Gauss系统是Aptech Systems公司出品的一个矩阵语言软件包, 它可以十分方便地编制矩阵计算程序, 并内建了许多矩阵运算、概率统计函数, 还可以绘制印刷质量的图形。 它可以在命令行交互计算, 也可以编程计算, 编程时具有通常的分支、循环、模块化子程序等功能, 并以矩阵为基本运算单位。 利用附加的模块可以进行经济财务分析、统计分析等等。 我们主要用它来编制统计计算、模拟程序。 它进行矩阵运算时速度很快, 甚至比编译的C代码还要快, 这是因为它采用了优化的矩阵计算内核。 Gauss系统有微机版本, 也可以运行于工作站等高档机型。 这里以DOS版Gauss v2.2为例说明。
在安装好Gauss系统后, 一般用一个批命令进入Gauss系统, 比如说是G0.BAT。 进入系统后, 出现一个命令行的界面, 命令提示为“》”形状。 在命令提示下可以输入Gauss语句。 用Alt+H可以启动帮助系统, 在帮助系统内按H键后输入问号然后回车可以得到一个帮助菜单。
为了退出Gauss系统, 可以在命令行发布SYSTEM命令, 或者按ESC键并回答Y。
Gauss的基本计算单位是矩阵。 定义标量、向量、矩阵用等号赋值即可。 例如,
》a = 15.2;
》b1 = {1 2 3};
》b2 = {1, 2, 3};
》c = {1 2 3, 4 5 6, 7 8 9};
》name="My first Gauss program"
分别定义了标量a、行向量b1、列向量b2、矩阵c、字符串标量name。 矩阵定义中一行的元素间用空格分隔, 各列用逗号分隔。 字符串两边用双撇号包围, 不能用单撇号。 Gauss中除了字符串常量外不区分大小写, 所以变量名既可以用大写, 也可以用小写。 语句以分号结束, 但在命令行界面可以省略分号。
要显示定义的变量的值, 在命令行界面下只要键入变量名就可以显示其值, 例如
》 c
1.0000000 2.0000000 3.0000000
4.0000000 5.0000000 6.0000000
7.0000000 8.0000000 9.0000000
显示变量值的正规方法是使用PRINT语句, 如“print c;”。 PRINT语句可以输出几项, 各项之间用空格分开, 所以PRINT语句中如果有表达式, 表达式中一定不能有空格。 例如:
》 print "A = " a "b1 = " b1
A = 15.200000 b1 = 1.0000000 2.0000000 3.0000000
有一些函数可以生成常见的向量和矩阵。 SEQA(start, step, length)可以产生从start开始, 按step递增, 长度为length的等差数列列向量, 如seqa(1,2,4)产生元素为1、3、5、7的列向量。 SEQM(start, rate, length)可以产生从start开始, 每次乘以rate的长度为length的等比数列列向量。 ZEROS(n,m)产生n行m列的元素全为零的矩阵。 ONES(n,m)产生n行m列的元素全为1的矩阵。 RNDU(n,m)产生n行m列的元素服从(0,1)均匀分布的伪随机数矩阵。 RNDN(n,m)产生n行m列的元素服从标准正态分布的伪随机数矩阵。 EYE(n)产生n阶单位阵。
为了从键盘输入一个矩阵, 使用函数CON(n,m), 其中n和m分别是要输入的行数和列数。 输入时用空格、回车、逗号分隔输入的数值。 例如:
》c2 = con(2,3)
? 1 2 3 4
? 5 6
》c2
1.0000000 2.0000000 3.0000000
4.0000000 5.0000000 6.0000000
要输入字符串, 一般用如“s= CONS;PRINT;”的方法, 其中s是用来存放输入的字符串的变量。
矩阵可以直接进行通常的矩阵运算。 例如,
》 c1={1 2 3, 4 5 6};
》 c2={3 2 1, 7 6 5};
》 c3=c1+c2;
》 c3;
4.0000000 4.0000000 4.0000000
11.000000 11.000000 11.000000
c4={1 2, 3 4};
c5=c4*c3;
c5;
26.000000 26.000000 26.000000
56.000000 56.000000 56.000000
矩阵X的转置可以用X'表示。 两个矩阵X和Y横向并接用X~Y表示。 矩阵X和Y纵向并接用X|Y表示。 为了解方程A X = B, 只要写X = B/A即可, 当A为满秩方阵时即联立线性方程组求解, 当A的行数大于列数时求的是最小二乘解。 矩阵与标量可以进行加减乘除运算。
除了可以使用命令行界面直接输入并运行Gauss语句, 我们还可以编辑一个程序文件并运行这个程序文件。 可以预先编辑好一个程序文件, 比如TEST.GSP, 里面有如下程序行:
x={1 2 3};
y={4,5,6};
print x y;
把这个文件放在Gauss的当前目录下, 在Gauss命令行用
》RUN TEST.GSP
命令就可以运行这个程序文件。 事实上, Gauss提供了一个内建的程序编辑器, 比如, 在命令行用
》EDIT TEST.GSP
就可以打开TEST.GSP到Gauss的内部编辑器中, 如果原来没有这个文件将生成一个新文件。 编辑完毕按Alt+X出现一个选单, 选W可以保存文件但不执行, 选R可以保存并运行程序, 并且运行时带有调试信息, 可以显示出错行号。 在运行了一个程序后按Ctrl+F1键就可以之间调入刚刚执行的程序进行修改。
Gauss系统提供了一个完整的以矩阵为基本运算单位的程序设计语言。 Gauss是一种解释性语言, 但因为它的每一个操作都是对矩阵进行的, 所以运行速度很快。 自己写程序时要尽量利用矩阵运算而应避免使用循环对单个元素运算。
Gauss有矩阵和字符串两种数据类型。 变量类型不需要预先说明。 数据类型、元素个数、矩阵形状可以在运行时改变。 可以用DECLARE语句声明数据类型。 矩阵元素允许为字符串, 字符矩阵的元素最多存储8个字符。
Gauss的矩阵是按行存储的。 矩阵元素都以IEEE 8字节双精度浮点数格式存在内存中, 称为“长实数”, 有效位数有15-16位, 绝对值范围在4.19E-307到1.67E308。
Gauss计算由表达式完成。 表达式是用运算符连接起来的常数、矩阵、字符串、函数或过程调用。 Gauss程序由语句构成, 语句以分号结尾。
上一节我们已经看到了矩阵赋值的一些办法。 矩阵赋值还有一些灵活的方法, 如:
》 let x[2,2] = 1 2 3 4;
结果得到方阵x, 第一行为1 2, 第二行为3 4。
》 let x[2,3] = 1;
结果得到一个元素全为1的2行3列方阵。
》 let x[2,3];
结果得到一个元素全为0的2行3列方阵。 LET语句用来对矩阵赋值, 但右边只能是一些常数而不能是计算表达式。 为了计算, 省略LET并用~和|连接行列, 例如:
》 x = (1/3) ~ (1+1/4) | 3 ~ 4;
用RESHAPE函数可以改变一个矩阵的形状。 例如,
》 x = reshape(seqa(1,1,12), 3, 4);
把原始的列向量改成了3行4列矩阵:
1.0000000 2.0000000 3.0000000 4.0000000
5.0000000 6.0000000 7.0000000 8.0000000
9.0000000 10.000000 11.000000 12.000000
可以很方便地得到矩阵的子阵。 例如, x[2,3]为第2行第三列元素, x[1, .]为x的第一行, x[., 2]为x的第二列, x[1 3,2 4]为x的第1、3行和第2、4列组成的子阵(注意方括号中不允许有多余的空格):
》 x[1 3,2 4];
2.0000000 4.0000000
10.000000 12.000000
下标可以用冒号表示一个范围, 比如
》 x[1 3,2:4];
2.0000000 3.0000000 4.0000000
10.000000 11.000000 12.000000
Gauss提供了丰富的运算符来进行矩阵运算和字符串操作。
矩阵运算除了一般线性代数中的运算外还有一些针对元素的运算,
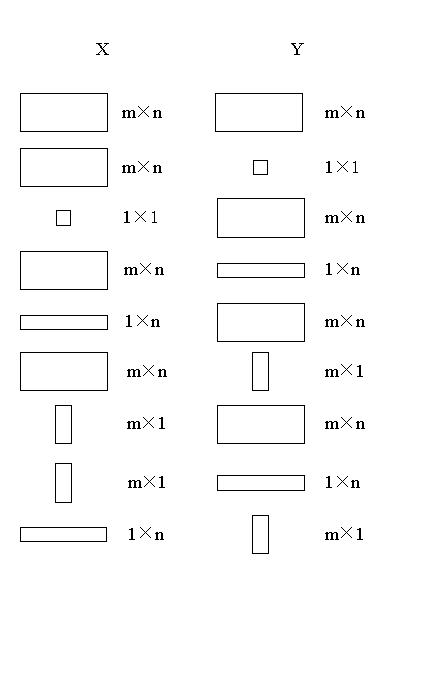
为此定义两个矩阵X和Y是元素匹配(ExE
conformable)的,
如果X和Y为图
1情况之一。
元素运算为对应行、列元素的运算, 如果行、列中只有一项是匹配的则只对这一项匹配运算, 例如:
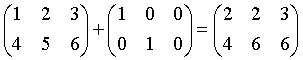
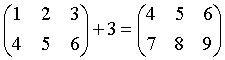
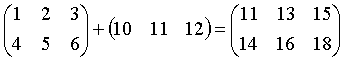
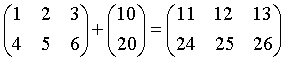
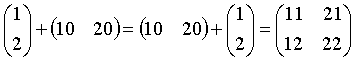
上面的各运算交换后仍是匹配的。
Gauss的矩阵运算包括:
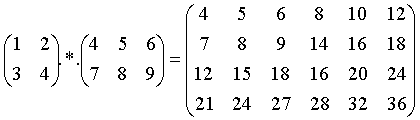
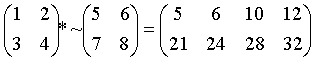
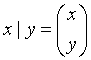
Gauss提供的比较运算符包括:
如果上面的比较算符中没有点则比较结果为标量结果, 用于比较两个标量, 如果比较两个矩阵, 则元素间所有比较结果都为真时才为真, 否则为假。
Gauss提供的逻辑运算符有:
上面的逻辑运算为标量运算, x和y应为标量。 逻辑运算也可以在两个矩阵的元素之间进行, 只要在运算符前加点, 如 .AND, .OR。
其它运算符还有:
clear x, y, z;
y = x[3,5]
y=momentd(x,d);
y=x[.,5]; /* 表示x的第5列所有行的元素组成的列向量 */
y=x[1 3 5, 3 7];
y=x[1:5,.]; /* x的第一到第五行 */
dset = "olsdat";
vnames = {age,pay,sex};
create f1 = ^dset with ^vname, 0, 2;
结果等效于在create语句中直接写入字符串变量的值。
由于采用了矩阵作为基本运算单元, 所以Gauss程序经常用顺序结构就可以完成任务。 比如, 要解方程组
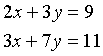
只要用以下四个语句:
A = {2 3,3 7};
b = {9,11};
x = b/A;
print x;
结果得到:
6.0000000
-1.0000000
但是, 对于比较复杂的问题, 我们不可避免地要使用分支、循环等运算结构。 Gauss提供了这些程序控制结构, 但是我们再次提醒读者, Gauss是一个基于矩阵的语言, 我们应该尽可能基于矩阵运算去实现算法。
Gauss分支结构使用IF-ELSEIF-ELSE-ENDIF结构, 格式为:
IF 标量表达式;
………(语句组)
ELSEIF 标量表达式;
………(语句组)
ELSE;
………(语句组)
ENDIF;
其中各判断条件应为标量表达式, 不允许是矩阵。 标量值为非零时表示真值, 为零时表示假值。 “语句组”可以是一个或多个语句, 每个语句以分号结尾。 注意Gauss的IF结构不使用THEN关键字。
Gauss的循环结构为DO WHILE和DO UNTIL结构, 没有计次循环结构。 格式为:
DO WHILE 标量表达式;
………(语句组)
ENDO;
和
DO UNTIL 标量表达式;
………(语句组)
ENDO;
要注意其结束语句是ENDO而不是ENDDO。 为了从循环中退出可以用BREAK语句。 在循环中执行CONTINUE语句可以忽略循环体内后面的语句而返回到判断条件处继续执行。
Gauss也提供了GOTO语句, 格式为:“GOTO 标号;”, 其中标号为一个普通的Gauss名字, 在定义时尾随一个冒号, 引用时不写冒号, 例如:
goto errout;
………
errout:
………
Gauss可以在程序中加注释, 用/*和*/包围, 或用@和@包围起来。
Gauss的符号名(变量名、过程名、标号名等)要求由字母、数字、下划线组成, 第一个字符只能是字母或下划线, 最多8个字符。
为了在程序运行时提供调试信息, 可以在程序文件开头加上一个“#lineson;”语句。 这样出错时可以显示出错的行号。
作为一个程序设计语言Gauss也提供了模块化的过程, 可以实现模块化程序设计。 过程中可以使用局部变量, 也可以引用外部的全局变量, 并可以递归调用。 Gauss使用用户自己编写的过程与使用内部过程一样方便。
Gauss提供了一种单行函数定义可以很方便地把一个公式定义为一个函数, 例如:
fn area(r) = 2*pi*r*r;
定义了面积函数, 调用时只要用如“a=area(4);”。
过程可以使用复杂的程序逻辑, 可以返回零到多个值, 定义格式如下:
PROC 〖返回值个数=〗过程名〖(参数1, 参数2, …, 参数N)〗;
LOCAL 语句;
………(语句组)
RETP〖(表达式1, …, 表达式N)〗;
ENDP;
其中〖〗内的内容表示是可选的。 当返回值个数为1个时可以省略“返回值个数=”的说明。 当没有参数时可以省略括号。 没有返回值时要说明“(0)= ”即返回值个数为0, 可以省略RETP语句。 过程的调用格式为:
{返回值1, …, 返回值N}= 过程名〖(参数1, 参数2, …, 参数N)〗;
或
CALL 过程名〖(参数1, 参数2, …, 参数N)〗;
使用CALL语句时无返回值或者忽略返回值。
例如, 下面的过程计算回归分析:
/* regress
** Input:
** x --- design matrix
** y --- dependent variable
** Output:
** b --- regression coefficients
** sd --- standard deviation
** t --- t variable for every coefficient
*/
PROC (3)=regress(x, y);
LOCAL xxi, b, ymxb, sse, sd, t;
xxi = invpd(x'x);
b = xxi*(x'y);
ymxb = y - x*b;
sse = ymxb'*ymxb/(rows(x)-cols(x));
sd = sqrt(diag(sse*xxi));
t = b ./ sd;
retp(b, sd, t);
ENDP;
调用可用如
{b, sd, t} = regress(x, y);
或
call regress(x, y);
使用CALL调用时忽略返回值。
在过程内使用的变量是局部变量, 必须用LOCALS语句说明, 对变量不必说明类型, 对过程名应说明为PROC, 单行函数说明为FN, 例如:
locals x, y, f:proc, g:fn;
其中x,y是变量, f是过程, g是单行函数。
过程内可以使用全局变量, 有两种全局变量, 一种是所有在主程序中使用的变量(即在所有过程外部定义的变量), 例如:
g_x = 1;
call sub1;
proc (0)=sub1;
print "in sub1";
print "global g_x = " g_x;
endp;
结果为:
in sub1
global g_x = 1.0000000
我们注意到, 这种用法很方便, 但是也不利于程序调试(数据隐藏不够)。 使用Gauss变较大的程序可能出现的一个问题就是在过程中无意中使用了主程序中的变量名而造成不易发现的错误。
另一种全局变量在过程中使用DECLARE语句来声明, 声明的变量可以在其它过程中使用。 例如:
call sub1;
proc (0)=sub1;
declare g_x != 0;
g_x = 1;
call sub2;
endp;
proc (0)=sub2;
print "in sub2";
print "global g_x = " g_x;
endp;
DECLARE语句中的!=表示赋初值, 并且不论变量是否已初始化。 如果改成?=则表示原来未初始化则按给定值初始化, 如果已经初始化则不动。 如果改成=则表示如果未初始化则初始化, 如果已初始化则为重复定义错误。 不写初值表示=0初始化。
过程也可以作为参数传递给另一个过程, 例如我们有一个二分法解方程的过程binsolv:
proc binsolv(&f, a, b, ascend);
/*
** f(x)是一个单调函数,
** f(a)和f(b)符号相反,
** ascend=1表示增函数,
** =0表示减函数
** 解c应该在a和b之间
** 返回解.
*/
local f:proc, a, b, ascend;
local c, tol;
tol=1E-6;
if(ascend);
do until (b-a<tol);
c = (a+b)/2;
if(f(c)>0); /* x应该在c的左边 */
b=c;
else;
a=c;
endif;
endo;
else;
do until (b-a<tol);
c = (a+b)/2;
if(f(c)>0); /* x应该在c的右边 */
a=c;
else;
b=c;
endif;
endo;
endif;
retp(c);
endp;
例如, 我们要求函数f(x)= x^2在0到5之间的解, 可以用如下程序(写在上面的程序上面, 或把上面的过程单独存为文件BINSOLV.G放在GAUSS的搜索路径中。
x = binsolv(&xsq, 0, 5, 1);
print x;
end;
proc xsq(x);
retp(x^2 - 1);
endp;
但是, 实际中我们要求解的函数经常是不止一个参数的, 比如我们想利用t分布的分布函数来求t分布的分位数, 但t分布函数有第二个参数即自由度。 这样的问题需要定义一个辅助函数, 这个辅助函数只有一个自变量, 自由度通过全局变量来传送。 例如, 下面的程序演示了如何调用binsolv过程编写一个求t分布分位数的过程以及示例:
q = con(1,1);
x = tinv(q, 10);
print "tinv" q x;
end;
proc tinv(q, n);
/* tinv计算n个自由度的t分布的q分位数
*/
declare tinv_n != 0;
declare tinv_q1 != 0;
tinv_n = n;
tinv_q1 = 1-q;
retp(binsolv(&futil, -10, 10, 0));
endp;
proc futil(x);
retp(cdftc(x, tinv_n)-tinv_q1);
endp;
其中定义了辅助性的函数futil, 它依赖于函数tinv中定义的两个全局变量tinv_n和tinv_q1。 因为Gauss中没有给t分布函数而只是给了t分布的尾概率函数(即1减分布函数), 所以我们在futil中给的方程是解尾概率等于1-q。
甚至可以把过程指针组合成一个向量, 例如:
procvev = &f1 ~ &f2 ~ &f3 ~f4;
proc g(x, i);
local f;
f = procvec[i];
local f:proc;
retp(f(x));
endp;
Gauss提供了很方便的模块化功能, 其中一种是可以把一个过程放在一个单独的与过程同名并用.G作为扩展名的文件中, 则程序执行时如果找不到某个过程自动查找与过程同名的.G文件。 可以定义一个GAUSSPATH环境变量来设置从哪些地方寻找过程。 还可以把多个过程组合为一个“库文件”, 一般为.ARC文件, 并在一个.LIB文件中加以说明, 可以参考Gauss系统附带的gauss.lib等文件。
Gauss可以把程序编译成字节码形式以加速运行。 在命令行状态用
COMPILE 文件名;
命令可以把一个文件中的程序编译为字节码, 结果存在“文件名.GCC”(Gauss v2.1)或“文件名.G32”(Gauss v2.2)中。
Gauss可以很容易地读写文本文件, 也可以使用专用二进制格式的Gauss数据集。 这里我们只讲文本文件的读写。
可以用LOAD语句读入一个用空格或逗号分隔数据项的文本文件, 格式为:
LOAD 向量名=文件名;
或
LOAD 矩阵名[行数, 列数] = 文件名;
第一种格式读入所有数据到一个向量, 适用于未知数据个数的情况, 第二种格式读入给定的行、列数的数据项到一个矩阵。 例如:
file1 = "c:\\gauss\\dat1.txt";
load x[]=^file1;
n = rows(x)/5;
if int(n) eq n;
x = reshape(x, n, 5);
elses;
errorlog "Read Error";
end;
endif;
上程序从一个文件中读入一个5列的矩阵, 行数未知。 注意文件名是直接写的, 比如读入当前目录下的dat2.txt只要用:
load x[]=dat2.txt;
所以如果文件名存在变量中就要使用宏替换。 文件名字符串中的反斜杠要用两个。 ERRORLOG语句在错误记录文件中写入一个字符串。 END语句结束程序运行。
如果已知行数, 则可以用如:
load x[100,5]=dat2.txt;
在一个文件中可以放置多个项, 比如, 我们在文件“dat3.txt”中放置了样本个数n、n行3列个样本观测、检验水平alpha, 就可以用如下程序分别读入:
load inf[]=dat3.txt;
n=inf[1];
x = reshape(inf[2:3*n+1], n, 3);
alpha=inf[3*n+2];
print n x alpha;
要写一个文本文件也很简单, 只要用
OUTPUT FILE=文件名 RESET;
语句就可以打开一个文件并从头开始写, 这时用PRINT语句输出的结果在显示到屏幕的同时被输出到指定的文件。 如果上面的RESET改为ON, 则输出是附加在指定文件末尾。 为了关闭屏幕输出, 用
SCREEN OFF;
语句。 再打开用“SCREEN ON”语句。 也可以暂时关闭文件输出, 用:
OUTPUT OFF;
语句。 恢复用“OUTPUT ON”语句。
Gauss系统有很好的图形功能, 可以绘制印刷质量的图形, 可以直接打印? ? 或存为HP-GL格式文件。 可以精确规定图形区域大小? ? 可以分窗口显示。 在使用绘图过程之前要加两个语句:
library pgraph;
graphset;
为了画连线图, 使用
XY(x,y);
例如
x = seqa(0,1,101)*2*pi/100;
y = (sin(x)+1)^2;
xy(x,y);
图形函数包括:
一、一般函数
ABS SQRT EXP LN(自然对数) LOG(x)(常用对数)
PI SIN COS TAN ARCSIN ARCCOS ATAN ATAN2 SINH COSH TANH
BESSELJ(第一类Bessel函数) BESSSELY(第二类Bessel函数) GAMMA LNFACT(X)=LN(X!)
二、微积分
GRADP=![]() HESSP=
HESSP=![]() INTGRAT2=
INTGRAT2=![]()
INTGRAT3=![]()
INTQUAD2=![]() INTQUAD3=
INTQUAD3=![]()
INTSIMP (用Simpson方法积分)
三、线性代数
1. 特征值分解
EIGCG EIGCG2 EIGCH EIGCH2 EIGRG EIGRG2 EIGRS EIGRS2
其中字母C代表复数, R代表实数, G表示通用, H表示Hermitian, S表示对称, 2表示加算特征向量。
2. 矩阵分解
CHOL:Cholesky 分解, 对正定阵x>0分解x=y'y, y为上三角阵
CROUT, CROUTP:A=LU, L为上三角, U为下三角且主对角线元素都为1
QR, QR1, QR2:A=QR, Q正交(酉), R为非奇异上三角
SVD, SVD1, SVD2:奇异值分解
NULL, NULL1, ORTH, ORTHGS:正交基计算
INV, INVPD(用于对称正定阵):求逆
SOLPD:解Ax=b, A>0
/:解线性方程组或求最小二乘
DET, DETL(已进行矩阵分解后用), COND:行列式, 条件数
四、多项式运算
POLYROOT:求复根
POLYEVAL:计算多项式的函数值
POLYMAKE:根据多项式的实根求系数
POLYMULT:多项式乘法
POLYINT:多项式差值
POLYMAT:返回各阶幂次的值
POLYCHAR:特征多项式
五、Fourier变换
CFFT, CFFTI, DCFFT, DCFFTI, FFT, FFTI:带I表示反变换, 带C表示复数序列输入, 带D表示不用快速Fourier变换。
六、复数运算
COMPLEX, COMPLEX2:实型转复型
REAL, IMAG:取实部、虚部
CMTRANS:共轭转置
CMADD, CMSUB, CMMULT, CMDIV:复矩阵加减乘除
CMINV:复矩阵求逆
CMSOLN:解复线性方程组
七、统计函数
MEANC, MEDIAN, STDC:列均值、中位数、标准差
MOMENT,VCX, VCM, CORRM, CORRVC, CORRX:计算矩阵的叉积阵、协方差阵、相关阵
MOMENTD, OLS, OLSQR, OLSQR2:计算数据集的回归
八、统计分布
CDFN(正态), CDFNC(正态上侧), CDFBVN(二维正态), CDFTVN(三维正态)
PDFN(标准正态密度),
ERF(为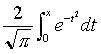 ),
ERFC(=1-ERF)
),
ERFC(=1-ERF)
CDFTC(t上侧),
CDFTNC(非中心t),
CDFCHIC(![]() 上侧),
CDFCHINC(非中心
上侧),
CDFCHINC(非中心![]() )
)
CDFFC(F上侧), CDFFNC(非中心F)
CDFGAM, CDFBETA:Gamma分布和Beta分布函数
九、序列
SEQA(算术级数), SEQM(几何级数)
RECSERCP(有乘运算的递归序列), RECSERRC(有除运算的递归序列)
RECSERAR(自回归递归序列),
十、精度控制
BASE10(科学科学记数法), CEIL, FLOOR, ROUND, TRUNC, PRCSN
一、矩阵生成
EDITM(矩阵键盘录入), LET(矩阵赋值)
EYE(单位阵), ONES(全1矩阵), ZEROS(全零矩阵)
二、读/写矩阵
LOADD(读入数据集), LOAD或LOADM(读入文本文件或矩阵文件中数据)
SAVE(保存矩阵、过程等), SAVED(存入数据集)
三、大小、序、范围
ROWS, COLS 求矩阵行数、列数
ROWSF, COLSF 求打开的数据集的行、列数
MAXC, MAXINDC, MINC, MININDC 每列最大值, 最大值所在行号, 最小值及所在行
SUMC, PRODC 列的和、积
CUMSUMC, CUMPRODC 列的累加、累乘
RANKINDX 向量排序的秩得分向量
COUNTS 向量落入各区间的频数
COUNTWTS 带权重的频数
INDEXCAT 向量值落入某区间的下标集合
四、其他矩阵操作
SUBMAT 按行、列取出子矩阵 RESHAPE 有已有矩阵产生形状(行、列数)不同的矩阵
DELIF 有条件地删去矩阵的某些行 SELIF 有条件地保留行 TRIMR 去掉矩阵顶、底的若干行 EXCTSMPL 产生数据集的有放回的随机子样
VEC 矩阵按列拉直 VECR 矩阵按行拉直 VECH 对称阵上三角的行拉直 XPND 向量还原成对称阵 DIAG 取矩阵主对角线 DIAGRV 替换矩阵主对角线
LOWMAT, UPMAT, LOWMAT1, UPMAT1 从矩阵中取出下/上三角阵(其它处填0), 带1时主对角线置1
UNION 向量并(两向量中元素的并集) INTERSECT 交集 SETDIF 差集
REV 矩阵行次序颠倒 ROTATER 行中元素推移排列(旋转) SHIFTR 行元素左右平移并以规定值填充空出的位置
一、数据集
LOADD 读入小的数据集 SAVED 存小的数据集 用ATOG.EXE程序转换大的数据文件
CREATE 生成并打开数据集 OPEN 打开已有数据集 READR 读入一些行 WRITER 写出一些行 SEEKR 定位于数据集某行 EOF 判断是否数据集末尾 TYPEF 判断数据集数据类型(2, 4或8字节) CLOSE, CLOSEALL 关闭数据集
二、数据集的变量名
GETNAME 找到数据集中所有变量(列)的名字 INDICES 数据集的列号与变量名互求 INDICES2 类似INDICES但区分自变量与因变量 VARTYPPE 由变量名决定数值型(1)还是字符型(0), 数值型变量用大写名字, 字符型变量用小写名字
SETVARS 把数据集中所有变量名引入并赋标量零 MAKEVARS 从数据集中取出列成为向量 MERGEVARS 把列向量并成大的矩阵
INDCV 从某字符向量找出某些短字符串的位置(下标) INDNV 从数值型向量中找出某些数的位置
三、数据变换
CODE 按一系列判断条件把向量内的数据离散化(变成分级数据) RECODE 类似CODE, 但若每一条件都不满足时原数据值不变 SUBSCAT 用上升的分组区间来离散化向量的值 SUBSTUTE 与RECODE类似但对矩阵进行
ISMISS 判断一个矩阵内有无缺失值 SCALMISS 判断一标量是否取缺失值 MISS 把给定值换成缺失值 MISSRV 把缺失值换成给定值 MISSEX 按判断条件决定缺失值 PACKR 删除包含缺失值的行 MSYM 确定缺失值的打印符号
DUMMY, DUMMYBR, DUMMYDN 由整值列向量生成0-1设计阵, 每个数对应1所在的列号
四、排序与合并
SORTC 矩阵按数值列排序 SORTHC 堆法排序 SORTIND 按数值向量排序后的序号向量
SSORTCC, SORTHCC 矩阵按字符列排序 SORTINDC 字符向量的排序序号向量
SORTMC 矩阵按多个列排序(数字、字符型)
UNIQUE 从向量中删除重复项 UNIQINDX 向量排序后无重复的序号, 数值型、字符型均可
INTRLEAVE 两个小的按同一变量排好序的数据集行交叠地组成大的有序数据集
MERGEBY 两个小的有同一变量且按此变量排好序的数据集行并接得到的大的数据集
一、开始及结束
END, PAUSE(暂停指定的时间), RUN, STOP, SYSTEM(退出到DOS) END(停止运行并关闭所有打开的文件, STOP不关闭)
二、分支
IF … ELSEIF … ELSE … ENDIF
GOTO, POP(弹出GOTO的变量)
三、循环
DO WHILE … ENDO
DO UNTIL … ENDO
BREAK, CONTINUE
四、子程序
GOSUB, POP(弹出GOSUB的参数), RETURN
五、过程
PROC, LOCAL, RETP, ENDP
六、库
LIBRARY(列出活动库文件表) DECLARE(编译时初始化变量) EXTERNAL(外部符号引用说明) CALL(调用, 不要函数值)
七、编译
COMPILE, SAVEALL, USE(调入已编译过的代码), SAVE(存编译的过程), LOADP(调入编译的过程)
八、其它编程语言的使用
LOADEXE 调入其它编程语言代码(可执行) CALLEXE 调入其它编程语言的函数
DOS(暂入DOS) EXIT FILES(给定目录下的文件) CDIR(查询当前目录名) EXEC(执行一个可执行文件) DFREE(查询磁盘剩余空间) ENVGET(返回DOS的环境变量)
CLEAR(X= (0)) CLEARG(清全局符号, 赋(0)) NEW(清当前工作空间) DELETE(删除指定的全局符号) SHOW(显示全局符号表) CORELEFT(查询剩余工作空间) TYPE(变量类型) TYPEPCV(符号名是字符串、矩阵、过程还是函数)
ERRORLOG(显示并存出错信息到文件) TRACE(跟踪调试) #LINESON, #LINESOFF 行号信息开/关 ERROR DISABLE ENABLE TRAP SCALERR TRAPCHK NDPCNTRL NDPCHK NDPCLEX
STRLEN(串长) STRSECT(取子串) STRINDX(查找子串出现位置) LOWER, UPPER(变大、小写)
CHRS, VALS(字符串与码值转换)
FTOS, STOF(浮点数标量与显示字符串间转换)
FTOCV(数值矩阵变字符矩阵)
GETF(把文本或二进制文件调入一字符串) PUTF(把字符串写入磁盘文件) LOADS(调入.FST字符串文件)
VARGET(把字符串变成全局变量名) VARPUT(给名字保存在一个字符串中的全局变量赋值)
HSEC(从午夜起过的时间, 单位是百分之一秒) DATE(4×1阵:年、月、日、百分之一秒时间) DATESTR(mm/dd/yy形式的日期) DAYINYR(年中的第几天) ETDAYS(两日期相隔天数) TIME(4×1阵:时、分、秒、百分之一秒) TIMESTR(把时间变成hh:mm:ss的显示格式) ETHSEC(两日期时间之间的百分之一秒数) ETSR(把时间差变成“n days n hours n minutes n.nn seconds”字符串)
CON(输入数值矩阵) CONS(输入字符串) KEY(键盘缓冲区下一字符的ASCII码值) WAIT(等待敲一键) WAITC(清缓冲后等待敲一键)
FORMAT 控制显示/打印格式
COMLOG 选命令记录文件及开/关
OUTPUT 选辅助输出文件及开/关
SCREEN OF|OFF 屏幕输出开/关
PRINT ON | OFF 赋值时自动显示新值的开/关
LPRINT ON | OFF 赋值时自动打印新值的开/关
PRINT 显示, 在OUTPUT开时还写文件
LPRINT 打印
OUTWIDTH, LPWIDTH 行宽
LPOS 打印头位 LSHOW 打印符号表
PRINTDOS 向DOS标准输出显示 PLOT 字符型绘图 PLOTSYM 符号控制 CLS 清屏 SCROLL 翻卷 LOCATE 光标定位 CSRLIN, CSRCOL 查询光标行、列号
EDIT 打开Gauss的编辑器 ED 打开用户指定的编辑器
GRAPH 直接设置象素点 SETVMODE 设置图形模式 COLOR 设颜色 LINE 画线