连续旋转。按住Shift或Ctrl 再旋转可以实现自动旋转。当鼠标光标移到图形的四个角时光标形状变成了手的形状,单击 可以旋转,拖动可以连续旋转,拖动时“抛出”可以自动旋转。自动旋转中可以随时拖动图 形以改变旋转方向。

旋转图的菜单(图 22)中,Ticks用来调整坐标轴刻度,Axes可以选坐标轴以数据中心点 为原点、以左端点为原点、不画坐标轴。Observations指定画出所有观测,如果没有选中此 项则只画被选中的观测。Rays从原点向每个散点画射线。Cube在散点四周画一个长方体盒子 。Depth可以使离视点近的点画得较大,离得远的点画得较小。Fast Draw指定用另一种较快 的绘图方法绘图。Markers Sizes选择散点的大小。
SAS/INSIGHT提供了很强的调整绘制的图形的功能。比如,调整坐标轴的画法,点的 大小、符号、颜色,隐藏某些观测,等等。
给不同观测使用不同的符号和颜色画点有助于迅速区分不同类观测的特点。比如,SASUSER.IRIS 数据集中包含了Fisher著名的Iris数据,其中有三种不同的鸢尾属植物的花瓣、花萼长、宽 的测量数据,希望从这些测量数据找出区分这三种植物的指标。为了直观看到不同植物的测 量数据的特征,最好用不同颜色画每一种植物的散点。打开数据集后,选定分类变量SPECIES ,调用“Analyse / Box Plot / Mosaic Plot”菜单来作其马赛克图,可以看到此变量的三 个值为Virginica、Versicolor、Setosa。用“Edit | Windows | Tools”菜单可以打开一个 工具窗口,如图 23。这个窗口可以改变观测符号的颜色、符号,连线的线型、线宽,可以放 大图形局部。

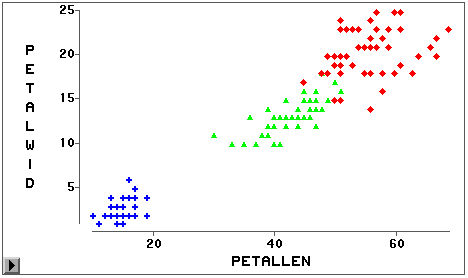
在打开的马赛克图中先选定Virginica,这时所有类型Virginica的观测被选中 ,按一下工具窗口中的红色,就给所有这些观测规定了绘图符号为红色。类似指定Virsicolor 为绿色,Setosa为蓝色。作PETALWID(花瓣宽)对PETALLEN(花瓣长)的散点图,可以作出 三种不同植物用不同颜色绘点的散点图,见图 24。
利用一个变量的不同值来确定观测绘点的颜色还可以自动进行,方法是先选定该变量(如SPECIES ),然后单击工具窗口的渐变颜色棒,就可以为SPECIES的每一不同值分配一种不同颜色。这 一方法不仅适用于SPECIES这样的名义变量,也适用于数值型变量。颜色棒的颜色可以调整, 比如要把颜色棒变为由红到蓝,只要把红色方块拖到颜色棒左端,把蓝色方块拖到颜色棒右 端。
为了改变绘点符号的大小,调用图形菜单(图形边角上的向右三角符号)中的Marker Sizes 菜单可以选择一个合适的符号大小。
除了用不同颜色来区分不同种类的观测外,还可以用不同的符号来画不同的观测。比如, 选定SPECIES为Virginica的观测后,单击工具窗口的菱形图标把此类观测的绘点符号变为菱 形。类似指定Virsicolor用三角,Setosa用加号,作的散点图见图 24。从图中可以看出,用 加号绘制的Setosa类和其它两类差别很大,单靠花瓣的长、宽就可以把这一类与其它两类区 分开,但是用菱形绘制的Virginica类和用三角绘制的Virsicolor类则在能大体区分开的同时 有少数观测混杂在一起,所以单靠花瓣的长、宽测量数据不能把这两两很好地区分开。
利用一个分类变量来决定不同的绘点符号除了上述的对每一类观测分别选定,然后指定绘 点符号的办法,还可以选定这一分类变量,然后单击工具栏中绘点符号下面的多种符号的长 棒形图标,可以自动为每一类分配一个绘点符号。
不同类观测用不同的颜色和符号来绘点是一种强有力的数据探索手段,恰当使用可以直观 地发现不同类型观测的区别。
SAS/INSIGHT提供了很强的一维分布研究功能。对连续型变量,除了可以画直方图、 盒形图外,还可以作各种统计表,比如矩、分位数表,可以在直方图上画拟合密度曲线,可 以检验分布是否来自正态、对数正态、指数、威布尔分布,等等。对离散型变量,可以画马 赛克图、条形图、频数表。
为了研究SASUSER.CLASS中身高的分布,在未选中变量的情况下,启动“Analyze | Distribution(Y) ”菜单,出现图 25的选择变量对话框:
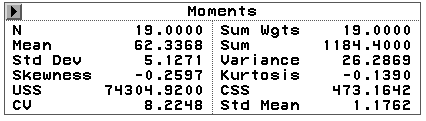
选Y变量为HEIGHT,按OK可以打开一个新窗口,显示 身高的直方图、盒形图、矩统计量表(图 26):
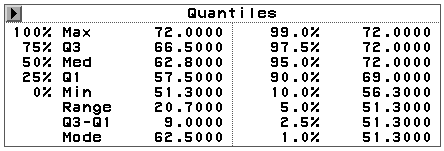
分位数表(图 27):
各统计量是SAS中经常使用的,我们在此加以说明。设变量为
![]() ,各观测值为
,各观测值为
![]() 。有时每个观测还带一个加权
。有时每个观测还带一个加权
![]() ,在没有指定加权变量时认为加权恒为1。
,在没有指定加权变量时认为加权恒为1。
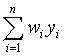
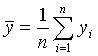
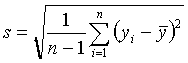
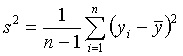
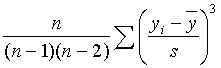
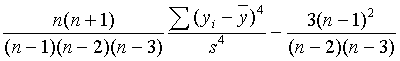
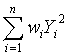
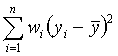
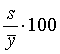
其中加权的常见情形是当一个观测实际代表完全相同若干个样品时,求和、平方和等都要
加权。比如,第i个观测代表
![]() 个样品时,求变量Y的真正总和就需要用加权
公式
个样品时,求变量Y的真正总和就需要用加权
公式
![]() 。偏度可以表现变量分布的偏斜,负值为左
偏,正值为右偏。峰度表现变量分布与正态分布相比是重尾(分布函数在正负无穷处衰减缓
慢)还是轻尾(分布函数在正负无穷处衰减迅速)。标准误差在统计中是一个十分重要的概
念,它代表估计量作为随机变量其标准差的估计,这里的Std Mean是均值的标准差的估计,
实际计算公式是
。偏度可以表现变量分布的偏斜,负值为左
偏,正值为右偏。峰度表现变量分布与正态分布相比是重尾(分布函数在正负无穷处衰减缓
慢)还是轻尾(分布函数在正负无穷处衰减迅速)。标准误差在统计中是一个十分重要的概
念,它代表估计量作为随机变量其标准差的估计,这里的Std Mean是均值的标准差的估计,
实际计算公式是
![]() ,而均值的理论标准差为
,而均值的理论标准差为
![]() 。如果估计量服从正态分布,通常用估计量
加减两倍标准误差作为估计量的置信区间。
。如果估计量服从正态分布,通常用估计量
加减两倍标准误差作为估计量的置信区间。
分位数表中,Max是最大值,Q3是四分之三分位数,Med是中位数(反映数据中心位置),Q1 是四分之一分位数,Min是最小值,Range是最大值减最小值,Q3-Q1为四分位间距,可以反 映数据取值分散程度,Mode是众数,即出现最多的值。
在打开了身高分布的窗口之后主菜单中的Tables、Graphs、Curves菜单被开放。在Tables
菜单中可以选加一些统计表,比如Frequency Table是频数表,为每一观测值的频数、累计频
数、百分比,C.I. for Mean可以计算均值的各种置信度的置信区间,Location Tests用于检
验均值为某常数值(一般是0)的假设,可以用t检验、符号检验、符号秩检验,Gini's Mean Difference
是变量分布分散程度的一种稳健估计,计算公式为
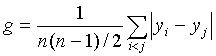 ,对正态分布其期望值为
,对正态分布其期望值为
![]() 。Trimmed Mean, (1/2)N计算去掉最大(1/2)N
个和最小(1/2)N个值后的平均值,(1/2)N可以指定为1,2,3或自定值,这是变量中心位置的
一种稳健估计,但估计量本身不再服从正态分布。Trimmed Mean, (1/2)Percent指定去掉最
大、最小的百分之多少再计算均值。Winsorized Mean是把最大的(1/2)N个替换成由大到小第(1/2)N
+1号值,把最小的(1/2)N个替换成由小到大第(1/2)N+1个值,然后计算的均值,它也是一
种稳健的均值估计。
。Trimmed Mean, (1/2)N计算去掉最大(1/2)N
个和最小(1/2)N个值后的平均值,(1/2)N可以指定为1,2,3或自定值,这是变量中心位置的
一种稳健估计,但估计量本身不再服从正态分布。Trimmed Mean, (1/2)Percent指定去掉最
大、最小的百分之多少再计算均值。Winsorized Mean是把最大的(1/2)N个替换成由大到小第(1/2)N
+1号值,把最小的(1/2)N个替换成由小到大第(1/2)N+1个值,然后计算的均值,它也是一
种稳健的均值估计。
在Graphs菜单中已选了直方图、盒形图,还可以作QQ图,即分位数-分位数图。
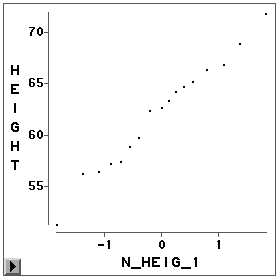
图 28为 身高的正态QQ图,其中画出了班上19个学生的19个点,每个点的纵坐标为变量值,而横坐标 为该值的累计百分比频数对应的标准正态分位数。比如,身高最低的一个为51.3,其累计百 分比频数(即51.3的经验分布函数值)为5.3%,即身高小于51.3的占5.3%,而标准正态分布 的0.053分位数为-1.84570,所以此点的横坐标即-1.84570。如果身高服从正态分布,QQ图的 散点应大致在一条直线附近变动。QQ图的各种不同形状能够反映出变量分布的偏斜情况和重 、轻尾情况。在QQ图中也可以选观测、刷亮等。画出QQ图后选主菜单中的“Curves | QQ Ref Line ”可以为图中散点画一条拟合直线。
图 28的身高的QQ图显示身高基本服从正态分布。如果我们画SASUSER.GPA中GPA分数的QQ 图(图 30):
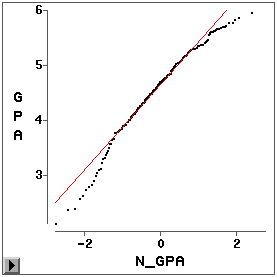
就可以看到GPA的分布呈现左偏的情况。这是因为,在QQ图的左下端,GPA散点 的走向比正态(图中直线)偏下,说明GPA分布的左尾比正态长;在QQ图的右上端,GPA散点 的走向比正态偏右下,说明GPA分布的右尾比正态短,即分布左偏。作为验证,可以看一看的 图 29直方图:
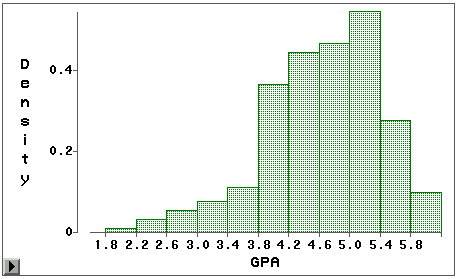
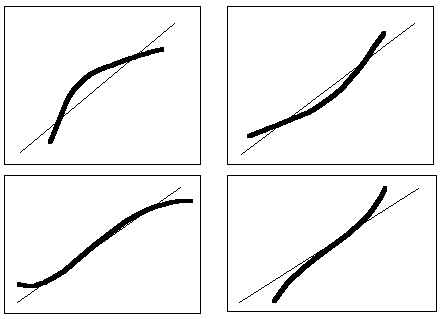
图 32给出了与正态相比左偏、右偏、轻尾、重尾的分布的QQ图的典型模式:
除了可以作正态分布QQ图外,还可以作对数正态、指数分布、威布尔分布的QQ图。对数正 态要指定参数Sigma,威布尔分布要指定形状参数C。
SAS/INSIGHT为研究一维变量分布除画直方图外还提供了两类 分布密度估计:参数估计和非参数估计。参数估计可以拟合正态、对数正态、指数、 威布尔分布密度。非参数估计使用核估计。
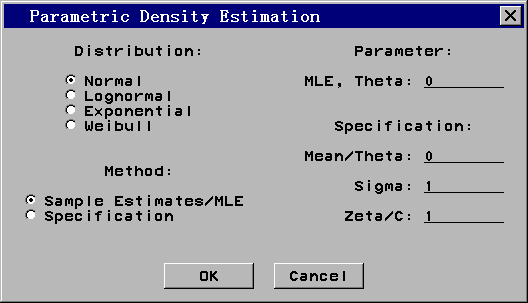
比如,为了估计身高的正态密度并把密度曲线叠加在直方图上,选“Curves | Parametric Density ”,弹出对话框图 31:
指定正态分布且方法为用样本估计分布密度参数。按OK后作出的图见 图 33:
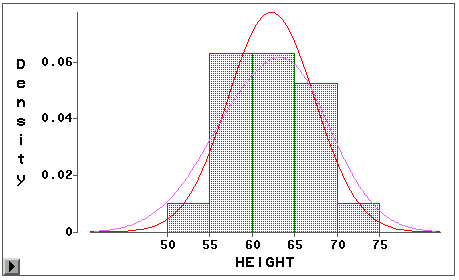
为了作身高密度的核估计图,选“Curves | Kernel Density”,弹出一个对话框,可以 选三种核函数:正态核、三角核、二次函数核,可以自动拟合最优的密度估计(方法为AMISE )或者自己指定平滑参数C。见图 33。
作了密度曲线图后在图形下面将出现显示密度估计主要参数的表格,见图 34:

单击其中 的曲线标志可以加亮显示图中的曲线。对参数密度估计,给出了估计的参数,比如正态的均 值、方差;对核估计,给出了核函数类型,及平滑参数值。有些参数旁边有一个滑块,可以 手工选择参数的值。比如拖动核估计中的平滑参数,此参数变小时估计的曲线变粗糙,变大 时曲线变光滑。
在“Curves”菜单中还提供了对样本经验分布函数的估计。选“Curves | Empirical CDF ”即绘制样本经验分布函数。选“Curves | CDF Confidence Band”并选一个置信限可以在 经验分布函数两边画分布函数的置信限,见图 35:
用经验分布函数估计分布函数相当于用直方图估计分布密度。分布函数也可以用参数分布 函数(如正态分布)来估计。选“Curves | Parametric CDF”并选分布类型可以画出估计的 分布函数。图 35中的光滑曲线即用正态分布估计身高的分布函数。
SAS/INSIGHT还可以进行分布检验,可以检验数据是否来自某一类分布(参数未知),或 检验数据是否来自某一特定分布(参数已知)。选“Analyze | Test for Distribution”, 并选择是检验正态、对数正态、指数、威布尔分布中哪一个,选正态后,得到图 36的结果。

它给出了分布类型、估计的分布均值、标准差,及Kolmogorov D统计量的值,并给出了检验H0 :样本来自正态分布的检验p值(Prob > D)为>.15,说明检验结果不显著,不能否定 正态假设。
如果要检验数据是否来自某一特定分布,选“Curves | Test for a Specific Distribution ”,并指定分布类型、分布参数,可以计算检验的Kolmogorov D统计量及相应p值。图 37是 检验身高是否标准正态分布的结果,可以看出p值为0.0001高度显著,应该否定数据来自标准 正态的假设。

说明:在SAS中,统计假设检验的结果一般用检验的p值给出。这与我们习惯的做法稍有不
同,以单正态总体的均值检验为例。假设我们要检验SASUSER.CLASS中学生的身高是否均值为
零(这当然不可能,我们为简单起见用这种假设),设总体服从
![]() ,要检验的零假设为
,要检验的零假设为
![]() ,水平0.05,统计量使用t统计量
,水平0.05,统计量使用t统计量
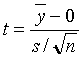 ,一般我们用的假设检验方法定否定域为W={|t|>C}
,其中C为n-1自由度t分布的双侧0.05分位数(Pr{|t|>C}=0.05),当用样本算出的t统计
量的值(如t=A)落入否定域时(|A|>C)否定零假设。在SAS中不需要这样指定否定域,
它可以先用样本计算出t统计量的值(A),如果这个A绝对值很大就否定零假设,t统计量绝
对值值是不是很大可以用这样一个p=Pr{|t|>|A|}来衡量,p是一个0到1之间的数值,显然|A|
越大,p越小。p<0.05与|A|>C是等价的。所以,如果p小于0.05,就否定零假设,称检
验结果是显著的。否则不否定零假设。对SASUSER.CLASS中HEIGHT变量,在其分布窗口中选菜
单“Tables | Location Tests”并从弹出的对换框中选中t检验,要检验的均值为0,得到的
结果见图 38。计算得到的t统计量值为A=52.9971,p值为Pr{|t|>52.9971}小于等于0.0001
。因p值小于0.05所以结果是否定零假设,结论是身高均值不为零。
,一般我们用的假设检验方法定否定域为W={|t|>C}
,其中C为n-1自由度t分布的双侧0.05分位数(Pr{|t|>C}=0.05),当用样本算出的t统计
量的值(如t=A)落入否定域时(|A|>C)否定零假设。在SAS中不需要这样指定否定域,
它可以先用样本计算出t统计量的值(A),如果这个A绝对值很大就否定零假设,t统计量绝
对值值是不是很大可以用这样一个p=Pr{|t|>|A|}来衡量,p是一个0到1之间的数值,显然|A|
越大,p越小。p<0.05与|A|>C是等价的。所以,如果p小于0.05,就否定零假设,称检
验结果是显著的。否则不否定零假设。对SASUSER.CLASS中HEIGHT变量,在其分布窗口中选菜
单“Tables | Location Tests”并从弹出的对换框中选中t检验,要检验的均值为0,得到的
结果见图 38。计算得到的t统计量值为A=52.9971,p值为Pr{|t|>52.9971}小于等于0.0001
。因p值小于0.05所以结果是否定零假设,结论是身高均值不为零。

SAS/INSIGHT还提供了曲线拟合、回归、logistic回归、Poisson回归、相关分析、主成分 分析等高等统计功能,我们后面再陆续介绍。