数组(array)可以看成是带多个下标的类型相同的元素的集合,常用的是数值型的 数组如矩阵,也可以有其它类型(如字符型、逻辑型、复型数组)。S可以很容易地生成和处 理数组,特别是矩阵(二维数组)。
数组有一个特征属性叫做维数向量(dim属性),维数向量是一个元素取正整数值的向量 ,其长度是数组的维数,比如维数向量有两个元素时数组为二维数组(矩阵)。维数向量的 每一个元素指定了该下标的上界,下标的下界总为1。
一组值只有定义了维数向量(dim属性)后才能被看作是数组。比如: > z <- 1:1500 > dim(z) <- c(3, 5, 100)
这时z已经成为了一个维数向量为c(3,5,100)的三维数组。也可以把向量定义为一维数组 ,例如:
> dim(z) <- 1500
数组元素的排列次序缺省情况下是采用FORTRAN的数组元素次序(按列次序),即第一下 标变化最快,最后下标变化最慢,对于矩阵(二维数组)则是按列存放。例如,假设数组a的 元素为1:24,维数向量为c(2,3,4),则各元素次序为a[1,1,1], a[2,1,1], a[1,2,1], a[2,2,1], a[1,3,1], ..., a[2,3,4]。
用函数array()或matrix()可以更直观地定义数组。array()函数的完全使用为array(x, dim=length(x), dimnames=NULL),其中x是第一自变量,应该是一个向量,表示数组的元素 值组成的向量。dim参数可省,省略时作为一维数组(但不同于向量)。dimnames属性可以省 略,不省略时是一个长度与维数相同的列表(list,见后面),列表的每个成员为一维的名 字。例如上面的z可以这样定义:
> z <- array(1:1500, dim=c(3,5,100)) 函数matrix()用来定义最常用的一种数组:二维数组,即矩阵。其完全格式为 matrix(data = NA, nrow = 1, ncol = 1, byrow = FALSE, dimnames = NULL)
其中第一自变量data为数组的数据向量(缺省值为缺失值NA),nrow为行数,ncol为列数 ,byrow表示数据填入矩阵时按行次序还是列次序,一定注意缺省情况下按列次序,这与我们 写矩阵的习惯是不同的。dimnames缺省是空值,否则是一个长度为2的列表,列表第一个成员 是长度与行数相等的字符型向量,表示每行的标签,列表第二个成员是长度与列数相同的字 符型向量,表示每列的标签。例如,定义一个3行4列,由1:12按行次序排列的矩阵,可以用 :
> b <- matrix(1:12, ncol=4, byrow=T)
> b
[,1] [,2] [,3] [,4]
[1,] 1 2 3 4
[2,] 5 6 7 8
[3,] 9 10 11 12
注意在有数据的情况下只需指定行数或列数之一。指定的数据个数允许少于所需的数据个 数,这时循环使用提供的数据。例如:
> b <- matrix(0, nrow=3, ncol=4)生成3行4列的元素都为0的矩阵。
要访问数组的某个元素,只要象上面那样写出数组名和方括号内用逗号分开的下标即 可,如a[2,1,2]。
更进一步我们还可以在每一个下标位置写一个下标向量,表示对这一维取出所有指定下标 的元素,如a[1, 2:3, 2:3]取出所有第一下标为1,第二下标为2或3,第三下标为2或3的元素 。注意因为第一维只有一个下标所以退化了,得到的是一个维数向量为c(2,2)的数组。
另外,如果略写某一维的下标,则表示该维全选。例如,a[1, , ]取出所有第一下标为1 的元素,得到一个形状为c(3,4)的数组。a[ , 2, ]取出所有第二下标为2的元素得到一个形 状为c(2,4)的数组。a[1,1, ]则只能得到一个长度为4的向量,不再是数组(dim(a[1,1, ]) 值为NULL)。a[ , , ]或a[]都表示整个数组。比如
a[] <- 0可以在不改变数组维数的条件下把元素都赋成0。
还有一种特殊下标是对于数组只用一个下标向量(是向量,不是数组),比如a[3:4] ,这时忽略数组的维数信息,把下标表达式看作是对数组的数据向量取子集。
在S中甚至可以把数组中的任意位置的元素作为一组访问,其方法是用一个矩阵作为 数组的下标,矩阵的每一行是一个元素的下标,数组有几维下标矩阵的每一行就有几列。例 如,我们要把上面的形状为c(2,3,4)的数组a的第[1,1,1], [2,2,3], [1,3,4], [2,1,4]号共 四个元素作为一个整体访问,先定义一个包含这些下标作为行的二维数组:
> b <- matrix(c(1,1,1, 2,2,3, 1,3,4, 2,1,4), ncol=3, byrow=T)
> b
[,1] [,2] [,3]
[1,] 1 1 1
[2,] 2 2 3
[3,] 1 3 4
[4,] 2 1 4
> a[b]
[1] 1 16 23 20
注意取出的是一个向量。我们还可以对这几个元素赋值,如:
> a[b] <- c(101, 102, 103, 104) > a 或 > a[b] <- 0 > a
数组可以进行四则运算(+,-, *, /,^),解释为数组对应元素的四则运算,参加 运算的数组一般应该是相同形状的(dim属性完全相同)。例如,假设A, B, C是三个形状相 同的数组,则
> D <- C + 2*A/B
计算得到的结果是A的每一个元素除以B的对应元素加上C的对应元素乘以2得到相同形状的 数组。四则运算遵循通常的优先级规则。
形状不一致的向量和数组也可以进行四则运算,一般的规则是数组的数据向量对应元 素进行运算,把短的循环使用来与长的匹配,并尽可能保留共同的数组属性。例如:
> x1 <- c(100, 200)
> x2 <- 1:6
> x1+x2
[1] 101 202 103 204 105 206
> x3 <- matrix(1:6, nrow=3)
> x3
[,1] [,2]
[1,] 1 4
[2,] 2 5
[3,] 3 6
> x1+x3
[,1] [,2]
[1,] 101 204
[2,] 202 105
[3,] 103 206
除非你清楚地知道规则应避免使用这样的办法(标量与数组或向量的四则运算除外)。
矩阵是二维数组,但因为其应用广泛所以对它定义了一些特殊的运算和操作。
函数t(A)返回矩阵A的转置。nrow(A)为矩阵A的行数,ncol(A)为矩阵A的列数。
矩阵之间进行普通的加减乘除四则运算仍遵从一般的数组四则运算规则,即数组的对应元 素之间进行运算,所以注意A*B不是矩阵乘法而是矩阵对应元素相乘。
要进行矩阵乘法,使用运算符%*%,A%*%B表示矩阵A乘以矩阵B(当然要求A的列数等于B的 行数)。例如:
> A <- matrix(1:12, nrow=4, ncol=3, byrow=T)
> B <- matrix(c(1,0), nrow=3, ncol=2, byrow=T)
> A
[,1] [,2] [,3]
[1,] 1 2 3
[2,] 4 5 6
[3,] 7 8 9
[4,] 10 11 12
> B
[,1] [,2]
[1,] 1 0
[2,] 1 0
[3,] 1 0
> A %*% B
[,1] [,2]
[1,] 6 0
[2,] 15 0
[3,] 24 0
[4,] 33 0
>
另外,向量用在矩阵乘法中可以作为行向量看待也可以作为列向量看待,这要看哪一种观
点能够进行矩阵乘法运算。例如,设x是一个长度为n的向量,A是一个
![]() 矩阵,则“x %*% A %*% x”表示二次型
矩阵,则“x %*% A %*% x”表示二次型
![]() 。但是,有时向量在矩阵乘法中的地位并不
清楚,比如“x %*% x”就既可能表示内积
。但是,有时向量在矩阵乘法中的地位并不
清楚,比如“x %*% x”就既可能表示内积
![]() 也可能表示
也可能表示
![]() 阵
阵
![]() 。因为前者较常用,所以S选择表示前者,
但内积最好还是用crossprod(x)来计算。要表示
。因为前者较常用,所以S选择表示前者,
但内积最好还是用crossprod(x)来计算。要表示
![]() ,可以用“cbind(x) %*% x”或“x %*% rbind(x)
”。
,可以用“cbind(x) %*% x”或“x %*% rbind(x)
”。
函数crossprod(X, Y)表示一般的交叉乘积(内积)
![]() ,即X的每一列与Y的每一列的内积组成的矩
阵。如果X和Y都是向量则是一般的内积。只写一个参数X的crossprod(X)计算X自身的内积
,即X的每一列与Y的每一列的内积组成的矩
阵。如果X和Y都是向量则是一般的内积。只写一个参数X的crossprod(X)计算X自身的内积
![]() 。
。
其它矩阵运算还有solve(A,b)解线性方程组
![]() ,solve(A)求方阵A的逆矩阵,svd()计算奇
异值分解,qr()计算QR分解,eigen()计算特征向量和特征值。详见随机帮助,例如:
,solve(A)求方阵A的逆矩阵,svd()计算奇
异值分解,qr()计算QR分解,eigen()计算特征向量和特征值。详见随机帮助,例如:
> ?qr
函数diag()的作用依赖于其自变量。diag(vector)返回以自变量(向量)为主对角元素的 对角矩阵。diag(matrix)返回由矩阵的主对角元素组成的向量。diag(k)(k为标量)返回k阶 单位阵。
函数cbind()把其自变量横向拼成一个大矩阵,rbind()把其自变量纵向拼成一个大矩 阵。cbind()的自变量是矩阵或者看作列向量的向量,自变量的高度应该相等(对于向量,高 度即长度,对于矩阵,高度即行数)。rbind的自变量是矩阵或看作行向量的向量,自变量的 宽度应该相等(对于向量,宽度即长度,对于矩阵,宽度即列数)。如果参与合并的自变量 比其它自变量短则循环补足后合并。例如:
> x1 <- rbind(c(1,2), c(3,4))
> x1
[,1] [,2]
[1,] 1 2
[2,] 3 4
> x2 <- 10+x1
> x3 <- cbind(x1, x2)
> x3
[,1] [,2] [,3] [,4]
[1,] 1 2 11 12
[2,] 3 4 13 14
> x4 <- rbind(x1, x2)
> x4
[,1] [,2]
[1,] 1 2
[2,] 3 4
[3,] 11 12
[4,] 13 14
> cbind(1, x1)
[,1] [,2] [,3]
[1,] 1 1 2
[2,] 1 3 4
因为cbind()和rbind()的结果总是矩阵类型(有dim属性且为二维),所以可以用它
们把向量表示为
![]() 矩阵(用cbind(x))或
矩阵(用cbind(x))或
![]() 矩阵(用rbind(x))。
矩阵(用rbind(x))。
设a是一个数组,要把它转化为向量(去掉dim和dimnames属性),只要用函数as.vector(a) 返回值就可以了(注意函数只能通过函数值返回结果而不允许修改它的自变量,比如t(X)返 回X的转置矩阵而X本身并未改变)。另一种由数组得到其数据向量的简单办法是使用函数c() ,例如c(a)的结果是a的数据向量。这样的另一个好处是c()允许多个自变量,它可以把多个 自变量都看成数据向量连接起来。例如,设A和B是两个矩阵,则c(A,B)表示把A按列次序拉直 为向量并与把B按列次序拉直为向量的结果连接起来。一定注意拉直时是按列次序拉直的。
数组可以有一个属性dimnames保存各维的各个下标的名字,缺省时为NULL(即无此属 性)。我们以矩阵为例,它有两个维:行维和列维。比如,设x为2行3列矩阵,它的行维可以 定义一个长度为2的字符向量作为每行的名字,它的列维可以定义一个长度为3的向量作为每 列的名字,属性dimnames是一个列表,列表的每个成员是一个维名字的字符向量或NULL。例 如:
> x <- matrix(1:6, ncol=2,
+ dimnames=list(c("one", "two", "three"), c("First", "Second")),
+ byrow=T)
> x
First Second
one 1 2
two 3 4
three 5 6
我们也可以先定义矩阵x然后再为dimnames(x)赋值。
对于矩阵,我们还可以使用属性rownames和colnames来访问行名和列名。如:
> x <- matrix(1:6, ncol=2,byrow=T)
> colnames(x) <- c("First", "Second")
> rownames(x) <- c("one", "two", "three")
在定义了数组的维名后我们对这一维的下标就可以用它的名字来访问,例如:
> x[c("one","three"),]
First Second
one 1 2
three 5 6
两个数组a和b的外积是由a的每一个元素与b的每一个元素搭配在一起相乘得到一个新 元素,这样得到一个维数向量等于a的维数向量与b的维数向量连起来的数组,即若d为a和b的 外积,则dim(d)=c(dim(a), dim(b))。
a和b的外积记作 a %o% b。如> d <- a %o% b也可以写成一个函数调用的形式:
> d <- outer(a, b, '*')
注意outer(a, b, f)是一个一般性的外积函数,它可以把a的任一个元素与b的任意一个元 素搭配起来作为f的自变量计算得到新的元素值,外积是两个元素相乘的情况。函数当然也可 以是加、减、除,或其它一般函数。当函数为乘积时可以省略不写。
例如,我们希望计算函数
![]() 在一个x和y的网格上的值用来绘制三维曲
面图,可以用如下方法生成网格及函数值:
在一个x和y的网格上的值用来绘制三维曲
面图,可以用如下方法生成网格及函数值:
> x <- seq(-2, 2, length=20) > y <- seq(-pi, pi, length=20) > f <- function(x, y) cos(y)/(1+x^2) > z <- outer(x, y, f)用这个一般函数可以很容易地把两个数组的所有元素都两两组合一遍进行指定的运算。
下面考虑一个有意思的例子。我们考虑简单的2×2矩阵
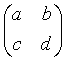 ,其元素均在0,1,...,9中取值。假设四个
元素
a,
b,
c,
d都是相互独立的服从离散均匀分布的随机变量,我们设法求矩阵行列式
ad-bc的分布。首先,随机变量
ad和
bc同分布,它的取值由以下外积矩阵给出,每一个取值的概率均为1/100:
,其元素均在0,1,...,9中取值。假设四个
元素
a,
b,
c,
d都是相互独立的服从离散均匀分布的随机变量,我们设法求矩阵行列式
ad-bc的分布。首先,随机变量
ad和
bc同分布,它的取值由以下外积矩阵给出,每一个取值的概率均为1/100:
> d <- outer(0:9, 0:9)
这个语句产生一个
![]() 的外积矩阵。为了计算
ad的100个值(有重复)与
bc的100个值相减得到的10000个结果,可以使用如下外积函数:
的外积矩阵。为了计算
ad的100个值(有重复)与
bc的100个值相减得到的10000个结果,可以使用如下外积函数:
> d2 <- outer(d, d, "-")
这样得到一个维数向量为c(2,2,2,2)的四维数组,每一个元素为行列式的一个可能取值, 概率为万分之一。因为这些取值中有很多重复,我们可以用一个table()函数来计算每一个值 的出现次数(频数):
> fr <- table(d2)
得到的结果是一个带有元素名的向量fr,fr的元素名为d2的一个取值,fr的元素值为d2该 取值出现的频数,比如fr[1]的元素名为-81,值为19,表示值-81在数组d2中出现了19次。 通过计算length(fr)可以知道共有163个不同值。还可以把这些值绘制一个频数分布图(除以10000 则为实际概率):
> plot(as.numeric(names(fr)), fr, type="h", + xlab="行列式", ylab="频数")
其中as.numeric()把向量fr中的元素名又转换成了数值型,用来作为作图的横轴坐标,fr 中的元素值即频数作为纵轴,type="h"表示是画垂线型图。
> a <- array(1:24, dim=c(2,3,4)) > b <- aperm(a, c(2, 3, 1))
结果a的第2维变成了b的第1维,a的第3维变成了b的第2维,a的第1维变成了b的第3维。这 时有a[i1,i2,i3]≡b[i2,i3,i1]。注意c(i1,i2,i3)[2,3,1]=c(i2,i3,i1)。一般地,若b <- aperm(a, p),i是数组a的一个下标向量,则a[rbind(i)]≡b[rbind(i[p])],即a的一个元 素下标经过p变换后成为b的对应元素的下标。
对于矩阵a,aperm(a, c(2,1))恰好是矩阵转置。对于矩阵转置可以简单地用t(a)表示。
对于向量,我们有sum、mean等函数对其进行计算。对于数组,如果我们想对其中一 维(或若干维)进行某种计算,可以用apply函数。其一般形式为:
apply(X, MARGIN, FUN, ...)
其中X为一个数组,MARGIN是固定哪些维不变,FUN是用来计算的函数。例如,设a是
![]() 矩阵,则apply(a, 1, sum)的意义是对a的
各行求和(保留第一维即第一个下标不变),结果是一个长度为3的向量(与第一维长度相同
),而apply(a, 2, sum)意义是对a的各列求和,结果是一个长度为4的向量(与第二维长度
相同)。
矩阵,则apply(a, 1, sum)的意义是对a的
各行求和(保留第一维即第一个下标不变),结果是一个长度为3的向量(与第一维长度相同
),而apply(a, 2, sum)意义是对a的各列求和,结果是一个长度为4的向量(与第二维长度
相同)。
如果函数FUN的结果是一个标量,MARGIN只有一个元素,则apply的结果是一个向量, 其长度等于MARGIN指定维的长度,相当于固定MARGIN指定的那一维的每一个值而把其它维取 出作为子数组或向量送入FUN中进行运算。如果MARGIN指定了多个维,则结果是一个维数向量 等于dim(X)[MARGIN]的数组。如果函数FUN的结果是一个长度为N的向量,则结果是一个维数 向量等于c(N, dim(X)[MARGIN])的数组,注意这时不论是对哪一维计算,结果都放在了第一 维。所以,比如我们要把4×3矩阵a的3列分别排序,只要用apply(a, 2, sort),这样对每一 列排序得到一个长度为4的向量,用第一维来引用,结果的维向量为c(N, dim(a)[2])=c(4,3) ,保留了列维,恰好得到所需结果,运行如下例:
> a <- cbind(c(4,9,1), c(3,7,2))
> a
[,1] [,2]
[1,] 4 3
[2,] 9 7
[3,] 1 2
> apply(a, 2, sort)
[,1] [,2]
[1,] 1 2
[2,] 4 3
[3,] 9 7
>
但是,如果要对行排序,则apply(a, 1, sort)把a的每一行3个元素排序后的结果用第一 维来引用,结果的维向量为c(N, dim(a)[1])=c(3, 4),把原来的列变成了行,所以t(apply(a,1,sort)) 才是对a的每一行排序的结果。如:
> apply(a, 1, sort)
[,1] [,2] [,3]
[1,] 3 7 1
[2,] 4 9 2
> t(apply(a,1,sort))
[,1] [,2]
[1,] 3 4
[2,] 7 9
[3,] 1 2
上面我们只用了矩阵(二维数组)作为例子讲解apply的用法。实际上,apply可以用 于任意维数的数组,函数FUN也可以是任意可以接收一个向量或数组作为第一自变量的函数。 比如,设x是一个维数向量为c(2,3,4,5)的数组,则apply(x, c(1,3), sum)可以产生一个2行4 列的矩阵,其每一元素是x中固定第1维和第3维下标取出子数组求和的结果。